
THOR: A Versatile Commodity Component of Supercomputer Development
The world's highest energy particle accelerator, the Large Hadron Collider (LHC), is presently being constructed at the European Center for Particle Physics Research (CERN) near Geneva, Switzerland. The planned date for first collisions is 2005. Since the demise of the US Superconducting Super Collider (SSC) in 1993, CERN has essentially become a world laboratory where American, African, European, Asian and Australian physicists work side by side. The LHC will penetrate deeper than ever into the microcosm to recreate the conditions prevailing in the universe just a millionth of a millionth of a second after the big bang when the temperature was ten-thousand-million-million degrees.
Our group is a small part of the team of approximately 1500 physicists, from over 100 institutions around the world, engaged in the construction of the ATLAS (A Toroidal LHC ApparatuS) experiment, one of two general-purpose detectors preparing to take data at the LHC. The experimental environment of ATLAS is punishing. For example, ATLAS has hundreds of thousands of detector channels and must keep up with a collision rate that can give rise to approximately 30 new events every 25 nanoseconds. Also, detectors and their accompanying electronics often must operate in high-radiation environments. It is obvious that the computing requirements in such an arena are, to say the least, demanding. CERN is no stranger to software developments required to solve the unique problems presented by international particle physics. For example, the World Wide Web was initially designed at CERN to help communication among the several hundred members scattered in numerous research institutes and universities.
The particle physicists in our group are involved in two areas which pose large computing problems. The first is in the area of time-critical computing, where the raw rate must be reduced from an event rate of around one gigahertz to about 100Hz by a three-stage, real-time data selection process called triggering. We are involved, along with groups from CERN, France, Italy and Switzerland, in the final stage of triggering, called the Event Filter, that reduces the data rate from 1GB/s to 100MB/s, fully reconstructs the data for the first time and writes the data to a storage medium. It is estimated that this last stage of processing would currently require on the order of a thousand “Pentiums”, if current trends in the development of processor speed continue.
We are also actively involved in simulating the response of the ATLAS detector to the physics processes that will be, or might be, present. This second task is not time-critical, but requires large simulation programs and often many hundreds of thousands of fully simulated events. Neither of these applications requires nodes to communicate during processing.
In order to pursue our research aims in these two areas, we had to develop a versatile system that could function as a real-time prototype of the ATLAS Event Filter and also be able to generate large amounts of Monte Carlo data for modeling and simulation. We needed a cost-effective solution that was scalable and modular, as well as compatible with existing technology and software. Also, because of the time scale of the project, we required a solution with a well-defined and economical upgrade path. These constraints led us inevitably toward a “Beowulf-type” commodity-component multiprocessor with a Linux operating system. The machine we finally developed was called THOR, in keeping with the Nordic nature of the names of similar-type systems such as NASA's Beowulf machine and LOKI at Los Alamos National Laboratory.
During our design discussions on THOR, it soon became clear to us that the benefits of scalability, modularity, cost-effectiveness, flexibility and access to a commercial upgrade path make the commodity-component multiprocessor an effective approach for providing high-performance computing for a myriad of scientific and commercial tasks—capable of being utilized for both time-critical and off-line data acquisition and analysis tasks. The combination of commodity Intel processors with conventional fast Ethernet and a high-speed network/back-plane fabric (Scalable Coherent Interface (SCI) from Dolphin Interconnect Solutions Inc.) enables the THOR machine to run as a cluster of serial processors, or as a fully parallel multiprocessor using MPI. It is also possible to rapidly reconfigure the THOR machine from a fully parallel mode to an all-serial mode, or for mixed parallel-serial use.
In order to demonstrate the basic ideas of the THOR project, a prototype has been constructed. A photograph of a slightly earlier incarnation of THOR is shown in Figure 1. This prototype at present consists of 42 dual Pentium II/III MHz machines (40 450MHz and 44 600MHz processors), each with 256MB of RAM. Each node is connected via a 100Mb/s Ethernet 48-way switch. A 450MHz dual Pentium II computer provides the gateway into the THOR prototype. The prototype has access to 150 gigabytes of disk space via a fast/wide SCSI interface and a 42-slot DDS2 tape robot capable of storing approximately half a terabyte of data. The THOR prototype currently runs under Red Hat Linux 6.1.

Figure 1. The THOR Commodity Component Multiprocessor
Sixteen of the 40 nodes have been connected into a two-dimensional 4x4 torus, using SCI, which allows a maximum bi-directional link speed of 800MB/s. We have measured the throughput of the SCI to be 91MB/s, which is close to the PCI bus maximum of 133MB/s. This maximum will rise when the 64-bit version of the SCI hardware, in conjunction with 64-bit PCI bus widths, are available. The use of SCI on THOR permits the classification of these THOR nodes as a Cache Coherent Non-Uniform Memory Access (CC-NUMA) architecture machine. This 16-node (32-processor) subdivision of the THOR prototype was implemented and tested as a fully parallel machine by a joint team from Dolphin Interconnect Solutions Inc. and THOR in the summer of 1999. A schematic diagram of the THOR Linux cluster is shown in Figure 2.
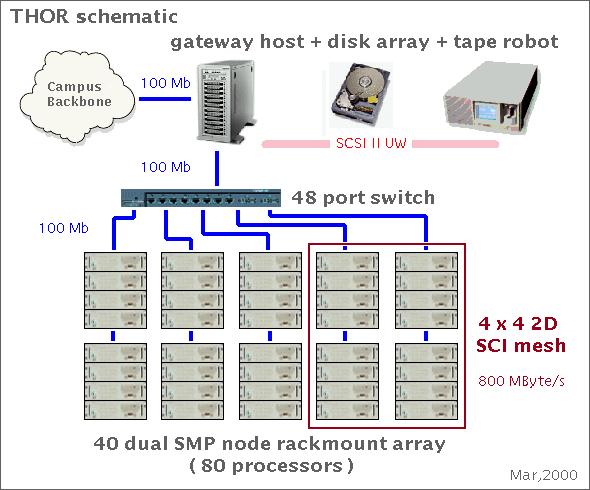
Figure 2. Schematic Diagram of the THOR Linux Cluster
The THOR prototype described above is now being benchmarked as a parallel and serial machine, as well as being used for active physics research. Researchers have access to full C, C++ and FORTRAN compilers, CERN and NAG numerical libraries and MPI parallel libraries for their research use. We also plan to acquire the recent Linux release of IRIS Explorer for THOR research use in the near future. PBS (a Portable Batch System developed at NASA) has been running on THOR since March, 1999.
We benchmarked the THOR prototype extensively, when it consisted of 20 450MHz dual Pentium IIs. This benchmarking used a variety of software. The first of two benchmark programs reported here was a three-dimensional Fast Fourier Transform (FFT) program written in FORTRAN using MPI. This software uses the THOR cluster as a parallel machine rather than a serial processor. As can be seen in Figure 3, the speed of a single THOR node using this FFT is comparable to a 450MHz Cray-T3E and the Calgary DEC Alpha cluster (in 1999) and is roughly 50% slower than an SGI Origin 2000 (R10K). As a fully parallel machine, one can see that THOR is competitive with the Calgary DEC Alpha cluster and with the Cray-T3E for this FFT procedure.
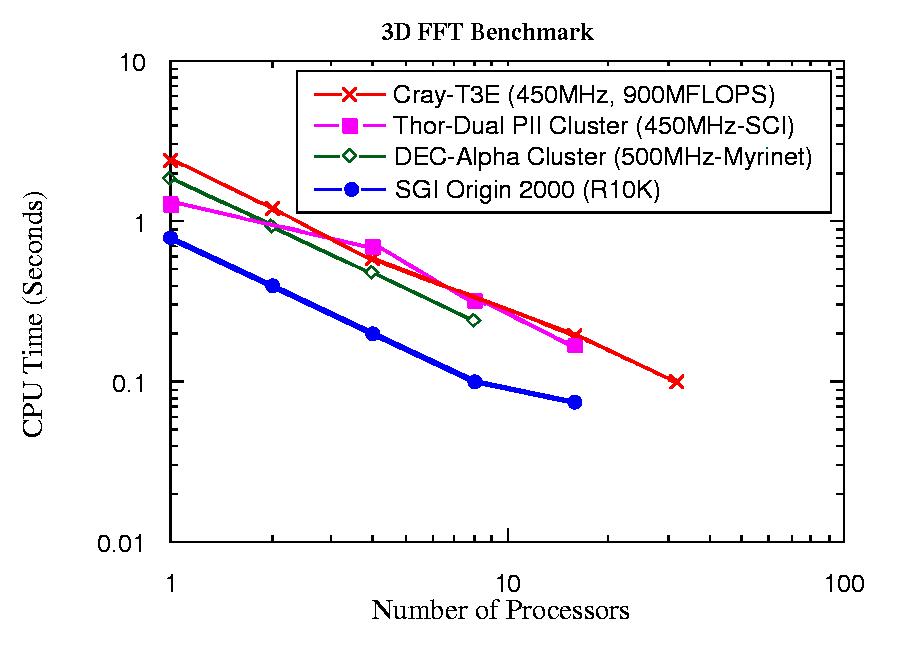
Figure 3. Benchmark Results from a 3-D Fast Fourier Transform Program
The second benchmark was obtained using the code developed to utilize the method of finite differences in the area of seismic modeling, and is written in C using MPI. In this case, the comparison was between the THOR multiprocessor using SCI interconnect, or 100 Mbp/s Ethernet and an SGI Origin 2000. The results are shown in Figure 4. As can be seen, the use of the SCI backplane/network fabric improves the performance of the THOR multiprocessor as compared to an Ethernet network solution. According to this benchmark, the performance of the THOR multiprocessor using SCI becomes comparable to that of the SGI Origin 2000 as the number of processors approaches sixteen.
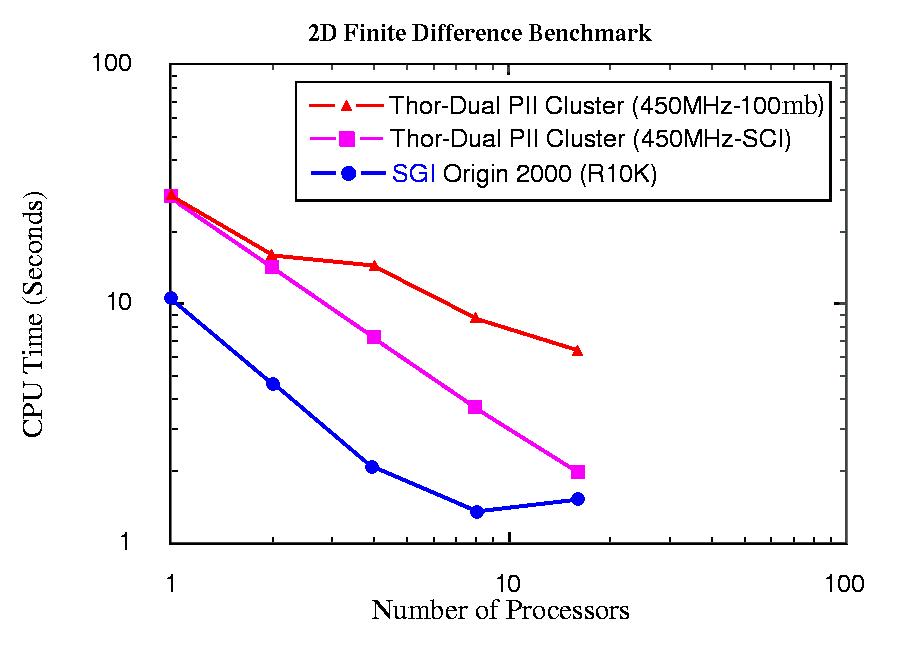
Figure 4. Benchmark Results from a Finite Differences Program for Seismic Modeling
Over the last year and a half, THOR has grown from just two dual Pentium II machines to over 40 dual Pentium II/IIIs. We found that the maintenance and operation of a two-node array was not much different from running a 40-node array. Another gratifying feature, which has been reported by other groups with Beowulf-type clusters, is the reliability of the THOR cluster. We have been running the PBS batch queuing system since March, 1999, and have logged over 80,000 CPU hours with only one system failure due to a power interruption, which led us to introduce non-interruptible power supplies for the complete cluster. Another important discovery was that the construction and maintenance of THOR did not need a team of highly skilled personnel. We found that only “one quarter” of a person skilled in PC networking and Linux was required to implement the system, with some initial assistance from Dolphin for the SCI network. Also, the use of commodity operating systems allows programs to be developed at researchers' desktop machines for later implementation on THOR, thus easing the task of software development.
Our experience running THOR has been in three main areas: multiple-serial Monte Carlo (or embarrassingly parallel) production jobs, prototyping an Event Filter sub-farm for ATLAS (a time-critical operation using specialized software developed for the ATLAS high-level trigger system) and as a fully parallel processor. Large Linux clusters are probably most effective when running applications that require almost no inter-processor communication where the network does not become a bottleneck. However, many applications that require fully parallel machines for significant message passing still spend most of their time computing.
Because parallel computing is such an important topic, we spent some time assessing how the THOR multiprocessor running Linux can be used to implement applications requiring parallel processing. Since there is currently a high level of support for shared-memory programming under SMP Linux, we have used the THOR Linux cluster with the message-passing construct, Message Passing Interface (MPI). There are several advantages to using this programming model. For example, many parallel applications are limited more by floating-point performance than by inter-processor communication. Thus, SCI and even fast Ethernet are sufficient even when there is a relatively large amount of message passing. Another advantage is that MPI is a standard programming interface that runs on many parallel machines, such as the Cray T3 series, IBM SP series, SGI Origin, Fujitsu and PC/Macintosh clusters. Therefore, code can be moved easily between platforms.
One of the THOR groups involved in Plasma Physics research has developed simulations that follow the motion of about 12 million charged particles. A portion of this code utilizes multi-dimensional Fast Fourier Transforms. We achieved nearly perfect scalability for up to 32 processors (all that was available at the time) on the THOR cluster. The code, following the MPI model, was easily transferred from an SGI Origin 2000 platform to the THOR Linux cluster. The performance of this program on THOR compared with other platforms as shown in Figure 3. Other benchmarks are given in Figure 4. At the time these benchmarks were performed, THOR consisted of only 450MHz machines.
Our experience with the THOR Linux cluster described above shows that if we divide the total cost of the machine by the number of processors, we end up with a cost of around $1,500 (CDN) per processor. This is cheaper than conventional supercomputers by more than a factor of ten, assuming reasonable discounts apply. Although there are certainly applications in which conventional supercomputers are irreplaceable, on a price-performance basis, THOR (or Beowulf)-type multiprocessors are more attractive. Another cost advantage of the THOR Linux cluster is the low software cost. GNU's compilers and debuggers, along with free message-passing implementations (MPI) and portable batch-queuing system (PBS), with no yearly fees, offer good low-cost solutions. Better compilers including FORTRAN90, such as the Absoft product, offer significant performance enhancements and debugging tools in the MPI environment.
The comparatively small upfront costs of the THOR Linux cluster are matched by its low running costs. Our experience indicates that, at least for machines as large as THOR, the manpower costs involved with running the machine are low. For example, THOR requires only approximately 30% of the time of a networking/Linux expert. We think this is due to the reliability, design simplicity and accessibility of the commodity component multiprocessor approach. New nodes can be added to THOR on the fly without rebooting any machines; also, problem nodes can be hot-swapped. The node being a conventional PC, probably with a one-year warranty, can either be repaired or thrown away. In fact, hardware and software maintenance costs for THOR have proven to be negligible compared to the annual maintenance fees required by most conventional supercomputer producers. Such fees can be in excess of tens of thousands of dollars per year. The advantages of Beowulf-type clusters like THOR, running Linux, are so numerous that we are not surprised that more and more scientific and commercial users are adopting this approach.

James Pinfold (pinfold@phys.ualberta.ca) is Director of the Centre for Subatomic Research at the University of Alberta and leader of the THOR Linux cluster, a commodity component supercomputer project. His main research effort is in the area of high-energy collider physics, where he is currently working on the OPAL and ATLAS experiments at the European Centre for Particle Physics (CERN) near Geneva, Switzerland.

