
Detecting Chaos in the Field
Scientists and engineers were among the first to notice what a powerful combination the Linux kernel and the GNU tools are. Thus, it is no surprise that it was the sober scientists who started replacing expensive supercomputers with inexpensive networks of GNU/Linux systems. In spite of the strong position of GNU/Linux in all areas of scientific computing, there are still some aspects of the Linux kernel which have been neglected by engineers. One of them is the sound card interface.
In the early days of Linux, sound cards were notoriously unreliable in their ability to process data and continuous signals. They were supposed to handle sounds in games, and nothing more; few people tried to record data with them. Today, modern sound cards allow for simultaneous measurement of signals and control of processes in real time, and good sound cards can compete with expensive data acquisition cards which cost more than the surrounding PC. This article demonstrates how to abuse a sound card for measurements in the field.
With appropriate software, an ordinary PC can do much more than just record data in the field and analyse it off-line in the office. Due to the extreme computing power of modern CPUs, it is possible to analyse data while recording it in real time. On-line analysis allows for interactive exploration of the environment in the field, just like oscilloscopes of earlier days, but with an added dimension.
First, you will need to install the sound card and its drivers in your Linux system. As usual, the book that comes with your Linux distribution should help a lot, and HOWTOs on the Internet provide the necessary instructions (see sidebar “Sound Installation”). When your sound card and its drivers are installed, you should do some testing with it. Make a recording while adjusting the mixer gain, and play the recording back through your loudspeaker. The mixer is an important feature of your sound card, because it allows you to adjust the sensitivity of the A/D converter to the level of the signal to be recorded. This is even more important when recording with a resolution of 8 bits. Keep in mind that we are looking for fast and robust measures of qualitative effects, rather than precise quantitative measurements.
If your GNU/Linux system does not already have some audio applications installed, see Resources for a collection of addresses on the Internet. There, you will find applications like smix, a mixer with a well-designed user interface. It can handle multiple sound cards, and has the features needed for serious work:
interactive graphical user interface
command-line interface
configuration file settings
It makes no difference to your sound card whether the recorded signal comes from an acoustic microphone or an industrial sensor. Signals of any origin are always stored as sequences of values, measured at fixed time intervals (i.e., equidistant in time). Acoustic signals on a CD, for example, are sampled 44,100 times per second, resulting in one (stereo) value every 1/44100 = 22.7 microseconds.
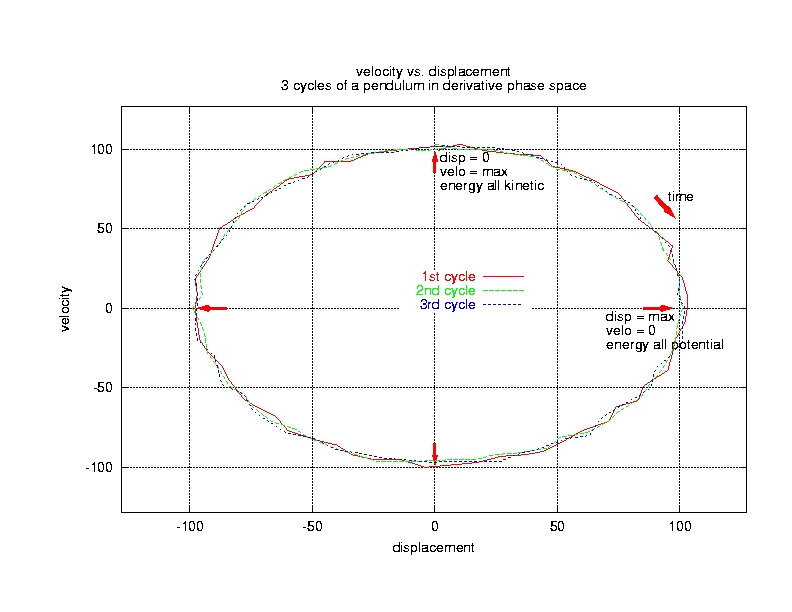
Figure 1. Phase Space Portrait of a Pendulum
While musicians may be interested in filtering these signals digitally (thereby distorting them), we are more interested in finding and analysing properties of the measured, undistorted signal. We are striving to find the rules of change governing the sampled series of values. The major tool in Nonlinear Signal Processing for finding the laws of motion is delay coordinate embedding, which creates a so-called phase space portrait from a single time series (Figures 1 and 2). If you are not interested in technical details, you may envisage it as a tool which turns a sequence of sampled numbers into a spatial curve, with each direction in space representing one independent variable. If you are interested in technical details, you will find them in the Phase Space sidebar. In any case, you should look at the list of FAQs of the newsgroup sci.nonlinear (see Resources). These explain the basic concepts and some misconceptions, and provide sources for further reading.
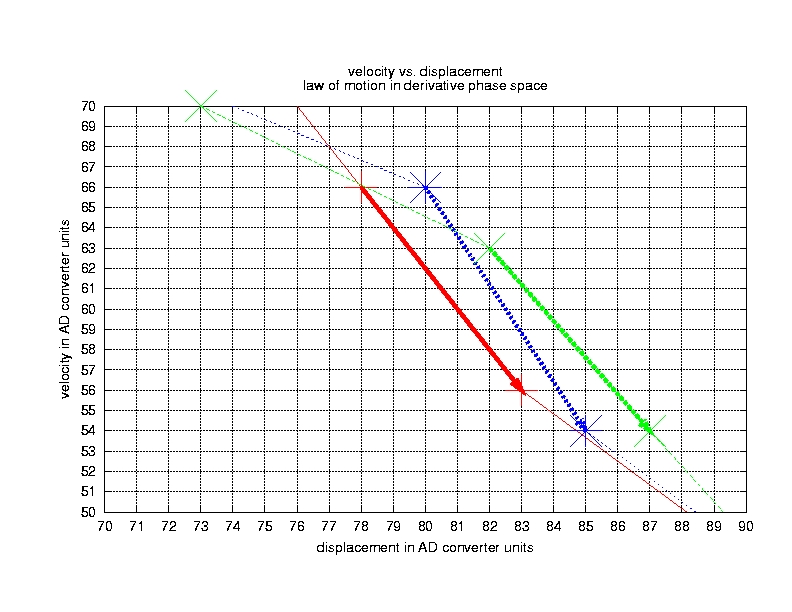
Figure 2. Progress of the Pendulum in Phase Space
Before delving into multi-dimensional space, let us look at an example. Plug a microphone into your sound card's jack, whistle into the microphone and use any of the many freely available sound editors (see Resources) to record the whistling. The resulting recording will look very much like the sine wave in Figure 3. It is not surprising that your recorded wave form looks similar to the wave form of the pendulum in Figure 3. The vibrating substances (gas or solid) may be different, but the laws of motion are very similar; thus, the same wave form.

Figure 3. Wave Form of Pendulum
You can download some software from the FTP server of Linux Journal, which records your whistling and does the phase-space analysis for you (see Resources). Instead of displaying the wave form, the software just extracts important measures of the signal which help you refine your measurements (Figure 4). Remember, it is not my objective to show you how to present stunning, glossy pictures; rather, it is to demonstrate what a valuable tool your Linux machine is when analysing real-world signals in the field.

Figure 4. Finding a Good Embedding by Adjusting Independent Parameters
Start the software by typing
wish -f embed.tcl | dmm
A window will pop up that looks like Figure 4. In this window, you can control the way the software measures the whistling sound from your microphone. You can change the sample rate (click on 44,100Hz) from left to right, the length of the analysed blocks (click on 1 second) and the parameters tau and de, which are needed for reconstruction of the phase space portrait from just one measured signal. This is comparable to the displacement of Figure 1; we have no velocity measurement here.
Each time we analyse an unknown signal, we have to start with some educated guessing of the two parameters:
tau is the temporal distance, or delay, between spatial coordinates
de is the number of dimensions of the reconstructed phase space
These parameters are of crucial importance for a good unfolding of the portrait of the signal in reconstructed phase space (see the sidebar Embedding). In Figure 5, you can see how the choice of tau influences the portrait. Values which are too small cannot unfold the portrait; values which are too large are not shown, but often lead to meaningless (noisy, uncorrelated) portraits. The software supports you in finding good values for tau and de. After years of intense research, scientists still rely on some heuristics for choosing suitable values for these parameters.

Figure 5. Differences in Unfolding, Depending on Parameter
In the particular case of your whistling, the values in Figure 4 should result in a good unfolding of the portrait. Do not worry about the text lines which fill your terminal window. They are needed for checking the quality of the unfolding. Restart the software by typing
wish -f embed.tcl | dmm | wish -f out.tcl

Figure 6. Parameters of a Sine Wave
and the text lines will be converted into the more readable form of Figure 6. In the additional window popping up now, you will see several columns. On the left (in grey), the independent parameters of the first window are repeated. The second column from the left tells you if the loudness of the measured signal is well-adjusted to the sensitivity of your sound card's input. The general rule is, as long as there are red lines in the second column, you have to adjust sensitivity (with a separate mixer software) or loudness. Now, turning to the third column, we see more-advanced parameters:
Spread is the difference between the largest and the smallest value, measured in AD converter units. Small values indicate insufficient strength of the signal.
Inf is the average information content of one sample, measured in bits. A constant baseline signal yields 0 bits (minimum) and random noise has 8 bits (the maximum with 8-bit samples).
MutInf is the average mutual information of one sample and the delayed one. Thus, it tells you how similar the signals of both axes in Figure 5 are. A value of 1 means they are perfectly coupled (in the sense of probabilistic dependency), 0 means completely independent.
AutoCorr (autocorrelation) is another measure of similarity. Since the late 1980s, there has been a (questionable) rule of thumb saying that a value near 0 indicates a good unfolding of the reconstructed portrait. The maximum is 1.
PrErHy measures predictability and therefore determinism of the signal. The underlying algorithm of prediction is the conventional linear predictive filter as used in many adaptive filtering applications like modems. The minimum 0 indicates perfect (linear) predictability, while the maximum 1 indicates complete unpredictability by means of linear filtering.
Determinism, Prediction and Filtering
Again, the rule is, as long as there are red lines in the third column, phase space is not reconstructed properly. Now, turning to the last two columns, you will notice they look identical. Indeed, they are. The difference is this: when evaluating the parameters of the fourth column, the software uses a reversed time axis. When reversing time, i.e., exchanging past and future, prediction turns into postdiction and vice versa. Reversing the time axis is a simple and effective way of checking the validity of parameters which are especially susceptible to measurement errors. In general, if reversal of time changes a parameter, it is not trustworthy, which bring us to the next parameter:
If FNearN (percentage of false nearest neighbours) is reliable, the lines will turn green and be the same in both columns (near 0). Otherwise, it will turn red and indicate that the neighbourship relation of points in phase space is not preserved when changing the parameter de, indicating an insufficient embedding.
PrErLi is the result of re-calculating parameter PrErHy over the whole data block. They should always be roughly the same. If not, there must be a reason for it, and things get interesting.
PrErN measures the predictability with a nonlinear prediction algorithm. Signals originating from a linear system are usually predicted more precisely by PrErLi while signals from nonlinear sources are often predicted better by nonlinear prediction.
MaxLyap measures separation (progressing over time) of points nearby in phase space. By definition, values larger than 0 indicate chaos.
When measuring signals from nonlinear systems, PrErLi often turns red (indicating insufficient linear predictability) while PrErN stays green (indicating sufficient nonlinear predictability). In case of a truly chaotic signal, MaxLyap will turn green (valid) and have opposite signs on the right-most columns. This indicates nearby points are separating over time when time is going forward, and they are approaching each other at the same rate when moving backward in time.
For the moment, the number of parameters and values may be overwhelming. If you start by playing with the software and actually analysing some signals in the field, you will soon become acquainted with the parameters in their colours and columns. The first time, you should look only at the two left-most columns in Figure 6. All parameters there have intuitive meanings, and you will soon be able to foretell how they change when applied to a different signal, a clipped signal or an oversampled signal. Here are some typical situations and how to recognize them:
Sine wave: just as in Figure 6, de (embedding dimension) should be 2 or 3. Mean (i.e., average) and Median (i.e., “middlest”) are the same. Modus is jumping back and forth between Maximum and Minimum. If the Spread reaches its maximum (256), Inf gets near 8 (bits).
Zero baseline (short-circuit or switched off) can be recognized by looking at column 2. All values are identical. In column 3, Spread and Inf are almost 0.
Switching on a microphone, there is a short and sharp impulse resulting in a sudden change of Spread; few others change.
Sawtooth (Figure 7) looks much like the sine, except for Modus, which jumps wildly. MutInf is at its maximum, linear prediction works only with higher-order filters, while nonlinear prediction works better with low embedding dimensions.
Noise comes in many different flavours, all of them having low values of AutoCorr and most with a low MutInf.

Figure 7. Parameters of a Sawtooth Signal
Why not calculate some kind of fractal dimension of a signal? By definition, calculation of dimensions must look at the values over a wide range of scales. With 8 bits of resolution, this is impossible or questionable. But even if we had some fractal dimension value, it would not be as useful as the largest Lyapunov exponent. Furthermore, are all these measurements any good? Yes, there are some areas of application:
System Identification: in some applications, the focus of attention is more on the quality of the signal (stochastic or deterministic, linear or nonlinear, chaotic or not).
Prediction: today, linear prediction is one of the most important algorithms for digital signal processors (DSPs) in telecommunication, be it mobile telephony, modems or noise canceling. If there are systems with nonlinear behaviour involved, nonlinear prediction can be advantageous (see sidebar “Determinism, Prediction & Filtering”).
Control: if you know the structure of your system's phase space well enough, you can try to control the system like this:
Identify periodic orbits in phase space.
Look for an orbit which meets the given requirements (goes through a certain point, or has minimum energy or cost).
Modify a suitable parameter or a variable just slightly to stabilize the desired periodic orbit.
When Ott, Grebogi & Yorke first published successful application of this method (called the OGY method) in 1990, they even managed to control a system in the presence of chaos.
In the late 1990s, several people analysed the time series of the financial markets in order to find signs of nonlinearity or chaos (for example, Blake LeBaron in Weigend & Gershenfeld's book, page 457). Some hoped to be able to predict time series of stock values in this way. Kantz & Schreiber took the idea one step further, and contemplated the application of the OGY method to control the stock market. But in a footnote on page 223 of their book, they admit, “We are not aware of any attempts to control the stock market as yet, though.” When I looked at the chart of Red Hat stock in late 1999, I wondered whether someone had finally managed to apply the OGY method to the time series of the Red Hat share price.
email: Juergen.Kahrs@t-online.de
Juergen Kahrs (Juergen.Kahrs@t-online.de) is a development engineer at STN Atlas Elektronik in Bremen, Germany. There, he uses Linux for generating sound in educational simulators. He likes old-fashioned tools like GNU AWK and Tcl/Tk. Juergen also did the initial work for integrating TCP/IP support into gawk.
