
About the Mod: Part One
There are many module file types, including the MOD, IT, S3M/STM, XM, MED and 669 formats. The original MOD format was used by ProTracker, one of the first trackers (mod composition software) for the Amiga. Many of the mod filename extensions indicate their origins on a particular tracker: the IT format comes from the Impulse Tracker, S3M/STM is from the ScreamTracker, MED is from the OctaMED tracker and so forth. The various formats differ in the number of tracks allowed, the number of samples supported and the permissible bit resolution of the samples. Fortunately for Linux users, the most popular formats (MOD, XM, and IT) are supported by the available trackers and players.
It should be noted that although trackers load and save modules in only one or two formats, mod players typically support a wide variety of file types. For example, the popular MikMod player, included in almost every mainstream Linux distribution, handles at least fifteen module formats, and the MODPlug plug-in for the excellent XMMS player supports more than twenty mod file types.
A mod tracker is an application for composing music with only your computer and some sampled sounds. The basic design of a tracker is similar to a MIDI pattern sequencer. A pattern is defined by a number of beats that act as slots in which you place (track) your samples. Each beat includes information about the musical pitch for your sample, its instrument number and volume setting, and optional effects such as vibrato, filters and panning. Patterns are strung together in arbitrary sequences to create a song. The song is then saved in one or more (depending on the tracker) of the various mod formats.
Mod trackers first appeared on Amiga computers. Those machines enjoyed on-board sound support capable of handling up to four channels of 8-bit monaural sampled sound. With the advent of decent affordable PC soundcards, MS-DOS became the next platform of choice for module composers. Today excellent trackers are available for Windows, the Mac and, of course, Linux.
Trackers are especially well suited for making beat-oriented music such as pop/rock, techno and other dance styles, but because any kind of sample can be used the software is certainly not limited to any particular musical style. Check the MOD Archive, MODPlug Central and the United Trackers web sites listed at the end of this article for links to mod collections showing off the wide range of music made with trackers.
A tracker resembles a looping pattern MIDI sequencer. A series of beats or measures defines the loop period, events are placed on beats within the looping pattern, and there is some degree of fine control over the individual event. An event here means any sound file: events can be as simple as a single beat of a kick drum or as complex as an entire drum pattern or violin solo.
A MIDI file is very small compared to a mod, but it contains no sample data and must rely on a soundcard or external synthesizer to process its sounds and effects. A mod file includes sound sample data along with the sequence timing information and is accordingly much larger than a MIDI file.
The General MIDI (GM) patch map provides a specification for a common layout of sounds for all soundcards. However, cards from different manufacturers may fill their GM patch maps with samples of dramatically differing quality. Because a module contains sample data, a mod can be played on any computer with any soundcard, and listeners will hear your music played with exactly the same sounds that you used to compose it.
By now you might be thinking “So why use MIDI at all?” There are some very good reasons: MIDI sequencers are more highly evolved composition tools, with more possible connections to external hardware and auxiliary software utilities; file sizes may be a consideration, particularly if transmitted across low-bandwidth network lines; and the MIDI Manufacturers Association provides an industry-standard specification with a focused set of definitions of MIDI's capabilities.
By contrast the mod scene seems more chaotic. Many trackers have devised their own file types, which has led to a rather bewildering profusion of formats, and there is no governing body to help determine the organized definition and expansion of module capabilities. However, if you want to compose using sampled sounds, if you want listeners to hear your music with exactly the same sounds as you composed it, and if you can live with a rather “middleweight” file format, then module tracking may be just what you're looking for.
Fortunately the situation is not an either/or scenario. Programmer Guy Thornley has written a useful little program called GMid2Mod that converts a standard MIDI file (preferably with a General MIDI patch map) to an XM format module, employing the default Gravis Ultrasound samples used by the TiMidity MIDI player. Using GMid2Mod I converted a four-channel MIDI file (with four GM instruments) to an XM-format mod. I used the MikMod player to convert the module to a CD-quality (44.1KHz, 16-bit) stereo WAV file, and I then used BladeEnc MP3 encoder to convert the WAV to an MP3 file with a bitrate of 128KBps.
As the following comparison of the file sizes indicates, it makes better sense for the composer of mods to distribute works in the original module format:
Interlude.mid 34KB Interlude.xm 737KB Interlude.wav 28MB Interlude.mp3 2.5MB
Another advantage shared by MIDI and mod files (over the WAV and MP3 formats) is the ease with which they can be studied, viewed and/or rearranged in compatible composition software. For example an XM module can be loaded into any tracker with XM support, just as a standard MIDI file can be loaded into any MIDI sequencer that supports the Standard MIDI File format. Compositions and performances in the WAV and MP3 formats are not easily rearranged or dismantled into their constituent instruments.
Incidentally, if you want to head in the other direction, Kokai Istvan has written Xm2Mid, a utility for converting XM-format mods to standard MIDI files with a GM patch layout. It works best if your module is arranged using an instrument set identical to the GM patch map.
As of August 2000 I counted 13 trackers listed on the Linux Sound & Music Applications site. Which one(s) you prefer to try will depend on your available resources, particularly your graphics capabilities, as well as your interest in developing a tracker. For X users, Michael Krause's SoundTracker (see Figure 1) is designed with an excellent GTK interface graphics, while Cedric Roux's powerful Xsoundtrack (see Figure 2) uses common Xlib graphics. Jason Nunn's FunktrackerGOLD (see Figure 3) is an excellent console-based tracker requiring only the ncurses library for its graphics.
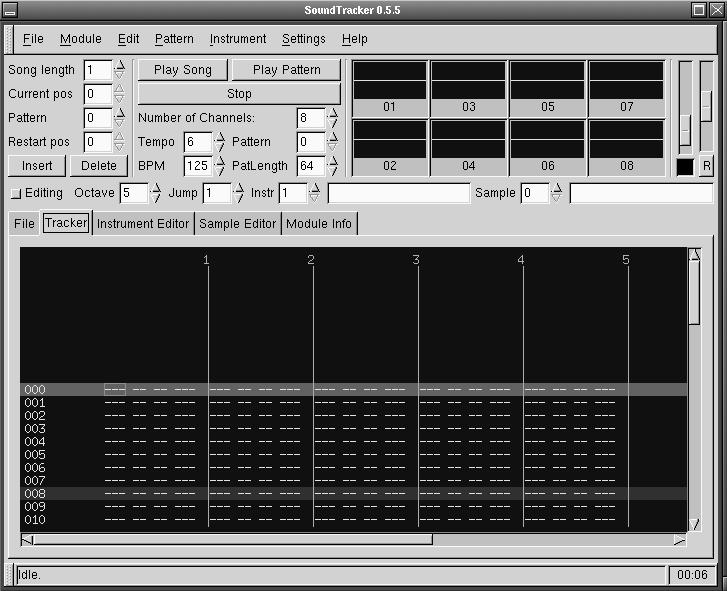
Figure 1. SoundTracker

Figure 2. Xsoundtrack
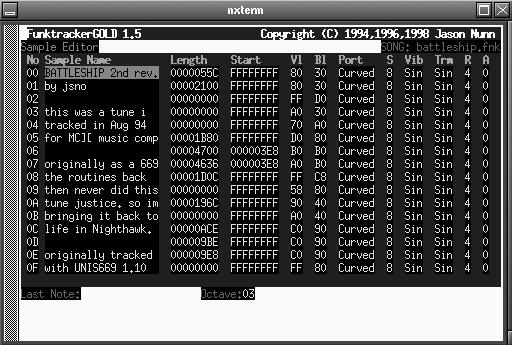
Figure 3. FunktrackerGOLD
Those three trackers have been developed to a stable and usable status. Other Linux trackers include the Sarah Tracker, Stupid Tracker [sic], and ocsatracker for the Linux console and the Industrial Tracker, the Rapid Audio Tracker, and Insotracker for X displays. All of this software is in various stages of development.
Tracker-style interfaces also appear in music software that does not create modules. Juan Linietsky's unique Shake Tracker (see Figure 4) combines the module tracking interface with MIDI output. If your soundcard includes a hardware synthesizer with SoundFont (sf2) support you can use its sound banks directly. Shake Tracker has just begun its development course, but it is already usable, and the author welcomes feedback and suggestions from users.
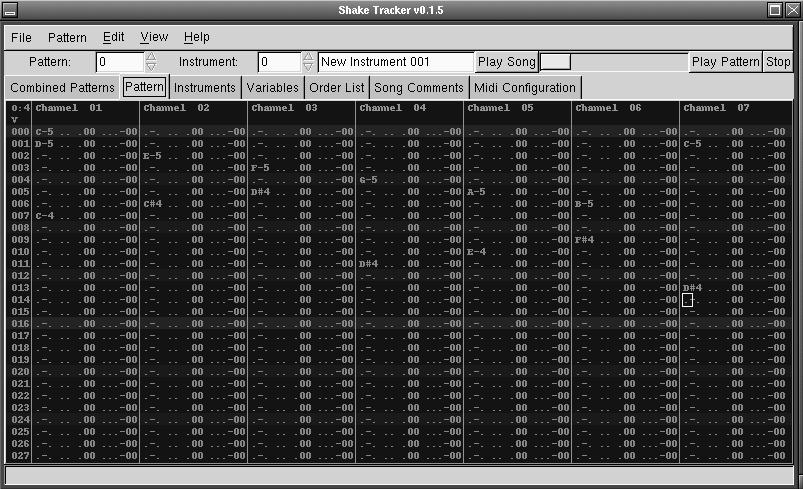
Figure 4. Shake Tracker
Tim Janik and Olaf Hoehmann have created the BEAST/BSE system which is an ambitious project that combines an audio synthesis network with a tracker's composition interface (see Figure 5). Currently, files are saved in the BSE format and are not compatible with mod trackers and players. Like Shake Tracker, BEAST/BSE is in early development, but it works and is already quite impressive.
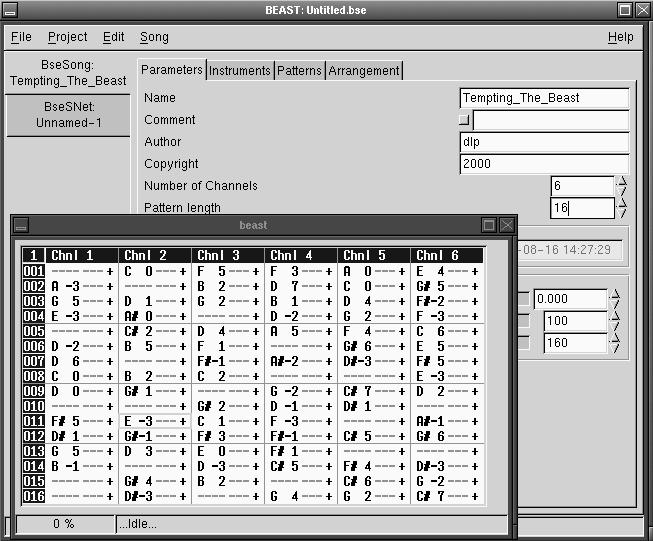
Figure 5. BEAST/BSE Pattern Editor
David O'Toole's GNU-OCTAL project plans to be the Linux equivalent of the Buzz tracker for Windows. Buzz differs from other trackers because it includes generators for sound synthesis, thus eliminating the need for a separate sample library. GNU-OCTAL is similarly designed, and although still in early development, the project is definitely worth watching (or joining: remember, this is Linux, where you too can get involved in the exciting world of audio software development!).
Mod players for Linux are also available in console and X interfaces. As noted earlier, almost every Linux distribution includes MikMod (see Figure 7), which is available in various incarnations (e.g., console, GTK, Qt, Xforms, and Java). The popular MODPlug player for Windows has been ported as a plug-in for the excellent XMMS player (see Figure 6) and is also the playback engine for Gmodplay.
Figure 6. MikMod in Console Mode
Figure 7. XMMS With MODPlug Configuration Options
Table 1 lists the available Linux trackers, Table 2 lists the players. The status ratings indicate the program's level of usability. The higher the number of stars, the more complete the application. Devel indicates that the application is at the alpha or early beta development stage. Entries marked with ? indicate that I was unable to build and/or run the application.
See the Linux Sound & Music Applications site at sound.condorow.net/mod.html for a current list of these and other Linux mod trackers and players.
Some of the popular mod trackers and players for Windows and MS-DOS may also run under WINE, VMWare, or DOSemu, but I haven't yet experimented with them. If you do try some mod software in those emulation environments please let me know how well they perform.
A demonstration program shows off neat graphics and animation hacks which are often accompanied by a musical score. The music is usually in a mod (or MIDI) format played by an embedded player (MikMod's libmikmod is very handy for playing mods in Linux demos). I highly recommend seeing the outstanding Loop, at mustec.bgsu.edu/pub/linux (binaries and sources are also available there), and State Of Mind, at skal.planet-d.net/mind/index.html. Both of those demos use an embedded libmikmod to play their scores.
The United Trackers and MODPlug Central sites are excellent guides to finding trackers and players, sample archives, links to mod collections, and tracking tutorials. The MOD Archive lists an enormous number of mods for your enjoyment and study. You might also want to keep up with the alt.binaries.sounds.mods and alt.music.mods newsgroups, where many independent musicians post their creations, questions, and information regarding the very active mod tracking scene. (See Resources)
In the next issue we'll take a look at SoundTracker.


