
The Network Block Device
In April of 1997, Pavel Machek wrote the code for his Network Block Device (NBD), the vehicle for his work being the then-current 2.1.55 Linux kernel. Pavel maintained and improved the code through four subsequent releases, matched to kernels 57, 101, 111 and 132. Andrzej M. Krzysztofowicz contributed 64-bit fixes and Stephen Tweedie later contributed his substantial expertise, particularly in providing a semaphore-based locking scheme to make the code SMP-safe. We have enhanced it for use in an industrial setting by the authors, and here we describe the device, the driver and some of its development history.
The Network Block Device driver offers an access model that will become more common in this network-oriented world. It simulates a block device, such as a hard disk or hard-disk partition, on the local client, but connects across the network to a remote server that provides the real physical backing. Locally, the device looks like a disk partition, but it is a fa<\#231>cade for the remote. The remote server is a lightweight piece of daemon code providing the real access to the remote device and does not need to be running under Linux. The local operating system will be Linux and must support the Linux kernel NBD driver and a local client daemon. NBD setups are being used by us to provide real-time off-site storage and backup, but can be used to transport physical devices virtually anywhere in the world.
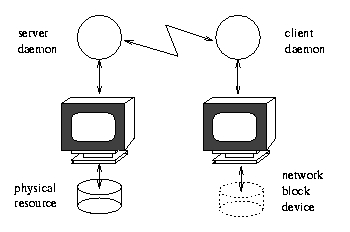
Figure 1. An NBD Presents a Remote Resource as Local to the Client
The NBD has some of the classic characteristics of a UNIX system component: it is simple, compact and versatile. File systems can be mounted on an NBD (Figure 1). NBDs can be used as components in software RAID arrays (Figure 2) and so on. Mounting a native Linux EXT2 file system over an NBD gives faster transfer rates than mounting an NFS (Network File System) from the same remote machine (see Table 1 for timings with a near-original version of Pavel's driver).
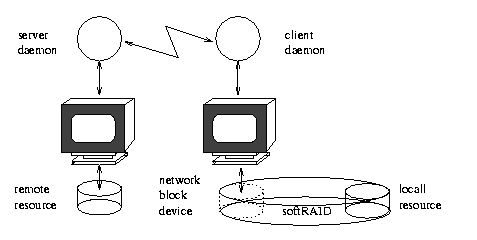
Figure 2. Remote Mirroring via Software RAID plus an NBD
A remote Linux EXT2 file system mounted via NBD measures up to tests under default conditions like an NFS with approximately 1.5KB buffer size. That is, its apparent buffer size is the default Ethernet transmission unit size (MTU/MRU) of 1.5KB, which happens to be 1.5 times the NFS default buffer size of 1KB. The NBD gains resilience through the use of TCP instead of UDP as the transfer protocol. TCP contains its own intrinsic consistency and recovery mechanisms. It is a much heavier protocol than UDP, but the overhead in TCP is offset for NBD by the amount of retransmission and correction code that it saves.
An NBD could be used as a real-time spool mirror for a medium-sized mail server A. The failover is to a backup server B in another room, connected by a 100BT network. The NBD device connects the primary to the backup server and provides half (Y) of a RAID-1 mirror on the primary. The other half of the mirror is the primary server's own mail partition X. The composite device XY is mounted as the primary's mail spool.
On failure of A, a daemon on B detects the outage, disengages the NBD link, checks its image Y of the spool, corrects minor imperfections, mounts it locally as its mail spool and starts aliasing for A's advertised mail-exchanger IP address, thus taking over the mail service. When A recovers, it is detected and the alias is dropped. A and B then re-establish the NBD link, and the mail partition X on A is resynchronized to the NBD image Y. Then the primary server's RAID-1 device is brought back up, the NBD image is slaved to it under RAID, and the mail service resumes in the normal configuration. It is possible to make the setup symmetric, but that is too confusing to describe here.
This approach has advantages over common alternatives. One, for example, is to maintain a reserve mail server in an empty state and bring it up when the main server goes down. This makes any already-spooled mail unavailable during the outage, but reintegration is easy. Simply concatenate the corresponding files after fixing the primary. Some files on the primary may be lost.
Another method is to scatter the mail server over several machines all mounting the same spool area via NFS. However, file locking over NFS has never proven completely reliable in the past, and NFS has never yet satisfactorily been able to support the bursts of activity caused by several clients choosing to download 50MB mail folders simultaneously. The transfer rate seems to slow exponentially with folder size, and in “soft” mode, the transfer can break down under adverse network conditions. If NFS is mounted in synchronous (“hard”) mode for greater reliability while the NFS server is up, failure of the NFS server brings the clients to a halt. The NFS server has to be mirrored separately.
A third alternative is to maintain a mirror that is updated hourly or daily. However, this approach warps the mail spool back in time during the outage, temporarily losing received mail, and makes reintegration difficult. The NBD method avoids these problems but risks importing corruption from the source file system into the mirror, when the source goes down. This is because NBD operations are journaled at the block level, not the file system level, so a complete NBD operation may represent only a partially complete file operation. The corruption and subsequent repair is not worse than on the source file system if the source actually crashed; if connectivity was the only thing lost, the source system may be in better shape at reintegration than the mirror. To avoid this problem, the Linux virtual file system (VFS) layer must be altered to tag block requests that result from the same file operation, and the NBD must journal these as a unit. That implies changes in the VFS layer, which we have not yet attempted to implement.
Given the slightly chequered history of NFS in Linux, it may be deemed something of an advantage that the NBD driver requires no NFS code in order to supply a networked file system. (The speed of NFS in the 2.2.x kernels is markedly superior to that of the 2.0.x implementations, perhaps by a factor of two, and it no longer seems to suffer from nonlinear slowdown with respect to size of transfer.) The driver has no file system code at all. An NBD can be mounted as native EXT2, FAT, XFS or however the remote resource happens to be formatted. It benefits in performance from the buffering present in the Linux block device layers. If the server is serving from an asynchronous file system and not a raw physical device at the other end, benefits from buffering accrue at both ends of the connection. Buffering speeds up reads one hundred times in streaming measurements (it reads the same source twice) depending on conditions such as read-ahead and CPU loading, and appears to speed up writes approximately two times. With our experimental drivers, we see raw writes in “normal use” achieving about 5MBps to 6MBps over switched duplex 100BT networks through 3c905 network cards. (The quoted 5-6MBps is achieved with buffering at both ends and transfers of about 16MB or 25% of installed RAM, so that buffering is effective but not dominant.)
In 1998, one of the authors (Breuer) back-ported the then-2.1.132 NBD to the stable 2.0-series kernels, first taking the 2.1.55 code and reverting the kernel interface, then paralleling incremental changes in Pavel's subsequent releases up to 2.1.132. That code is available from Pavel's NBD web pages (atrey.karlin.mff.cuni.cz/~pavel/nbd/nbd.html) along with Pavel's incrementals. The initial back port took out the new kernel dcache indirections and changed the networking calls back to the older style. The final changes paralleled late 64-bit adaptations in Pavel's sources.
Like the original, the back-ported code consists of a kernel module plus a small adaptation to the kernel block-driver interface, and user-space server and client daemons. Pavel proved to be an extremely helpful correspondent.
The driver worked very well on the development Linux machines in use in our department, where we maintained a much-modified 2.0.25 kernel code base for several years. With the perceived robustness of the 2.0.36 kernel release in particular, we ported the driver forward. Surprisingly, it failed completely. It locked up any client after only about 0.5MB of transfers.
To this day, we do not know precisely the nature of that problem. Stephen Tweedie examined the algorithm in the ported driver and concluded it to be the same as the 2.1.132 algorithm, which works, and Pavel approved the protocols. Tracing back the 2.0-series kernels patch by patch failed to find any point at which the driver stopped working. It did not work in any standard release. Our best guess is that nonstandard scheduler changes in our code base were responsible for the initial port working smoothly in our development environment, and that general changes in the 2.1 series had somehow obviated the problem there.
Experiments showed that the in-kernel queue of outstanding block requests grew to about 17 or 18 in length, then corrupted important pointers. We tried three or four methods aimed at keeping the queue size down, and empirically seemed to control the problem with each of them. The first method (Garcia) moved the networking out of the kernel to the user-space daemons, where presumably the standard scheduling policy served to remove an unknown race condition. The second method (Breuer) kept the networking in-kernel, but serialized network transfers so that every addition to the pending queue was immediately followed by a deletion, thus keeping the queue size always equal to zero or one. The third method (Garcia) removed the queue mechanism entirely, keeping its length at zero. A fourth method (Breuer) made the client daemon thread return to user space after each transfer to allow itself to be rescheduled.
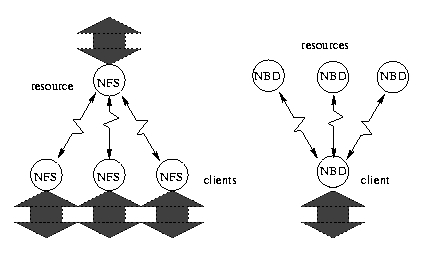
Figure 3.
NFS provides a star configuration, with the server at center (left). NBD, with the help of internal or external RAID, provides an inverted topology with multiple servers and a single client.
For a considerable time, running in serialized mode seemed to be the best solution, although the user-space networking solution is also reliable. With our recent development work, we have gained deeper insight into the kernel mechanisms working here, and although no definitive explanation of the original instability is available, we do have completely stable drivers working in a fully asynchronous in-kernel networking mode as well as user-space versions of the same protocols. A suggestion is the possible misgeneration of code by the gcc compiler (a>b=0; c>d=a; if(c>d>b) printk("bug"); output generated just before lockups!) but it is possible that stack corruption caused a misjump into the linear code sequence from elsewhere. Increased re-entrancy of the driver code and more forgiving network transfer protocols definitely increased the stability while the problem was detectable, which is a good co-indicator for a race condition.
Steps in Setting Up an NBD-Based File System
The five steps required to create a file system mounted on a network remote device are outlined in Figure 4. For example, the following sequence of commands creates an approximately 160MB file on a local file system on the server, then launches the server to serve from it on port 1077. Steps 1 and 2 are
dd if=/dev/zero of=/mnt/remote bs=1024 count 16000 nbd-server 1077 /mnt/remote
On the client side, the driver module must be loaded into the kernel, and the client daemon started. The client daemon needs the server machine address (192.168.1.2), port number and the name of the special device file that will be the NBD. In the original driver, this is called /dev/nd0. Step 3 is
insmod nbd.o nbd=client 192.168.1.2 1077 /dev/nd0A file system can then be created on the NBD, and the system mounted locally with Steps 4 and 5:
mke2fs /dev/nd0 mount -text2 /dev/nd0 /mntIn our current drivers, multiple ports and addresses are allowed, causing redundant connections to be initiated. Here, the server offers several ports instead of one:
dd if=/dev/zero of=/mnt/remote bs=1024 count=16000 nbd-server 1077 1078 1079 1080 /mnt/remoteThe current client can use all these ports to the server, and here we direct two of them to a second IP (192.168.2.2) on the server so that we can route through a second network card on both machines and thus double the available bandwidth through our switched network.
insmod nbd.o nbd-client 192.168.1.2 1077 1078 192.168.2.2 1079 1080 /dev/ndaIn the current drivers, the NBD presents itself as a partitioned block device nda, although the “partitions” are not used in a standard way. Their device files nda1, nda2 and so on are used as kernel communication channels by the subordinate client daemons. They provide the redundancy and increased bandwidth in the device. The whole-device file nda is the only one that accepts the standard block-device operations.
On insertion of the kernel module, the driver registers with the kernel. As the client daemon connects for the first time to its server counterpart, the original driver hands the file descriptor of the socket to the kernel . Kernel traces the descriptor back to the internal kernel socket structure and registers the memory address in its own internal structures for subsequent use. Our current drivers keep the networking in user space and do not register the socket.
The client daemons and server daemons then perform a handshake routine. No other setup is required, but the handshake may establish an SSL channel in the current generation of drivers, which requires SSL certificates and requests to be set up beforehand.
Pavel's original driver code comprised two major threads within the kernel. The “client” thread belongs to the client daemon. The daemon's job is to initiate the network connection with the server daemon on the remote machine, and hand down to the kernel via an ioctl call the socket it has opened. The client daemon then sits blocked user-side in an ioctl call while its thread of execution continues forevermore within the kernel. It loops continuously transferring data across the network socket from within the kernel. Terminating the daemon requires terminating the socket too, or the client daemon will remain stuck in the loop inside the kernel ioctl.
A “kernel” thread enters the driver sporadically as a result of pressures on the local machine. Imagine that echo hello >! /dev/nd0 is executed (the block-device names for the original driver are nd0-127, and they take major number 43). The echo process will enter the kernel through the block device layers, culminating in a call to the registered block-device request handler for a write to the device. The kernel handler for NBD is the function nbd_request. Like all block-device request handlers, nbd_request performs a continuous loop while(req = CURRENT), CURRENT being the kernel macro that expands to the address of the write request struct. After treating the request, the driver moves the pointer on with CURRENT = CURRENT->next and loops.
The kernel thread's task is to do the following:
Link the request req = CURRENT to the front of the pending transfer list.
Embed a unique identifier and emit a copy across the network to the server daemon at the other side of the network socket.
The unique identifier is the memory address of the request req. It is unique only while the request has not yet been serviced, but that is good enough. (When the driver used to crash through the mysterious corruption we were never able to pin down, the crash was often associated with duplicated entries and a consequently circular list, which may be a clue.)
On the other side of the network, the server daemon receives a write request, writes “hello” to its local resource, and transmits an acknowledgement to the client containing the unique identifier of the request.
The client daemon thread on the local machine is in its loop, blocked inside the kernel on a read from the socket, waiting for data to appear. Its task is now to do the following:
Recognize the unique identifier in the acknowledgement, comparing it with the oldest (last) element req in the linked list of partially completed requests.
Unlink the request req from the list of incompletes, and tell the block layers to discard the structure via a call to end_request.
This protocol requires that the acknowledgement received be for the request pending on the tail of the driver's internal list, while new requests from the kernel are added to the head. TCP can guarantee this because of the sequential nature of the TCP stream. Even a single missed packet will break the current driver, but it will also mean the TCP socket is broken. The socket will return an error in this situation. That error message allows the driver to disengage gracefully.
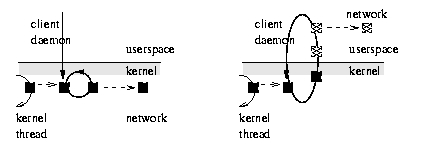
Figure 4.
Kernel networking vs. user-space networking in an NBD. User-space networking requires an extra copy and other overheads, but affords much greater flexibility. The overhead can be offset by transferring multiple requests at a time.
The client-side control flow in the original kernel driver is shown schematically on the left side of Figure 4. The black rectangle represents a request. It is linked into the device's request queue by a kernel thread and is then swept up in the client daemon's perpetual loop within the kernel. The client thread performs networking within the kernel. In the drivers we have subsequently developed, we have come to favour user-side networking, in which the client thread deals user-side with a copy of the request transferred from within the kernel. It dives repeatedly into the kernel to copy across the data, then transmits it in standard network code. The overheads are much greater, but the flexibility is also much greater. The overhead can be ameliorated by transferring multiple requests across at a time, and our current drivers do this. Normally, 10 to 20 requests of one block each will be transferred in each visit to the kernel. The cost of copying between kernel and user space cannot, however, be avoided. Multiple client daemons contend for the kernel requests as the clients become free, transferring them across the network through possibly distinct routes and physical devices. The situation is depicted in Figure 4. Each client daemon handles one channel, but will mediate any request. The channels provide redundancy, resilience and bandwidth.
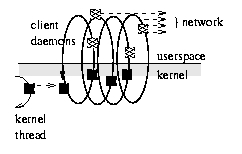
Figure 5.
Multiple client daemons capture kernel requests in the current NBD drivers, providing redundancy and load balancing through demand multiplexing across several distinct network channels.
The complete data protocol sequence “on the wire” is shown in Table 3. Note that the unique ID is 64-bit, so it may use the request's memory address as the identifier on a 64-bit architecture. Curiously, the requested data offset and length are 32-bit byte offsets in the original driver, although they are calculated from sector numbers (sectors are 512 bits each) which might well have been used instead. This is a hidden 32-bit limitation in the original NBD. Our versions implement 64-bit limits on a 32-bit file system or machine architecture. The server daemon has been modified to multiplex requests beyond 32 bits among several distinct resource files or devices.
The goal of our industrial partners in the driver development was to obtain improvements in areas which are important to an industrial-strength setting (see Table 4).
For example, the original driver broke irretrievably when the network link broke, or when a server or client daemon died. Even if reconnected, an I/O error became visible to the higher layers of, for example, an encompassing RAID stack, which resulted in the NBD component being faulted off-line. We have worked to increase robustness by making externally observable failure harder to induce, letting the driver deal internally with any transient problems. The current drivers log transactions at the block level. A spoiled transaction is “rolled back” and resubmitted by the driver. Doubly completed transactions are not considered an error, the second completion being silently discarded.
A transaction spoils if it takes too long to complete (“request aging”), if its header or data becomes visibly corrupted or if the communication channel errors out between initiation and completion of the transaction. To keep their image of the link state up to date, the drivers send short keep-alives in quiet intervals. Data can still be lost by hitting the power switch, but not by breaking the network and subsequently reconnecting it, nor by taking down only one or two of the several communication channels in the current drivers. The drivers have designed-in redundancy. Redundancy here means the immediate failover of a channel to a reserve and provision for the multiple transmission and reception of the same request.
There are many ways in which connectivity can be lost, but differently routed network channels survive at least some of them. The daemon client threads (one per channel) demand-multiplex the communications among themselves according to demand and their own availability (kernel-based round-robin multiplexing has also been tried). Under demand-multiplexing, the fastest working client threads bid for and get most of the work, and a stopped or non-working thread defaults its share of the workload to the working threads. In conjunction with journaled transactions and request aging, this seems very effective. Channels automatically “failover” to a working alternative.
Speed is also an important selling point in industry. Our client-daemon threads are fully asynchronous for maximum speed. They are not synchronized via locks or semaphores inside the kernel (apart from the one semaphore atomicising accesses to the NBD major's request queue). This means kernel requests may be treated out of order at various stages of their lifetime, so the driver has had to be revised carefully to meet this requirement. In particular, the standard Linux kernel singly linked request list has been converted to a doubly linked list, appropriating an otherwise unused pointer field. The driver can then “walk the queue” more easily to search for a match in the out-of-order case. The kernel really should implement a doubly linked request-queue structure. The main brake on speed is probably the indiscriminate wakeup of all client threads on arrival of one kernel request, but when the requests come in faster than the daemons can send them, that overhead disappears.
Although failover of a network channel may be unobserved from outside the driver, it will degrade communications in some senses of the word. So, our current daemon implementations reconnect and renegotiate in an attempt to restore a failed channel. If the daemons themselves die, then they are automatically restarted by a guardian daemon, and the kernel driver will allow them to replace the missing socket connection once the authentication protocol is repeated successfully. Upon reconnection, any pending read/write requests unblock if they have not already been rolled back and resubmitted via another channel. If the device is part of a RAID stack, the outage is never noticed.
Connections between remote and local machines, when multiplexed over several ports as in our drivers, can be physically routed across two different network interfaces, doubling the available bandwidth. Routing across n NICs multiplies available bandwidth by n until the CPU is saturated. Since streaming through NBD on a single 3c905 NIC loads a Pentium 200MHz CPU to about 15% on a 100BT network, a factor of about four to five in increased bandwidth over a single NIC may be available (we have not been able to test for the saturation level, lacking sufficient PCI slots to do so).
Another important industrial requirement is absolute security of the communication channels. We have chosen to pass all communication through an external SSL connection, as it hives off the security aspect to the SSL implementation which we trust. That decision required us to move the networking code entirely out of the kernel and into the client daemons, which are linked with the openSSL code. Moving the code user-side slows the protocol, and it is slowed still further by the SSL layers. The fastest (non-trivial) SSL algorithm drops throughput by 50%, the slowest by 80%. An alternative is to pass the communications link in-kernel through a cipe tunnel, or to site either the server or client daemon on an encrypted file system, but we have not experimented with these possibilities.
SSL offers us the mechanism with the best understood security implications and we have plumped for it. As fallback, a primitive authentication protocol is provided in the driver itself—tokens are exchanged on first connection, and reconnects require the tokens to be presented again. The daemons wrap this exchange and the whole session in the openSSL authentication mechanisms, so it is hardly ever required. Compressing the data as it passes across the link would also provide greater bandwidth (as well as perhaps security), but so far we have not implemented it. It can be applied in the user-side daemon codes.
Whatever limits may or may not be present in the rest of the code, the server daemons are constrained on 32-bit architectures by the 32-bit implementation of EXT2 and other file systems. They can seek up to only a 31-bit (32-bit) offset, which limits the size of the served resource to 2GB (4GB). Our server daemons make RAID linear or striping mode available, however. In these modes, they serve from two or more physical resources, each of which may be up to 2GB in size, to make a total resource size available that breaks the 32-bit barrier by any amount required. Striping seems particularly effective in terms of increased bandwidth, for unknown reasons. The daemons can also serve directly from a raw block device. In those circumstances, it is not known to us if there is a 32-bit limitation in the kernel code—presumably not.
A /proc/nbdinfo entry provides us with details of the driver state, the number of requests handled, errored and so on. The page is read-only (see Listing 1).
Adjustments to default driver parameters, such as the interval between keep-alives and the number of blocks read-ahead, are made via module options on loading the driver. There is currently no mechanism to change parameters at other times. A writable \proc entry or a serial control device is probably desirable. Some degree of control is vested in the client guardian daemon and subordinate client daemons, which send special ioctls to the device on receipt of particular signals. The USR2 signal, for example, triggers an ioctl that errors out all remaining requests, ejects client-daemon threads from the kernel and puts the driver in a state in which the module code can be safely removed from the running kernel. It is, of course, a mechanism intended to aid debugging. The disadvantage of this kind of approach is that it requires a client daemon to be running before control can be exercised. In the future, we intend to implement the /proc-based writable interface. The use of fake partition information in the device is also an appealing route towards obtaining better reports and increased control.
Writing the driver code has been a salutary experience for all involved. The best advice to anyone contemplating writing kernel code is—don't. If you must, write as little as possible and make it as independent of anything else as possible.
Implementing one's own design is relatively easy as long as things go well. The very first bug, however, reveals the difficulty. Kernel code bugs crash the machine often, giving scant opportunity to detect and correct them. Twenty reboot cycles per day is probably near everyone's limit. On occasion, we have had to find a bug by halving the code changes between versions until the precise line was located. Since a moderate number of changes can lead to a patch of (say) 200 lines or more, eight recompilation cycles and tests might be required to locate the point change involved. That says nothing of the intellectual effort involved in separating the patch into independent parts in order to be able to recompile and the effort involved in developing a test for the bug or identifying the behavioural anomaly in the first place. Between one and two weeks is a reasonable estimate for locating a bug via code-halving.
It is very important to have an always-working kernel code. It doesn't matter if the code does not have the right functionality, but it must do what it does right. The code development must be planned to move forward in stages from one working state to another. There must exist no stage of development in which the driver does not work, such as for example having altered a protocol and not yet balanced the change with corresponding changes elsewhere.
Having a working version implies checking in working versions regularly (we used CVS). Check-in occurs only on working versions. On a couple of occasions, we had to fork the line to allow two development areas to proceed independently (moving the networking code out of kernel while reworking the reconnection protocols, for example), then reintegrate the changes via a sequence of non-working minor revisions, but we always had a previous working version available which we tried to make minimal changes to.
Debugging techniques essentially consist of generating usable traces via printk statements. We had printks at entry and exit of every function, activity and branch. That helps us discover where the coding bug occurs. Often, however, the bug is not detectable from the code trace, but rather must be inferred through behavioural analysis. We had a serious bug that was present through half the development cycle and was never detected until integration tests began. It was completely masked by normal kernel block-buffering and showed up as apparent buffer corruption only in large (over 64MB) memory transfers. An md5sum of the whole device would sometimes return differing results when the rest of the machine was under heavy load. It turned out to be two simple bugs, one kernel-side and one server-side, that had nothing to do with buffering at all. In this kind of situation, brainstorming possible causal chains and devising tests for them, then running the tests and interpreting the results is the only feasible and correct debugging technique. This is the “scientific method” as expounded in the 18th and 19th century, and it works for debugging.
Kernel coding really begins to bite back when kernel mechanisms not of one's own devising have to be assimilated. Interactions with the buffering code had to be taken somewhat on trust, for example, because reading the buffering code (buffer.c) does not tell the whole story in itself (for example, when and how buffers are freed by a separate kernel thread). It is good advice to try and limit interactions with the other kernel mechanisms to those that are absolutely predictable, if necessary, by patterning the interactions on other driver examples. In the case of the NBD driver, the original was developed from the loopback driver (lo.c), and the latter served as a useful reference throughout.
The Network Block Device connects a client to a remote server across a network, creating a local block device that is physically remote. The driver we have developed provides mechanisms for redundancy, reliability and security that enable its use as a real-time backup storage medium in an industrial setting as well as allowing for other more imaginative modes. A mobile agent that takes its home environment with it to every system it visits, perhaps? In terms of speed, an NBD supporting an EXT2 file system competes well with NFS.

