
GNOME, Its State and Future
The GNOME Project is aimed at making UNIX attractive and easy to use. To help achieve the goals of the GNU project, we want to make sure that users are presented with a full suite of applications, as well as a desktop that enables them to manage their computers effectively. The GNOME team has been focusing on creating a reusable infrastructure of development libraries and tools, along with productivity applications based on this infrastructure.
The goals of the GNOME Project can be divided into three areas:
a full-featured desktop environment
a set of interoperable applications with a consistent, easy-to-use interface
a powerful application development framework
The desktop environment is not the set of applications, such as a web browser or a spreadsheet, with which a user interacts with the system to do useful tasks; rather, it is the utilities which provide the user with control over the working environment. As the most immediately apparent part of GNOME, the desktop environment includes the file manager, panel and help browser, as well as other utilities necessary for the day-to-day maintenance of one's computing environment.
The GNOME session begins with the GNOME Display Manager which grants access to the system. The beauty of this process is that the author of GDM rewrote the whole login sequence to be secure and extensible. The GDM code base is designed to be robust and secure.

Figure 1. GNOME Screenshot
From there, the GNOME panel and the GNOME file manager provide the desktop functionality to let users launch applications and manage their information see Figure 1).
The GNOME desktop was the first desktop to include application themes. Application themes are a way to make applications look different. People can choose to make their desktop look like other popular systems, or tune it to suit their needs and personal interface desire. The next major release of GNOME will include a new, updated and better integrated theme mechanism, and also theme packages that will affect the entire desktop, not just the applications.
We also integrate the GNOME personal information management system (calendar, address book, task list) with the Palm Pilot, and more systems can be plugged into the system. To learn more about this feature, visit http://www.gnome.org/gnome-pilot/.
Just being able to choose a screen saver, organize icons, browse application menus and move files doesn't mean you are a productive member of society. What users want is a set of applications to help them accomplish actual work. This is where the GNOME Workshop project comes in. Many applications not done by the core GNOME team are available, but would be much more useful if they were integrated with each other and the desktop. The GNOME Workshop project wants to make a set of highly integrated applications to do what you need, whether it is managing finances, writing letters or editing a picture. Components of GNOME Workshop that have already reached a functional state include a highly capable spreadsheet (Gnumeric), a word-processing application (AbiWord), and an image-editing application (the famous GIMP). Other component applications are coming along quickly, and news of their releases will be listed on the GNOME Workshop home page.

Figure 2. Gnumeric and Bonobo
Another important part of GNOME is the development environment. UNIX has not had a history of applications with a consistent and powerful graphical interface. The few graphical applications that existed all behaved and looked a little differently, usually did not have a powerful interface, and were not easy for their developers to write. GNOME addresses this last need by simplifying the development of applications, allowing the creation of easy-to-use and powerful graphical interfaces.
GNOME provides a high-level application framework which frees the programmer from having to worry about the low-level details of graphical application interfaces, allowing him to concentrate on the actual application. Glade, a tool for user-interface design used by many GNOME applications, takes this concept a step further by allowing graphical creation of a program's user interface. The Libglade library allows user interfaces to be created at runtime from the XML interface description files saved by Glade. GNOME also recognizes that not every programming language is useful for every kind of job. We paid special attention to making the GNOME APIs easy to wrap and export to other programming languages, to let people develop their GNOME-based applications in their language of choice.
In addition to C, which the core GNOME libraries are written in, there are bindings for many languages, including C++, Objective C, Guile, Python, Perl, Ada95, Tom, Pascal, Haskell and others. Java bindings are in development; when coupled with gcc's ability to compile Java code, Java may become a viable alternative for GNOME programming.
The objectives of the Gnumeric spreadsheet (see Figure 2) are to include all the features you can find on proprietary spreadsheets. Gnumeric has implemented most of the built-in functions available in Excel 2000, and by the time you read this, it should be complete.
Users can write their own functions in Python, Perl or Scheme, and access them through the Gnumeric engine. This enables people to adapt Gnumeric to their needs. Of course, if you like to use C, C++ or assembly, you can also hook up your functions to the spreadsheet.
We are copying many good ideas and usability features from popular spreadsheets and including them in Gnumeric.
Gnumeric also serves as a test-bed for the various GNOME technologies: CORBA, the Bonobo component and document model, and the GNOME printing architecture. Gnumeric was also one of the first applications that used libxml (the Gnumeric native file format is XML-based).
Gnumeric's rich set of import and export filters make it quite a valuable addition to your tool box, and if you are looking for an application to load your Excel spreadsheets, look no further: Gnumeric has the best Excel importing functionality available for GNU/Linux as tested by LinuxWorld.
Not only can you define your own functions for spreadsheets in the languages mentioned above, but you can actually script the entire application from any language that supports CORBA. Anything the user can do by using the spreadsheet user interface can be done through a CORBA communications channel, enabling you to use Gnumeric as a reusable engine for your applications.
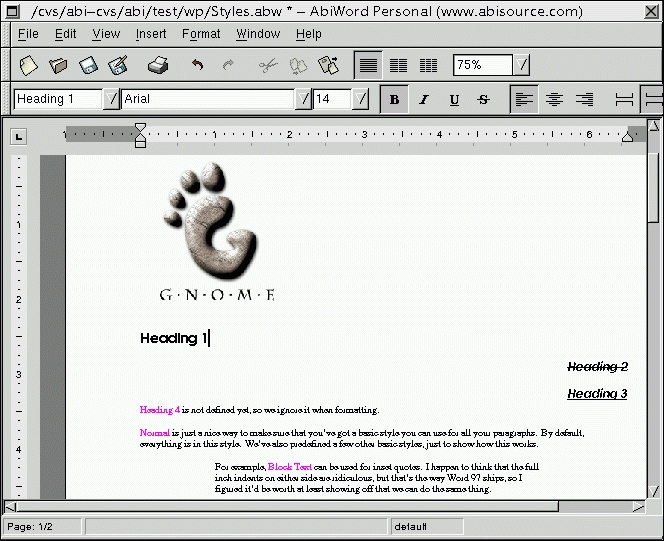
Figure 3. AbiWord with GNOME Support
AbiWord (see Figure 3) is a project led by Source-Gear. It is a cross-platform word processor that can import your Word files. The word processor has gotten attention from many communities, since they can run the same word processor across UNIX, Win32, BeOS and MacOS. Their web site is at http://www.abisource.com/; you can download it from there. Abi contains a number of interesting features found in the proprietary word-processing equivalents.
The GIMP is the de facto standard for image editing, photo retouching, image authoring and composition. It is hard to list all the features, as it is one of the most successful free software projects. The GIMP is among the most actively developed applications, and Yosh Manish acts as its maintainer and coordinator.
Dia is a diagram application that can be used as a replacement for the popular proprietary application “Visio”. Dia supports various kinds of high-level objects for drawing: UML, Network, databases, circuit objects, flow charts and more. Dia is easy to extend with new object collections, as the various objects are defined using an XML-based file format.
It has quickly become the tool of choice for GNOME developers for generating diagrams and communicating graphical information with other developers. The Dia team consists of seven programmers and is commanded by Alexander Larsson. The Dia community is very active.
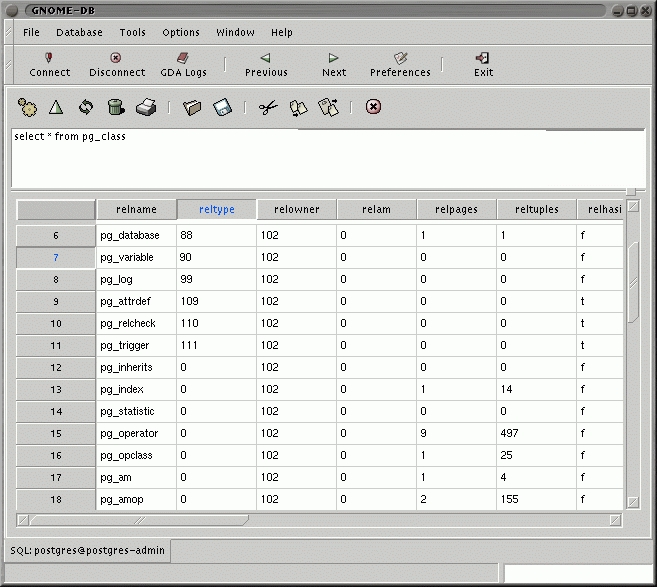
Figure 4. GNOME DB User Interface
GNOME DB (see Figure 4) is a framework for creating database applications. It provides both a common API with pluggable back ends to various database sources, and specialized widgets for handling various database tasks. The back ends, in the typical GNOME tradition, are based on CORBA. Michael Lausch and Rodrigo Moya are the main developers of this project.
GNOME-DB is composed of three separate, independent layers. The lowest level contains the database servers, which are CORBA servers that map the database-specific APIs to the GDA model. The middle layer is the GDA client library, which sits on top of the CORBA interface to allow an easier access from client applications. The middle layer also contains the GDA UI library, which provides a way of easily accessing the client library from GNOME applications. The top-level layer is composed of the applications making use of the middle-level layer, such as the Rolodex application and the SQL front end.
Gill (GNOME Illustrations) and Eye of GNOME (image viewer and organizer) are the most recent additions to the suite of productivity applications for GNOME.
Gill is particularly interesting, since its native file format is the Web Consortium's Scalable Vector Graphics (SVG). Internally, the application has been organized around a Document Object Model (also a W3C standard). Gill is still in its infancy, but given that it is based on a strong foundation, it is already a fairly powerful display.
Eye of GNOME is also in its infancy, but has served as a test bed for various new GNOME technologies: our new imaging system, various new GNOME Canvas improvements and the new model-view-controller-based widgets. It is our image viewer of choice right now and amazingly fast, too.
The lack of a standard, freely available system for component programming is a problem present in the UNIX world today. One of the issues being addressed by the GNOME project is providing such a framework. The GNOME framework is based on the CORBA object model. During the design of the GNOME component interfaces, we tried to address a range of needs:
Automation: allow applications to be remotely controlled. People should be able to launch and control GNOME applications remotely. This is achieved by the GNOME Object Activation Directory (GOAD), the supporting libraries (the GNORBA libraries) and making use of the CORBA facilities for binding CORBA to scripting languages.
Compound document creation: it is important to design and implement the GNOME applications in such a way that they will let the user create compound documents (those with contents that may have been produced by different tools).
In-place document editing: the next step in compound document creation is providing ways to edit embedded documents inside a container application. This means it should be possible to make changes to an embedded spreadsheet document inside a word-processing document in a seamless fashion: it is important to make this integration simple and easy to use.
Component reuse: filters and pipes proved to be important building blocks in UNIX, but they are very limited: the flow of control usually goes in a single direction, and the protocol used to exchange information is too simple to meet today's needs.
Desktop integration: the GNOME desktop deals with CORBA interfaces to services. As far as an application is concerned, only the published interface a program provides is used.
In GNOME, interfaces for specific tasks play an important role. It is up to the user to choose which implementation of those interfaces he uses. For example, the Mailer interface is implemented by the GNOME Balsa mail reader, but it can also be implemented by Emacs RMAIL, Emacs GNUS or the Mozilla mail reader. If any of those provide the CORBA Mailer interface, they will work properly with the GNOME desktop.
All these needs can be met by the use of CORBA, an OMG standard (http://www.omg.org/). We are using ORBit as our CORBA implementation, with very good results. ORBit was designed to be small, fast, robust, reliable and efficient. Many times people hear the word CORBA, and they immediately think “bloat”. This is not the case with ORBit. ORBit is thin: for most applications, the working set of ORBit's ORB is around 30K, which makes it suitable for embedding in almost every application. This is exciting, because applications such as Gnumeric and a few others export their internals to the desktop as highly specialized reusable components (think “UNIX filters on steroids”).
CORBA has proved to be very useful, as we can use it to run regression tests on our applications from a Perl script using Owen Taylor's wonderful CORBA-Perl (people.redhat.com/otaylor/corba/orbit.html). This just happens to be one of our favorite CORBA bindings for a scripting language, but you can get CORBA bindings for almost every language.
By using CORBA as our foundation, we ensure interoperability with existing systems, and anyone who supports CORBA can talk to our applications. CORBA in GNOME plays the same role COM plays in the world of Microsoft Windows.
Bonobo is the GNOME foundation for writing and implementing reusable software components. Components are pieces of software that provide a well-defined interface and are designed to be used in conjunction with other components. In the Bonobo universe, CORBA is used as the communication layer that binds components together. More about component programming can be found in the Bonobo documentation.
In short, Bonobo provides the following features to an application developer:
An infrastructure for creating reusable components as full-blown processes, shared libraries or remote processes.
An infrastructure for reusing existing components. For example, you can use Gnumeric to provide data-entry facilities in your own application or as a computation engine.
An infrastructure for creating persistent controls.
An infrastructure for creating compound documents. This means not only reusing existing applications in a vertical application, but creating single documents composed of various parts: spreadsheets, equations, graphics and so on.
Figure 5. Updated GNOME Screenshot: New HTML Engine
GNOME 1.0 utilized the Imlib software library for image loading and manipulation. While Imlib fits the needs of some applications, its design does not mesh well with the typical GNOME use case. As a replacement, libart, an RGBA image-manipulation library, and GdkRGB, an API to allow high-performance display of RGB images, are integrated together in gdk-pixbuf, an image-loading library that solves the problems of Imlib and adds features such as anti-aliasing and high-quality rendering.
GNOME 1.0 included libart and the anti-aliased canvas, but it was not used very much, and the anti-aliased canvas was marked as unstable. In the future, GNOME will use libart and the anti-aliased canvas much more. The new GNOME panel and GNOME pixmap widget already use libart and gdk-pixbuf to provide anti-aliased icons.
Glade is a GUI designer which is currently being used in much of the new GNOME development. Normally, Glade will generate source code to build the interface you create. However, the truly revolutionary and useful way to use Glade is in combination with Libglade.
Libglade is a library that will load a saved Glade project and build the interface for you—on the fly. This means you could conceivably have different interface files for different languages, application modes or themes. It also gives the user the ultimate power of customization, since the interface of the application can be modified without any programming skill.
Various GNOME applications are now designed with Glade, and this substantially reduces their development time. It is easy to prototype, easy to customize and easy to extend. The joy has arrived.
UNIX printing is both a blessing and a curse, and while it may be flexible, it has always been hard to set up, and output quality was often low on non-PostScript printers. In addition, most applications didn't even include printing support, because no convenient, unified API was available for printing on UNIX. GNOME Print is a library which allows developers to easily add printing capabilities to their applications, and users to quickly and easily access all the output parameters through a consistent graphical interface.

Figure 6. GNOME Desktop, Using Anti-Aliasing
The GNOME Print imaging model is based on PostScript, with two extensions: anti-aliasing and transparency. Please note that I said “an imaging model based on PostScript”, not PostScript. You have the same imaging model, but the way you print is by using an API exported to your favorite language.
Currently, GNOME Print includes a PostScript driver, an on-screen driver (for doing previews), meta-file drivers (for storing printed information, transferring it, and rendering it on a scaled context) and a generic RGB driver (on which we will build the per-printer actual printer drivers).
As you might expect, we do reuse our technologies. The rasterization engine used in the canvas is the same rasterization engine used for the on-screen preview and for rasterizing the output for the native printer drivers. If you are interested in working on the native drivers, we most definitely welcome your help.
The GNOME Project is not resting on its laurels. While the 1.0 release series addresses the basic need for a UNIX GUI, portions of the existing implementation need refinement, as well as additional features which are becoming essential on a modern desktop.
At the same time, the GNOME 1.0 API will still be supported through compatibility libraries, so that the migration of existing source code to the new libraries will be painless. This will allow developers to focus on the application development instead of having to worry about following GNOME API changes.
The file manager is being completely redesigned. The new version will feature an asynchronous, network transparent virtual file system which is usable from all applications independent of the file manager. This will make it easy to have applications that are network aware, and it will make network administration a snap. This step forward from traditional virtual file system libraries, which are not asynchronous, allows better responsiveness from graphical applications.
In addition to the file manager, another highly visible part of the desktop is the panel. It is a place to put icons to launch applications, access application menus, manage open windows and run small utility applications that display the status of the machine, play CDs or display time. We recognize that people are not the same, and different people like to work differently. That is why the panel is highly customizable, and this customization has been greatly extended in the new version. The panel supports many new and different modes of operation. For one, you can select a size for your panels depending on your tastes and screen size. There are also new modes to place panels anywhere along an edge, and even anywhere on screen. In addition, all icons on the panel are now anti-aliased, and external applets have the ability to use anti-aliasing for their display. Many other smaller additions make the panel more configurable and easier to use, and your GNOME experience more pleasurable.
Another noticeable improvement coming to GNOME is GConf, a new configuration API and back end. This will add the features not provided by the simplistic configuration API in GNOME 1.0. It will make it easy to plug in different back ends for the actual storage, so you can change how and where the data is actually stored without touching the applications themselves.
Since many GNOME applications utilize CORBA, a framework for locating and activating these applications is necessary. OAF, the Object Activation Framework, provides a simple method for finding and running the CORBA objects available on a computer system. Distributed operation is supported, allowing activation of objects on a network of computers being used in a GNOME desktop. The flexibility of OAF enables it to be used outside of GNOME programs, allowing non-GNOME CORBA applications to be utilized alongside GNOME applications.
Supporting the various human languages is a complex task, not because of the difficulty, but because of the wide range of communication systems humans have came up with in the last few thousand years.
Since our goal in the GNOME project is empowering users and giving them a chance to run free software, we have to make sure everyone on this planet can use our tools with their language, and that our applications can be used by all people.
Gtk+ is the toolkit used by GNOME and the various GNOME applications. The Gtk+ team led by Owen Taylor and Tim Janik is making steady progress towards the Gtk+ 1.4 release.
The major highlights of Gtk+ 1.4 include flicker-free drawing, better internationalization support (through Pango), and integration of the BeOS and Win32 ports.
Applications written against the Gtk+ 1.4 and GNOME APIs will be portable to Windows and BeOS. (Keep in mind that GNOME/Gtk+ applications talk to a windowing system layer called Gdk, which is independent of X11. This is why it is simple to port them to other architectures.)
The people who brought you GNOME are programmers, and most are not graphic designers. They do not have all the experience required to make the best user interface possible. It is hard to write good user interfaces, and we are trying to address this. The GNOME User Interface team is responsible for redesigning the look and feel of various GNOME applications by studying the current application failures and using what is good from other applications and systems.
GNOME is part of the GNU project, and it is free software (some people call this open-source software), created for the people by the people. We want to make software that grants users various freedoms.
It is not software owned by some large faceless company. You, therefore, are the person best qualified to contribute to its improvement. Although programming help is extremely welcome, you don't need to be able to program in order to help. Documentation, translations, web site maintenance, packaging and graphic design are just a few of the many areas where people are already making contributions. If you dislike an aspect of GNOME and want it improved or want a totally new feature added, the way to make this change happen is to start contributing.
You might think any contribution you could make would be unimportant, but if many people make small contributions, the result is a large increase in the progress being made. Your efforts for GNOME will continue to make the power of UNIX easily accessible to average users.
George Lebl (jirka@5z.com) is an independent consultant in San Diego, California. He has been involved in GNOME since the very early days.
Elliot Lee (sopwith@redhat.com) is a programmer for Red Hat Advanced Development Labs at Red Hat Software.
Miguel de Icaza (miguel@gnu.org) is a programmer at Helix Code, Inc.

