
Tracking Satellites with PREDICT
When Sputnik 1 was launched into orbit on October 4, 1957, the space age was born and the fields of science, engineering and technology were changed forever. At last count, there were over 8500 payloads from over 30 countries in orbit around the earth. All of these spacecraft are bound to their home planet by the Earth's gravitational field, and their motions can be described by simple principles of gravity and planetary motion discovered by scientists such as Isaac Newton and Johannes Kepler hundreds of years ago.
Today, earth-orbiting satellites serve many purposes and play important roles in global positioning and navigation, communication networks, scientific exploration, earth resource research, national defense, weather monitoring and education. USSPACECOM, the United States Space Command (formerly NORAD), along with NASA, the National Aeronautic and Space Administration, use radar and optical-ranging techniques to keep close track of the thousands of man-made objects in earth orbit and provide orbital data suitable for orbital modeling and open-ended tracking of unclassified payloads. With an accurate set of orbital parameters in one's possession, it is possible to determine velocities and the past, present and future positions of a satellite in its orbit around the earth with a degree of accuracy suitable for many science and engineering applications.
PREDICT is an effort to bring a versatile, open-source, satellite-tracking and orbital-prediction application to the Linux operating system. PREDICT was adapted from ideas developed in earlier satellite-tracking and orbital-prediction software written nearly a decade ago for use on the then-popular Commodore 64 home computer.
The original version of PREDICT was created as a replacement for the QuickTrak satellite orbital prediction program that was also available for the C64. While QuickTrak was written in BASIC and its source code was interpreted at runtime, PREDICT was written in C and compiled into 6502 machine code. The sole reason for writing PREDICT was to be able to quickly forecast passes of amateur radio communication satellites in advance of their arrival.
For real-time satellite tracking, a separate program called SpaceTrack was written, using a combination of BASIC and hand-assembled machine code. SpaceTrack was sophisticated enough to permit the display of a satellite's position on a bit-mapped Mercator projection map of the world. It even had the ability to articulate the tracking coordinates of a satellite through a voice synthesizer connected to the Commodore 64's user port. The speech synthesizer was used to relay tracking coordinates to a visual observer in real time over a short-range radio link so that the Mir space station and other large spacecraft could be easily located and identified in the evening sky. The speech routines were written entirely in hand-assembled machine language and executed through the same address vector as the computer's hardware interrupt routines. This essentially created a multitasking environment, with the voice synthesizer receiving data through a background process that in no way interrupted the numerical processing taking place in the foreground by the BASIC interpreter.
Although neither program was ever released to the public, they served me quite well for several years until a switch from the aging Commodore 64 to a more modern MS-DOS-based PC was made. In many ways, the switch to the MS-DOS platform was a significant step backward from the C64, especially in terms of programming flexibility and the requirement to relearn the programming process under the new environment. PREDICT was eventually ported to MS-DOS, but the MS-DOS environment simply was not enticing enough to add many new features to the program. Furthermore, there was seemingly no simple way of multitasking and passing parameters between processes under MS-DOS as was possible (as odd as it sounds) on the older and less-sophisticated C64.
PREDICT was also ported to several multi-user UNIX machines around the same time, but hardware differences and the lack of a true understanding of the operating environment prevented further development of the program. Nevertheless, the DOS version of PREDICT was polished up and released to several popular Internet and dial-up software repositories as free software in May 1994, and became quite popular among amateur radio operators involved in satellite communications.
By the time Windows 95 was released, it was time to switch computing environments entirely to Linux. PREDICT was successfully ported from DOS to Linux, and has functioned well in the Linux environment for many years. A pre-compiled Linux binary of PREDICT was released as free software to several FTP sites in 1996. Then in 1999, major portions of the program were rewritten, and in an effort to enhance PREDICT's functionality, several real-time satellite-tracking modes similar to those available in the original SpaceTrack program were added to the program. Speech routines were also added, but instead of using a voice synthesizer to produce vocal announcements, audio samples were sequentially directed to the system sound card using a separate program that was invoked by PREDICT. Much like the original design of SpaceTrack, the speech routines were executed as background processes so as not to delay the execution of real-time orbital calculations while the announcements were being made.
The newly enhanced version of PREDICT was released as open-source software under the GNU General Public License and uploaded to Metalab and several other FTP sites in December 1999. Several weeks later, major portions of PREDICT Version 2 were successfully ported from Linux to DOS using Caldera's DR-DOS operating system and the DJGPP software development environment. This was done to serve as a replacement for the earlier DOS version of PREDICT that was released in 1994.
Within weeks of the Linux release of PREDICT Version 2, the benefits of open source and the GNU General Public License were quickly realized. Bdale Garbee, amateur radio operator N3EUA, built and packaged PREDICT for inclusion in the “potato” release and all later versions of Debian Linux. The Debian PREDICT package is available for all Debian-supported CPU architectures.
Jean-Paul Roubelat, amateur radio operator F6FBB, modified PREDICT to allow the program to control the azimuth and elevation rotators that support his satellite antennas using a hardware interface known as a Kansas City Tracker. Using PREDICT, Jean-Paul was able to have his Linux-based computer automatically track his satellite antennas with the passage of OSCAR satellites in range of his home.
Ivan Galysh, KD4HBO, working at the U.S. Naval Research Laboratory in Washington, Maryland, selected PREDICT for tracking the Stensat satellite. With the source code in his possession, Ivan was able to turn PREDICT into a socket-based server, allowing the program to make real-time tracking data available to external programs through UDP socket connections. One of the client programs Ivan created was an antenna-rotator-control program similar to the function of Jean-Paul Roubelat's program, except it used a different hardware interface. Another was an XForms-based GUI map display program that plots the location and orbital path of satellites being tracked by PREDICT on a Mercator projection map of the world.
By March, a third program that reads Doppler shift information calculated by PREDICT and uses that data to correctly adjust the operating frequency of uplink transmitters and downlink receivers used in satellite communication systems was under development. With the benefits of the socket-based server code clearly evident through these modular client applications, Ivan's server code was made an integral part of PREDICT's official source code and was released in version 2.1.0 in early April 2000.
The latest version of PREDICT may be downloaded from ftp.amsat.org/amsat/software/Linux/predict-latest.tar.gz or from metalab.unc.edu under the /pub/linux/apps/ham subdirectory.
As of version 2.1.0, PREDICT's major features included:
A fast orbital prediction mode that predicts passes of satellites, providing dates, times, coordinates, slant-range distances and sunlight and optical visibility information. Predictions are displayed in tabular form and may be saved to a log file for later reference, printing or parsing by other programs.
An optical visual orbital prediction mode that displays satellite passes that may be optically visible to the ground station.
A solar illumination prediction mode that calculates how much time a satellite will spend in sunlight each day.
A real-time tracking mode that provides dynamic information such as sub-satellite point, ground station azimuth and elevation headings, Doppler shift, path loss, slant range, orbital altitude, orbital velocity, footprint diameter, orbital phase, the time and date of the next AOS (acquisition of signal or LOS, loss of signal, of the current pass), orbit number and sunlight and visibility information for a single satellite, while providing live azimuth and elevation headings for both the sun and moon.
A multi-tracking mode that provides sub-satellite point, azimuth and elevation headings, sunlight and visibility and slant-range distance information for all 24 satellites in the program's current database on a real-time basis. Azimuth and elevation headings for the sun and moon are also provided, as a well as a listing of the AOS dates and times for the next three satellites expected to come into range of the ground station.
Static information such as semi-major axis of ellipse, apogee and perigee altitudes, and anomalistic and nodal periods of satellite orbits.
Command-line options which permit alternate ground station locations to be specified or alternate orbital databases to be read and processed by the program, effectively allowing an unlimited number of satellites to be tracked and managed. Additional options allow any orbital database file to be updated automatically using NASA Two-Line element data obtained via the Internet or via pacsat satellite without having to enter the program and manually select menu options to update the database.
A voice mode that allows live azimuth and elevation headings of a satellite to be articulated to an observer to assist in locating a satellite by optical means.
A socket-based server mode that permits PREDICT to be used to supply real-time tracking data, such as azimuth and elevation headings, footprint diameters, sub-satellite point latitude and longitude values, normalized Doppler shift data and next-predicted AOS times to external programs such as rotator control software, graphical map-tracking software or radio frequency control programs residing either on the host machine or any networked client.
The process of installing PREDICT differs somewhat from that of most open-source software requiring compilation at installation time. An ncurses-based installation program is used to probe the system hardware for the existence of a sound card, and header files are built according to this information and with reference to the installation directory chosen by the user. The program is then compiled, and the resulting executable file is symbolically linked between the installation directory and /usr/local/bin. The same procedure of using symbolic links is also used for PREDICT's man page. The main advantage of this installation method is that it is simple, relatively error-proof and distribution-independent. It also keeps all program files under a single subdirectory, rather than scattering them throughout the entire file system.
Once the program is built and installed, the user is asked to enter his latitude, longitude and altitude above sea level. A database of Keplerian orbital data is also required for the satellites of interest to the user. A database of amateur radio and several “high-interest” satellites is included with the program to get things started. Since the accuracy of Keplerian orbital data seldom remains high for long periods of time, facilities are included in the program to permit the database to be updated from more recent element sets. A simple shell script is included with the program to facilitate this update through an anonymous FTP connection to ftp.celestrak.com. This script may even be invoked through a crontab, permitting automatic updates of PREDICT's orbital database to take place on a regular basis without the need for user intervention.
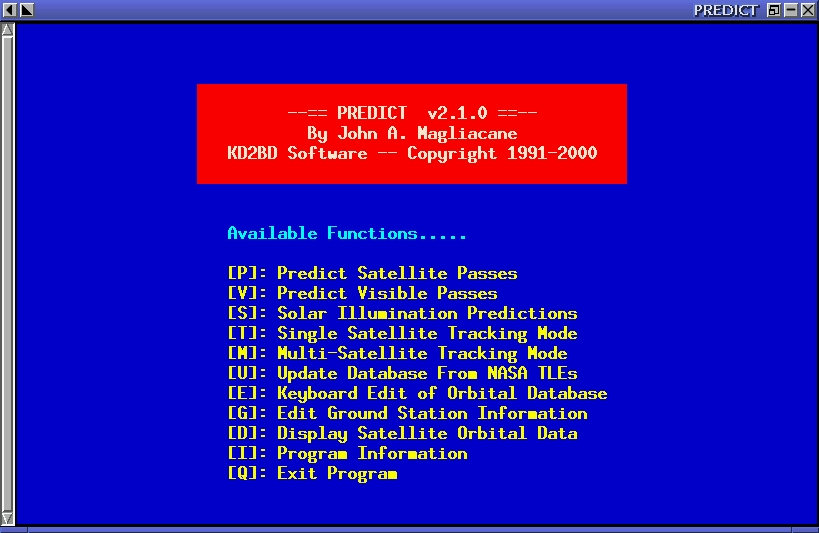
Figure 1. PREDICT's Main Menu
PREDICT is a text-based program, and its start-up screen (see Figure 1) lists all of the program's main functions. Several tracking and orbital-prediction modes are available, as well as several utilities to manage the program's orbital database.
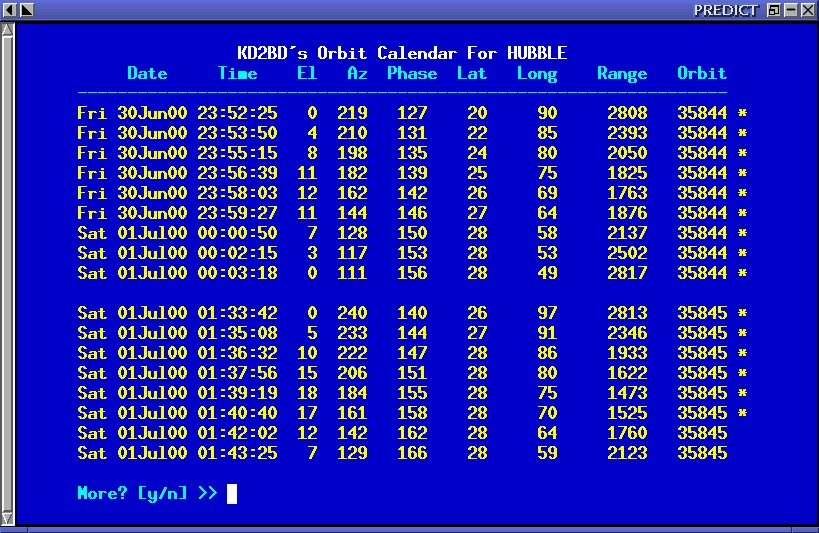
Figure 2.Orbital Prediction Mode
PREDICT includes two orbital-prediction modes to predict any pass above a ground station, or list only those passes that might be visible to a ground station through optical means. In either case, predictions will not be attempted for satellites that can never rise above the ground station's horizon, for satellites in geostationary orbits, or satellites that appear to have decayed in the earth's atmosphere since the last Keplerian orbital data update. If a satellite is in range at the starting date and time specified, PREDICT will adjust the starting date back in time until the point of AOS, so that the prediction screen displays the pass in its entirety from beginning to end. Figure 2 shows the orbital prediction mode of several passes of the Hubble Space Telescope in range of New Jersey in early July, 1999.
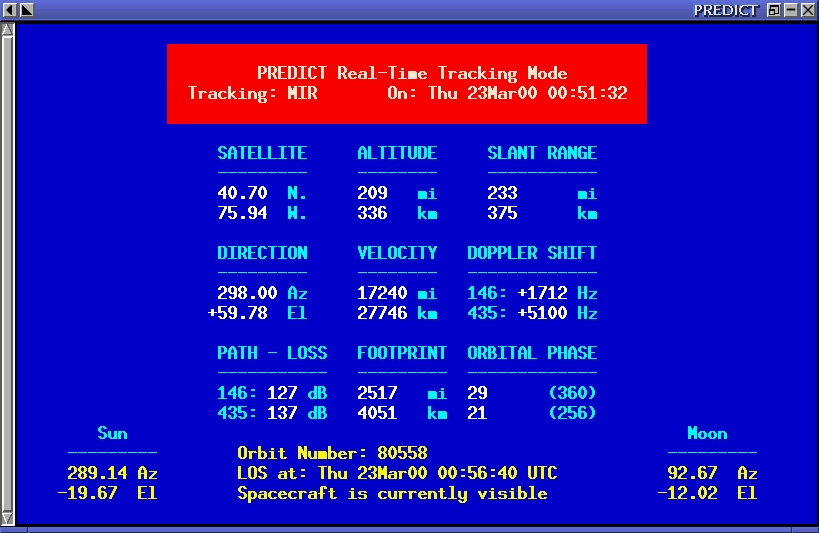
Figure 3. The Single-Satellite-Tracking Mode
In addition to predicting satellite passes, PREDICT allows satellites to be tracked either individually or as a group of 24 using the program's Multi-Satellite Tracking Mode. The positions of the sun and moon are also displayed when tracking satellites in real time, as are the eclipse and optical visibility conditions of the satellites in the database. Real-time tracking data is available to socket-based clients when PREDICT is running in either the single-satellite or the multi-satellite-tracking mode. Figure 3 displays tracking coordinates for a single satellite in real time. Real-time positions for 24 satellites are shown in Figure 4, along with a schedule for upcoming satellite passes. Satellites currently in range are highlighted for easy identification.
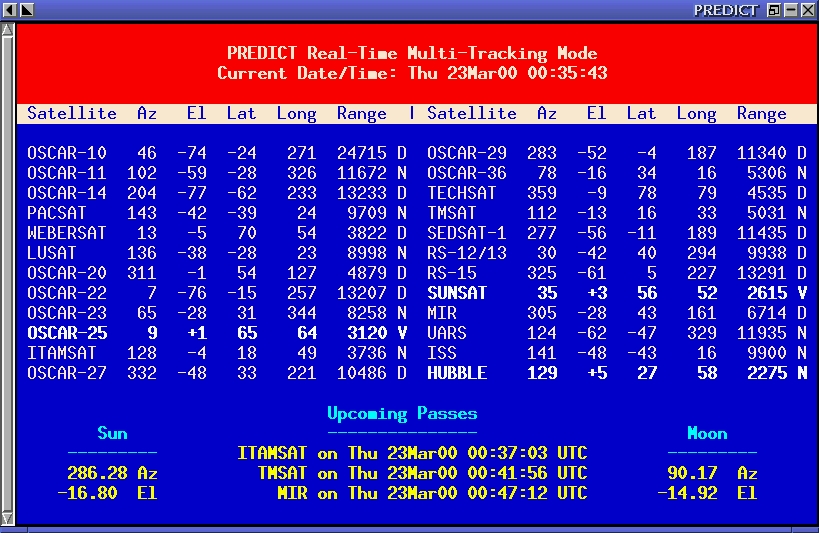
Figure 4. Multi-Tracking Mode
PREDICT was designed primarily to aid in facilitating communication through amateur radio satellites. Nearly 20 satellites currently in orbit carry some form of communication transponder or telemetry beacon intended for amateur radio use. OSCAR spacecraft (orbiting satellite carrying amateur radio) that contain analog transponders relay signals they receive back to earth in real time. Those that carry digital transponders relay files between sender and recipient anywhere on the planet on a store-and-forward basis. Some OSCAR satellites also carry earth-imaging cameras and scientific and educational experiments, the results of which are transmitted by low-power beacon transmitters carried on-board the satellites. Even the U.S. space shuttles and the Mir space station have carried amateur radio equipment into orbit for use by astronauts and cosmonauts working in space. The International Space Station (ISS) will carry a multi-mode amateur radio station for use by astronauts working on the space station. The image of Melbourne, Australia in Figure 5 was taken by the earth-imaging camera on-board the TMSAT-OSCAR-31 amateur radio satellite.
Since none of these spacecraft are in geostationary orbit, some form of tracking and orbital prediction must take place before radio contact may successfully occur. PREDICT provides all the information needed to predict passes of these spacecraft over a particular ground station location, and track them in real time once they have arrived. A graphical orbital-display program operating as a socket-based client of PREDICT is shown in Figure 6. The footprint as well as several consecutive orbits of the Mir space station are shown on the map.

Figure 6. Socket-Based Client Graphical Orbital Display
In addition to providing real-time tracking coordinates, PREDICT also calculates the amount of Doppler shift expected at any given moment during a pass, so that compensation in uplink transmitter and downlink receiver frequencies may be accurately made. Path loss calculations for determining the RF (radio frequency) link budget between ground station and satellite are also provided.
Since PREDICT also tracks the sun and moon in real time, the sky locations of these celestial objects can be used to determine geographical bearings at the user's location. This information is particularly helpful in accurately aligning directive antenna systems to known directions prior to tracking satellites. Since PREDICT also tracks the position of the sun and earth with respect to satellites tracked by the program, spacecraft telemetry can be better analyzed knowing when the satellite being studied has spent considerable periods in sunlight or in eclipse. The Solar Illumination Prediction mode can determine in advance when or if a spacecraft will enter a “solar orbit” and experience periods of continuous sunlight. These periods are also typically the best times for astronauts to plan extra-vehicular activities in space.
Images from weather satellites in geostationary orbit are often seen on television and via the Internet, but a host of weather satellites from the United States, Russia and China in low-earth orbits provide high-resolution images over regional areas. Receiving images from these satellites is a rewarding hobby for many, and PREDICT can provide all the information required for predicting passes of weather satellites and tracking them from horizon to horizon once they have arrived.
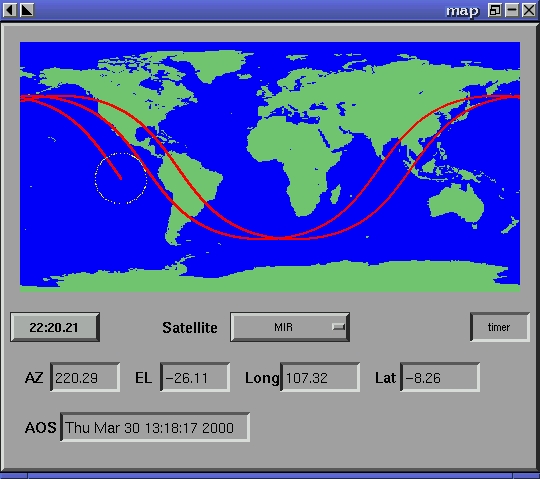
Figure 5. Melbourne, Australia
Finally, PREDICT also determines periods when large spacecraft may be visible in the evening or predawn skies. There are approximately 150 satellites that are classified as being “visible”, all of which can be accurately tracked through PREDICT. Large spacecraft, such as the U.S. space shuttles, the Hubble space telescope, the Mir Space Station (see Figure 7) and the International Space Station are easily seen by the naked eye under the right viewing conditions. The International Space Station will be particularly interesting to watch as it slowly expands with construction scheduled to take place over the next few years. PREDICT's voice capabilities are ideal for relaying tracking coordinates to satellite observers, effectively eliminating the need to read a computer monitor or printout for real-time tracking information.

Figure 7. The Mir Space Station
Development of PREDICT continues on an almost-daily basis after having been released as open-source software under the GNU General Public License last year. Through the development of PREDICT, the Linux operating system has clearly shown itself as being a superb platform for the design, development and implementation of applications relating to science, engineering and education. The free exchange of ideas, the open scrutiny of those ideas among peers, and the constructive feedback gained from such open discussions is not unlike the long-held traditions of the science and engineering fields. This environment will surely contribute to the continued success of Linux, not only in the fields of science and engineering, but in many other areas as well.

John A. Magliacane has been using Linux since 1.1.59. He holds an advanced class FCC amateur radio license (KD2BD) as well as a commercial FCC radio operator's license. His interests include satellite communication systems, Linux software development and hardware design. John may be reached via e-mail at kd2bd@amsat.org, or via the KITSAT-OSCAR-25 satellite.
