
AIPS and Linux: A Historical Reminiscence
It was a dark and stormy night. Well, maybe not—but there was plenty of inclement weather on a late fall day in 1993, in central Virginia. I was waiting with eager anticipation for the arrival of a third-year college student from Virginia Tech, who had some precious cargo in his possession: a working version of our flagship application, AIPS, that he had ported to a brand-new and relatively obscure operating system. He also brought something that would revolutionize the basis for computing at my workplace: a QIC-60 cartridge containing a very early, well-hacked and customized version of the SLS distribution of Linux. I believe it was based on kernel 0.99.12, although it could have been 0.99.11.
I work at the Headquarters of the National Radio Astronomy Observatory (NRAO) in Charlottesville, Virginia. Our mission is to provide world-class facilities for astronomers to observe the universe through radio waves. Despite what most people think, we don't listen to anything. Instead, we gather signals, grind them through some impressive hardware and software and end up with pictures of what the sky would look like if we could see in the radio part of the electromagnetic spectrum.
On that particular day in 1993, my main duty was systems programming and world-wide installation support for AIPS, the Astronomical Image Processing System. This is NRAO's main application for processing the signals from our telescopes. It is a combination of command-line interpreter, graphical image display and a large (300+) set of programs or “tasks” that perform more-specialized functions. These functions range from simple bookkeeping tasks to serious number-crunching algorithms such as deconvolution, maximum entropy, Fourier transforms and more.

Figure 1. The Very Large Array in its Most Compact Configuration
Established in the waning years of the 1950s, the National Radio Astronomy Observatory is a facility that now comprises telescopes at several widely scattered sites across the United States. Headquartered in Charlottesville, the main instruments it operates are the Very Large Array (VLA), located 50 miles west of Socorro, New Mexico; the Green Bank Telescope (GBT, due to be commissioned in August 2000) in West Virginia, and the Very Long Baseline Array (VLBA) which has ten large telescopes in locations ranging from Hawaii to New Hampshire, and Washington State to the U.S. Virgin Islands. Visitor centers are located in Green Bank and at the VLA. Anyone who has seen either the movie Contact or 2010 has seen the VLA; both those movies were shot partially on location out on the dusty plains of San Augustin at the VLA site. And no, there isn't a canyon next to the VLA; that was artistic license on the part of the Contact directors! The canyon is actually Canyon de Chelly in neighboring Arizona.
In addition, the NRAO is working with several European partners in a project to create another array, this time for higher-frequency (millimeter wavelength) radio waves. This venture will comprise 64 moderate-size movable telescopes to be located on a 15,000+ foot high plain called Atacama in the remote Chilean Andes mountains. Currently in the design phase, this Atacama Large Millimeter-wave Array (ALMA) promises to open more new frontiers in astronomy.
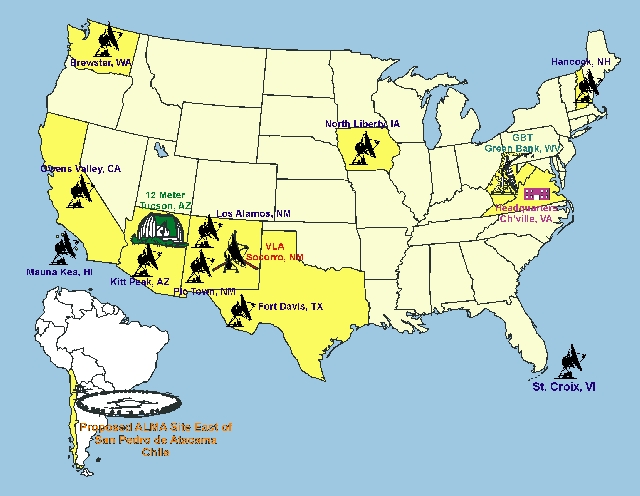
Figure 2. NRAO Facilities
As can be seen, we use arrays of radio telescopes in most of our instruments. Working together, they can give a much better picture than if they act alone. The technique used to correlate the signals from all the telescopes in an array is called Aperture Synthesis and is used at all our current arrays. This technique is the single most important raison d'etre for AIPS.

Figure 3. The Six Unique Baselines in a Four-Antenna Array
Without going into excessive technical detail, here's how aperture synthesis works. Several radio telescopes (antennae) are used, and the signals from each of them are captured, sent via wire or microwave “waveguide”, digitized and fed into a special-purpose computer known as the “correlator”. This one-of-a-kind computer takes the signals from each antenna and correlates them with all other signals. The result is a series of signals called “baselines”, as they represent the correlation of the signal from the ends of a baseline joining the two antennae. For a set of n antennae, you get nx(n-1)/2 baselines. If n is 4, for example, you get (4x3)/2 or 6 baselines (see Figure 3). You don't correlate an antenna with itself, and you don't count antenna.1-antenna.2 and antenna.2-antenna.1 baselines as separate.
When the signals are correlated like this, you end up with a set of “visibilities” that is almost like a Fourier transform of the signals as they arrive at each antenna. Basically, each baseline gives a point on the “U-V” plane, and gridding, interpolating and transforming the result can produce an actual image. The truly cool thing is that this image has the same resolution as if it were taken with a telescope the same width as the whole array. So the VLA in its “A” configuration, with over 15 miles separating the farthest-flung telescopes, is the equivalent of a 15-mile-diameter telescope. It gets better; with the VLBA, we've got the better part of the Earth's diameter between the antennae in Hawaii and St. Croix. As many of you may know, in astronomy it's diameter that counts when you want to “zoom in”. Instead of measuring angular distances in seconds of arc (the moon appears to be about 30 minutes of arc, or 1800 seconds of arc across), we measure things in milli-arc seconds with the VLBA.
AIPS is a package to support the reduction and analysis of data taken with radio telescopes. It is most useful for arrays of telescopes like the VLA and VLBA. In the past few years, it has also been used successfully for “Space VLBI” (very long baseline interferometry) in conjunction with a small telescope on a Japanese satellite (HALCA or VSOP).
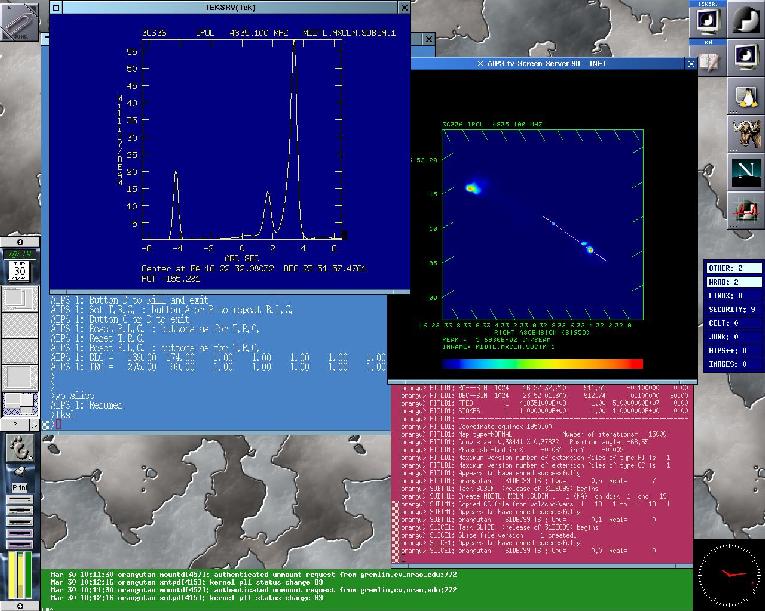
Figure 4. Screen Shot of a Typical AIPS Session
AIPS is what most of us would now describe as “legacy software”, having been originally coded in a truly ancient dialect of FORTRAN (predating even the venerable FORTRAN IV). AIPS now uses FORTRAN 77, although it has been digested successfully by at least one FORTRAN 90 compiler.
A Modcomp computer in Charlottesville was the first system to actually host a working AIPS system, and it quickly spread to a guest UNIX system hosted on an IBM 360 mainframe. From there, it spread in the early 1980s to VAX/VMS systems, often with an attached floating-point systems array processor (this peculiar device was the moral equivalent of the 80387 floating-point accelerators that some old-timers may remember being part and parcel of many 386 systems). In the late 1980s, UNIX came back into AIPS' universe in a big way, first with the Sun-3 series of Motorola-68020-based systems and then with a series of others, including Cray (Unicos), Convex and Alliant systems.
By the time the 80s were winding down, the dominance of VMS in the AIPS universe was being seriously questioned. Performance on new upstarts like Sun was starting to challenge their price/performance ratio, and the first SPARCstations totally blew them away. In the early 1990s, AIPS moved to a smorgasbord of UNIX variants: AIX, Stardent (briefly), Ultrix, HP-UX, SGI's Irix and DEC (oops, Compaq) OSF1. A port to an IBM 3090 was attempted, but failed due to accuracy problems with the non-IEEE floating-point format thereon. In the middle of this flurry of activity, the port to Linux by Jeff Uphoff was made.
In the fall of 1993, NRAO got a query from a radio astronomer at Virginia Tech in Blacksburg, requesting permission for one of his students to copy AIPS to his PC for an attempted port to a new system called Linux. (At that time, AIPS was still proprietary code, released to non-profit organizations under a rather cumbersome license and user agreement; this changed later.) Polite skepticism was the immediate reaction of most people then in the NRAO AIPS group, but we thought it would be an interesting exercise. We had been giving some thought to the issue of running AIPS on personal computers at the time, but had not pursued it.
A scant two weeks later, I received a technical support call from the same Jeff Uphoff, where he alluded to some difficulty in compiling one routine using f2c/gcc (remember, this was 1993, before g77 came to prominence). As it turned out, the problem was minor, and Jeff had successfully completed the whole port, even to the point of running the benchmark “Dirty Dozen Tasks” or DDT suite. This benchmark takes about an hour to run on a legacy SPARCstation 1 or SPARC IPX. On Jeff's poor little “uppieland” 386, it took over a day, but it ran to completion with acceptable accuracy results. We were equally impressed with his ability to print PostScript output on his little DeskJet 500 printer; our HP and QMS printers at the time all cost many thousands of dollars.
Needless to say, this feat and the contribution of the modifications necessary for Linux made a big impact at NRAO. Within a month, we had invited Jeff to visit and install a copy of Linux with AIPS running on it on a system in our lab. That was the dark and stormy evening referenced in the introduction above, and it saw both of us huddling over a (then state-of-the-art) Gateway 486/66 system, boot floppies in hand, busily preparing it for AIPS. Within a couple of hours, we had the system installed, looking for all intents and purposes like a Sun, even down to the Open Look window manager, and busily munching away on AIPS data. We benchmarked it at about half the speed of the Sparc IPX systems we had at the time. Seeing that the 486 cost a lot less than an IPX, this got our attention once more.
Within a few months of the original port, NRAO had Jeff Uphoff on its payroll, and the race was on to improve the performance of AIPS on Intel hardware. In the process, the NRAO Charlottesville Computing Division ended up with many Linux machines performing server duties, and several programmers and scientists volunteered for (in some cases, demanded) Linux desktop systems. The operating system was also spreading like wildfire on many of our home systems as an adjunct to, or in some cases a replacement for, that OS from Redmond.
However, it took the use of the EGCS version of the GNU g77 FORTRAN compiler to push the Intel/Linux platform to the forefront of the Radio Astronomy community. In 1995, using EGCS version 1.0.2, we (well, okay, it was Jeff again; why isn't he writing this article?) succeeded in getting AIPS to build under g77. This improved the AIPSMark (our benchmark, defined as 4000 divided by the elapsed time in seconds to run the DDT on our large dataset; bigger AIPSMarks are better and a Sparc IPX is 1.0) on a Pentium Pro 200 from 3.3 to about 5. With further coaxing via aggressive use of optimization parameters, the resulting AIPSMark went over 6. In this fell swoop, the price/performance curve that was previously occupied by Sun, IBM, DEC and HP was shattered once and for all. By 1998, NRAO was ordering Linux/Intel desktops as the workstation of preference for the scientist in place of SPARC Ultra systems. In 1999, Linux started to edge out the high-performance public workstations such as Alpha and high-end SPARC; our star performer in Charlottesville is a Pentium III Xeon 550MHz system with an AIPSMark of over 21. This is still not close to the stratospheric performance of top-of-the-line HP and Alpha systems (both around 34 AIPSMarks), but in price/performance terms, it's still a knockout.
During this time, another significant change came about. All this exposure to copylefted code was taking its toll on us. As mentioned earlier, AIPS was originally released under a restrictive user agreement that prohibited redistribution and was unpalatable or even unacceptable to some in our own astronomical community. Not only that, but the administrative costs associated with it were a burden.
Thus, several of us started a rather vigorous campaign to shift AIPS over to the GNU (Free Software Foundation's) General Public License on its next periodic release. There was virtually no opposition to the principle, and after a brief review by our business division, we were given the green light. Applying the three-paragraph copyleft statement to tens of thousands of files was no easy feat, but we managed to automate it. (Shell scripts and Perl scripts can do almost anything.) The distribution of AIPS took off at this point, and nowadays if you encounter a radio astronomer anywhere in the world, chances are she will have an AIPS CD-ROM somewhere or have it installed on her system.
In early 1998, as Jeff left for greener pastures (a formerly secretive company called Transmeta), there were two major obstacles left that stood in the way of total world domination by the Intel/Linux platform in the AIPS community. These were file locking on NFS-mounted file systems, and support for files larger than 2GB. With the advent of kernel-based NFS in version 2.2, the first issue is now moot. Jeff wrote the Linux statd, one of the two halves of the statd-lockd pair that governs all NFS file locks mostly at NRAO, partially at Transmeta.
As for the 2GB limit on file size, there is now hope on the horizon on that front, too. With SGI's promised release of their XFS code, it's likely that this journaled file system—which offers large file support in its original Irix environment—will smash this barrier. It should also provide a more robust file system, and hopefully one that won't take quite so long to fsck a 20GB partition.
Before he left, Jeff did contribute to the follow-up project to AIPS, called AIPS++. This large project, now coming to maturity, has fortunately followed in its parent's footsteps by adopting both the General Public License and Intel/Linux as one of its leading platforms.
If you who would like to get your hands on the software, point your browser at NRAO's main page and follow the link to “Software”. Be warned, though: it is not a small package, needs about 400MB of disk space, and has a non-trivial install procedure. It's also most useful if you want to analyze data from the VLA; if you want a simpler program, look at Bill Cotton's FITSView instead.
At many serious astronomy sites, you will find the dominant format of images and data to be FITS, the flexible image transport system. This format was invented around 1980 by a consortium of NRAO and other scientists so they could share data. The popular xv viewer supports the simpler versions of this format.

