
Linux Finance Programs Review
As Linux finds its way onto more and more computers, the need for a broader range of applications increases. One popular request is a Quicken-like program for managing finances. There are several financial programs available for use on Linux, and I present some of them in this article. The programs covered are cbb, QHacc, GnuCash, Moneydance and gAcc.
All of these programs can keep track of basic financial information such as checking and savings accounts. Almost all of them also offer some type of reporting and graphing functions. Most of them can import files saved in the QIF format with varying degrees of success.
Most of these programs are not up to version 1.0 yet, and lack some features and polish. The authors are busy improving them and adding functionality, so, while there is not an exact replacement for Quicken or Money, you might find one of these programs to be suitable for you.
I installed cbb version 0.8.1 for this article. Written entirely in Tcl/Tk and Perl, installation was accomplished by simply typing make install. cbb contains no compiled code, so it should run on the majority of Linux systems.
cbb keeps account information in individual files, one .cbb file for each account. A list of accounts and their current balances is displayed at the bottom of the screen, and the account's entries are shown when you select it (see Figure 1).
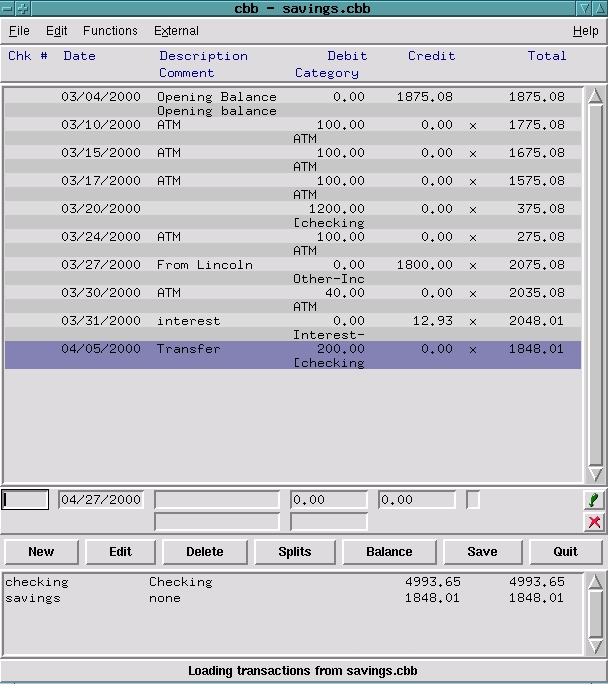
Figure 1. cbb
Entering transactions in cbb is straightforward. The transaction fields are between the ledger and the account list. You enter the particulars of a transaction, such as date, amount and category, then press ENTER or click on the “Accept” button to add it to the ledger. cbb allows you to easily change the current check number via the “+” and “-” keys, and includes a tab-completion feature for the payee and category fields.
Data entry is made simpler by the use of keyboard shortcuts, the ability to tab through all the fields and the ability to accept a transaction simply by pressing the ENTER key. If you enter a lot of transactions, you will find these features very useful.
While you can use categories to group your transactions, cbb does not allow you to specify whether a category is an expense or an income, and you cannot create sub-categories. A workaround for sub-categories is to use a naming convention such as Utilities, Utilities-electric and Utilities-gas. cbb can display the category list while editing transactions so that you can select the category you want.
cbb offers the following reports: transactions, transaction list by category, uncleared transactions, missing checks, average monthly expenses by category and transactions listed by payee. Graphs are available showing running balances, movements by categories, expenses by categories, expenses pie chart and categories by description pie chart. You can specify beginning and ending dates for reports and graphs and select the accounts to include.
Account reconciliation is accomplished by clicking on the “balance” button. Before doing this, however, you must enter any interest or service charges. When the balance window is displayed, enter the beginning and ending balances from your bank statement and start clearing transactions. If you notice a mistake, you can fix it in the ledger without closing the reconciliation window.
cbb allows you to import QIF files, so that you are able to use your existing data. Unfortunately, the import function did not work correctly on the QIF file I created in Quicken 99. While I did get transactions, there were no dates for them, and I could not edit them after I imported them. There were also some lines at the beginning of my ledger that contained data cbb apparently could not decode from the QIF file.
cbb is a good program for keeping track of checking and savings accounts. It allows you to enter transactions quickly and easily with the use of keyboard shortcuts. The reports and graphs provide useful information, and the ease of installation is a real bonus.
Moneydance is a shareware program written in Java. Of all the programs reviewed here, it is the most Quicken-like in appearance (see Figure 2), and it did the best job of importing my QIF files. I used Moneydance 2.0.4.

Figure 2. Moneydance
Installing Moneydance is very easy: simply unpack the tar package and modify the Moneydance file so that it points to the required .jar files. Then, place it where it can be found in your path (e.g., /usr/local/bin) and you are ready to go. If you are using an older Linux distribution, you might need to upgrade your Java environment.
Each transaction in Moneydance must contain a source account and a destination account. This is called double-entry accounting. Each type of income (e.g., salary) and expense (e.g., mortgage, fuel, credit card) appears on the chart of accounts, and all transactions are really transfers between accounts. For example, when you pay the electric bill, you transfer the money from your checking account to your Utilities:Electric account.
Moneydance provides a useful auto-completion feature which completes the payee name and displays the amount and accounts that you previously entered for that payee. Navigation through the ledger fields is easily done using the TAB key. When entering check numbers, you can either type the number or use the mouse to select actions such as “Next Check #” or “Print”. When you are done with the transaction, save it to the ledger by pressing CTRL-R or by clicking on the “Record” button. If you have to enter many transactions, you might find it a bit tedious to use the mouse for the check numbers plus two keys or the mouse to record each transaction.
Account reconciliation is done by selecting “Reconcile” from the Actions menu. You can add, edit and delete transactions from the reconciliation window.
Moneydance provides both reports and graphs. There are reports for transactions, account balances, income and expenses. You can customize a report by selecting beginning and ending dates, a specific account and the method of sub-totaling. Printed reports look sharp and contain titles and date ranges across the top of the page. You can graph the following information: Income, Expenses, Income and Expenses, and Account Balances. I could not get the graphs to print on my system for some reason.
You can print checks from Moneydance by selecting “Print” for the check number, then selecting “Print Checks” from the Actions menu. Moneydance supports standard checks and checks with stubs and allows you to print test checks to calibrate your system.
Another nice feature is the ability to search for transactions. Selecting “Find Transaction” from the Actions menu or pressing CTRL-F brings up the Find window. You can search for a specific Payee/Description, Memo or Check #. Selecting “Find Again” or pressing CTRL-G allows you to find the next matching transaction.
If you are used to Quicken, you will find Moneydance very easy to use. The only problems I found with it were minor ones. The help file does not provide much information, but it does cover basic account editing and double-entry accounting. On my machine, Moneydance ran somewhat sluggishly, but I think this is due to the fact that I am running an older version of Java on a slow Pentium.
The next program is QHacc version 0.4.3. (Note: QHacc's authors have released version 0.5, but too late for me to include in this article.) This program requires the QT toolkit in order to work, which I found to be quite an easy installation process. I compiled the QT toolkit from sources and followed the instructions for installing it, then I compiled and installed QHacc without incident.
QHacc provides a simple two-paned layout. The left pane contains a list of accounts and balances, and the right pane contains the ledger for the selected account (see Figure 3).
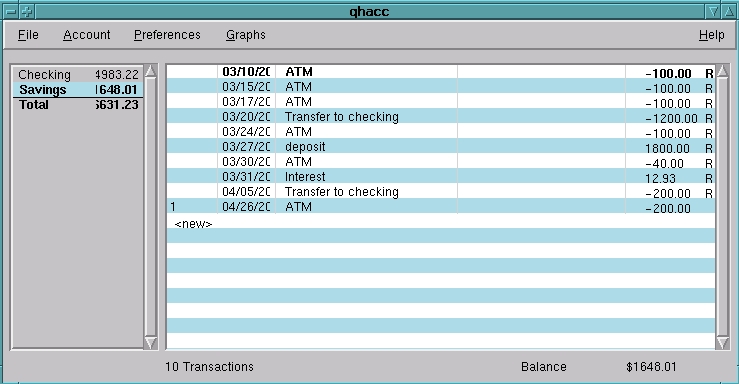
Figure 3. QHacc
Transaction entry is a little different from the other programs. Selecting “new” in the ledger brings up a transaction window where you enter the check number, date, payee, amount and memo. QHacc inserts the next available check number and provides an auto-complete feature for the payee. The transaction is entered into the ledger by pressing the ENTER key, while pressing the ESC key cancels it. Withdrawals must be preceded by a minus sign, because QHacc does not provide separate credit and debit text boxes.
QHacc also provides a mechanism for memorizing transactions. After entering the transaction that you want to memorize, right-click on it in the ledger and select “Memorize” from the pop-up menu. To insert a memorized transaction, right-click on an empty ledger line, go to the memorized item in the pop-up menu and select the transaction you wish to insert.
QHacc can be set up for single- or double-entry bookkeeping. If you want to use categories for keeping track of your transactions, you must use double-entry bookkeeping. You must also use double-entry accounting to automatically update account balances when transferring money between them, otherwise you have to enter the transfer in both accounts. If you elect to use double-entry bookkeeping, you can also split a transaction among several accounts.
QHacc provides a simple graphing function that shows the net total of transactions by the week. According to the companion TODO document, more graphs will be added in the future.
Account reconciliation is the same as in the other programs. Remember to enter any interest payments or service charges before using it. Enter the starting and ending balances from your bank statement, then select entries to clear.
At version 0.4.3, QHacc is the youngest of the programs at which I looked. I did find one problem. If I entered 00 for the year, it used 1900. Also, QHacc does not offer the ability to import QIF files.
GnuCash is the most ambitious financial program being developed at this time. It offers the greatest variety of account types, sub-accounts and stock price retrieval. This program was the most difficult to compile and get working because it depends on quite a few other programs, libraries and Perl modules. I looked at both the stable version (1.2.5) and the current development version (1.3.6).
Before attempting to use either of these versions, read the documentation closely to determine which additional programs, libraries and Perl modules you will require. Version 1.2.5 requires Motif or LessTif and version 1.3.6 uses GNOME and the GTK. I had better luck installing them on a Red Hat 6.1 system than I did on a SuSE 6.1 system.
GnuCash offers a slightly different interface than the other programs I tested. Its main window displays a list of accounts with balances, and a new ledger window is opened for each account. This allows you to view and edit more than one account at the same time (see Figure 4).
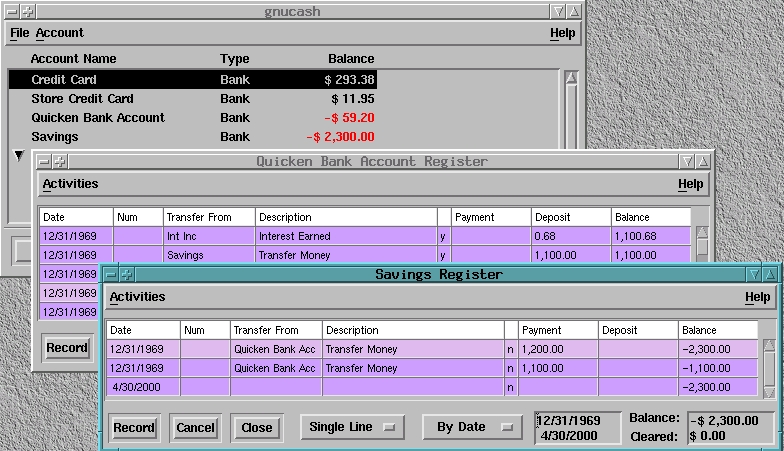
Figure 4. GnuCash: Multi-Account View and Edit
GnuCash offers more types of accounts than the other programs (see Figure 5). An account can be identified as a bank account, cash, asset, credit card, stock, liability, mutual fund, currency, income, expense or equity. Accounts can be children of other accounts, allowing you to create portfolios of funds. The ledger windows change slightly depending upon the type of account you are working with.
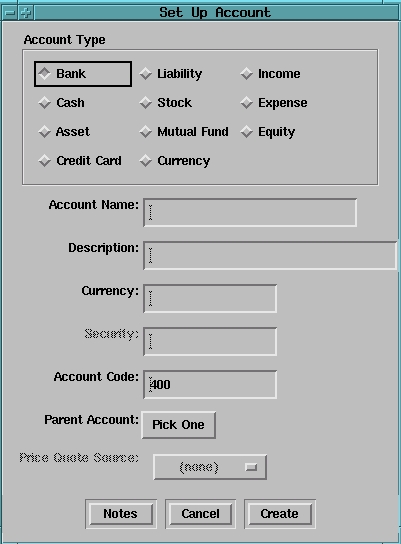
Figure 5. GnuCash: Account Types
The ledger windows offer you the choice of displaying single or multi-line entries and allowing you to sort transactions by date, check number, transaction amount, memo or description. Unfortunately, they do not remember your display selections after you close them.
Keyboard entry leaves a bit to be desired in version 1.2.5. While you can use the TAB key to move through the fields, in single-line mode you cannot tab over to the payment or deposit fields because the focus jumps from the account field to the “Record” button. Version 1.3.6 puts the command buttons above the ledger, fixes the tab movement function and accepts a transaction when you press the ENTER key. Neither version automatically increments check numbers in the ledger window.
I had some problems importing my QIF file from Quicken 99. GnuCash version 1.2.5 read my Quicken file and did a good job of creating my chart of accounts, but all the ledger entries from the QIF file had a date of 12/31/1969. Version 1.3.6 could not even read my QIF file, quitting with the message “wrong argument in position 1”.
GnuCash offers reports but no graphs at this time. The reports included in version 1.2.5 are Balance Sheet, Profit and Loss and Portfolio Valuation. Version 1.3.6 offers these reports plus additional ones, such as a budget report, but there is no way to create a budget from within GnuCash at this time.
While certainly the most ambitious program of the group, GnuCash was also the most difficult to install. The documentation does state which programs and libraries are required by GnuCash, and I had better luck installing GnuCash on a Red Hat 6.1 system than a SuSE 6.1 system. The dependence on so many external programs and the difficulty of importing QIF files are the main problems with GnuCash.
The final program I looked at was gAcc version 0.7.1. gAcc requires the GTK+ toolkit, version 1.2.2 or later, to be installed. I found it relatively easy to compile the sources and install this program, but I did have to copy a few files manually before it would run.
gAcc's layout is similar to that of GnuCash, with a main account list (see Figure 6) and separate ledger windows, but you can work with only one account at a time. gAcc is from Europe and offers better support for European dates and currency than the other programs I tested. You can set these options from the “Preferences” dialogs.
Figure 6. gAcc
Entering and editing transactions is not as user friendly in gAcc as it is in the other programs. There is no keyboard shortcut for adding new entries and no auto-complete feature for the payee. Categories, actions and accounts are available from a drop-down list so you do not have to remember them. One quirk with the transaction entry is you have to delete the “$” in the amount text box or $0 shows in the ledger, no matter what you enter.
gAcc handles only checking and savings accounts. You can create categories to keep track of your transactions. At this time, it does not offer any reports or graphs, but these features are listed in the TODO file to be added in later versions. There is also no ability to import QIF files.
I originally tried version 0.7 and ran into a few problems with the source tarfiles and the preferences dialog. I sent a note to the authors and received a prompt reply from them. Shortly after that, version 0.7.1 was released and the problems were fixed. This was a very pleasant experience and a tribute to the authors.
I found cbb a very simple program to install and use, but it is limited to simple finances. Moneydance is the most Quicken-like in appearance and it also did the best job of reading my QIF files, but it ran slowly on my system. QHacc offers the ability to work with checking and savings accounts without much overhead. GnuCash is the most difficult to install, but supports the greatest variety of accounts. gAcc handles European dates and currency symbols natively, but can also be set up for American symbols.
There is certainly no lack of financial programs available for Linux at this time. If you have simple finances and do not mind entering data by hand, one of these packages should work for you. If your financial needs are complex or you want to move away from an existing Quicken system, you have a more difficult choice. At this time, there is no exact Linux replacement for Quicken, but I am sure this is only temporary as these programs continue to mature and improve.
email: rkrause@netperson.net
Ralph Krause (rkrause@netperson.net) lives in southeastern Michigan and divides his time among computers, reading and taking care of four dogs. He has been using Linux for over a year.

