
Source-Navigator Version 4.2

Manufacturer: Cygnus Solutions
E-Mail: info@cygnus.com
Price: Developer Edition $149.00 US, Enterprise Edition $499.00 US
Reviewer: Daniel Lazenby
Whether you are an individual developer creating that dearly needed utility or responsible for a team developing the next Linux killer application, Cygnus' Source-Navigator can add value to your software project. Source-Navigator (SN) is an extendable source code editor, organizer and analysis tool. SN can be used for creating, maintaining, reengineering or reusing code, understanding complex application code relationships or assisting with source-code configuration management.
There are at least two different ways in which this software tool can be used. Let's say you've just received maintenance responsibility for a legacy application with thousands of lines of code. The application's documentation is minimal, and source-code documentation is slim. How can one perform code archaeology to learn about the application's structure, functions, include relationships and other code interdependencies? Converting it into an SN project could go far toward building a foundation for understanding the code. Perhaps you've been assigned the task of managing development of the next Linux killer application. This assignment includes ensuring code reuse, tracking modifications, implementing source-code version control and keeping development teams focused on their portion of the development effort. SN can be used to achieve these objectives. In the next few paragraphs, I will highlight the various tools, browsers and editors that can be used to achieve these objectives.
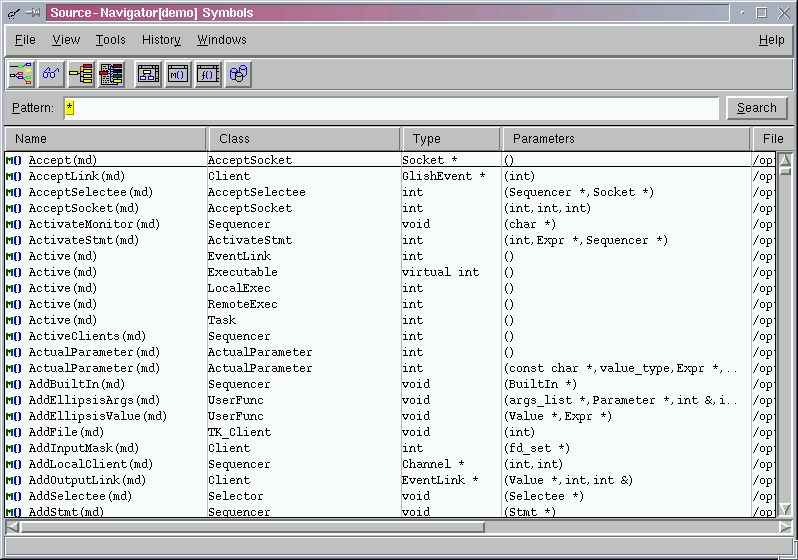
Figure 1. Symbol Browser
Source-Navigator's main work environments are divided into the Symbol Browser and the Editor Window. I think of the Symbol Browser as an overview tool (see Figure 1). Every project opens with the Symbol Browser. This provides a listing of the project's directories, files, methods, functions and classes. It is possible to display lists of virtually any symbol or source files with this browser. A symbol list can be set to display a single symbol or any combination of symbols. Generally, information on symbols is presented as a two- (or more) column list.
Notice the four right-most toolbar buttons. These are labeled from left to right: Class, Methods, Functions and Files. Choosing the File button lists all of the application's files, their file type and location. Selecting the Methods button will list all methods, their class, type and associated file location. The Class and Function buttons provide similar lists of class and function information. The four left-most buttons provide hyperlink access to the Hierarchy, Class, Cross-Reference and Include browsers. With a click of a button, these browsers provide more details about the selected symbol.
I created a software project with some C++ code I had never seen. After spending a few minutes with the Symbol Browser, I had a feel for what classes, methods, functions and files belonged to the application. After spending some more time with this tool, it became clear which classes, methods and functions were contained in which file(s). Having learned these relationships, I found myself wanting to print out a couple of the Symbol Browser's lists. Unfortunately, this release did not offer a print capability from the Symbol Browser.
Burrowing further into application details requires tools for dissecting and mapping specific code, file and symbol relationships. These tools are contained in the Editor Window. This window is the home of the Hierarchy, Class, Cross-Reference and Include browsers. Editor Window browsers are normally displayed as a single window. If needed, a browser window can be split to present two browsers within the same window. In addition to the four browsers, the Editor Window contains two text-pattern search tools and an editor. The Editor Window also includes the ability to look at something previously selected, relationships, files or symbols. These “views” are accessible through a project history list. The project history list is maintained on a per-tool basis. The Editor Window can also be used to set up projects, add and delete source files or directories, and organize and segment views of source files. The Editor window and its major parts are shown in Figure 2.
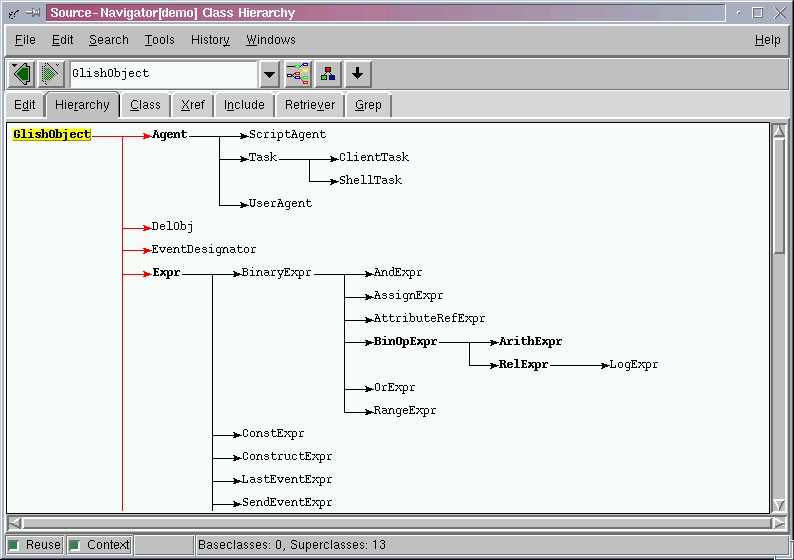
Figure 2. Editor Window
Understanding an application involves breaking the software into manageable chunks. These chunks can take the form of files, objects, code symbols, coding constructs or algorithms. Usually there is some kind of predetermined interrelationship between these application components. The Cross-Reference browser provides a means of graphically examining these relationships in a hierarchical tree format. For example, selecting a function and then the Cross-Reference browser (X-Ref) will display a tree of function calls. This tree can provide a point of view that shows calling functions higher in the tree and functions being called lower in the tree. Selecting the X-Ref browser and a method produces a similar tree, illustrating the variables, methods, classes and functions related to the method. Similar hierarchical trees are displayed when the X-Ref is used with classes. I believe one of SN's better attributes is its ability to diagram relationships.
Some languages allow other files to be included as part of the current file. Examining a file's #include statements provides a backward view of which files are being included in the selected file. Seldom does a file provide a list of files in which it is being included. The Include browser provides both a forward and a backward graphical picture of the various include file relationships. This browser shows which files are included in the selected file. It also shows which files include the selected file. Include relationships can be illustrated by this browser range from a simple one-to-one relationship to a complex many-to-many relationship.
Inheritance relationships between classes and objects are displayed in the Hierarchy browser. Like with the X-Ref browser, this information is displayed as a hierarchical tree. Three hierarchical views can be selected in this browser. One view displays the entire class hierarchy. There is a view that shows only the selected class and its related sub- and super-classes. Another view displays only the selected class and the related super-classes.
The Class browser can be used with either object-oriented or conventional languages (C, COBOL, etc.). This browser uses two window panes to display information. The Inheritance Tree pane displays relationships between the class selected for browsing and any related base or super-classes. A Member List pane lists members of the classes shown in the Inheritance Tree pane. Selecting or deselecting class names in the Tree pane will modify the members shown in the member's list. A member filter is included in this browser. The member list filter provides a way of displaying members meeting specific criteria. For example, the filter can be used to list only methods which have been overridden from a base class.
The included Editor provides typical editing capabilities, plus a couple of other services. The symbol-accelerator drop-down list contains either all symbols in the entire application or only those in the open files. Selecting a symbol from the list advances the editor to the appropriate file and highlights the symbol. SN's hyperlinking feature causes all other browsers to automatically prepare to display their information for the same symbol. If you wish, SN can be told to use your favorite editor instead of the default editor.
SN contains two more features. One is its ability to interface with debugging and programming tools. The other feature is version control support. The Tools Menu provides the Make and Debugger options. Existing projects' Makefiles can be run from within SN. The SN Make dialog box contains a make command field, a working directory field and an output window. Output from the make run is displayed in this window. Any compiler error messages displayed in this window can be used to open the SN editor. After the editor is opened, the cursor is placed on the line containing the error. Command-line compilers can be used with SN. The “Programmer's Reference Guide” provides information on how to integrate command-line compilers.
The GNU Debugger is used by SN to debug a program. Selecting the debugger menu option displays the “Program to Debug” dialog box. The debugger can be started once the program name and working directory have been entered. If you have the correct version of GDB debugger, SN will be able to open and display the source file when a problem occurs.
Managing software projects often involves revision and version control. With version control, one has the option of managing versions, version history, labels and related documents. SN's Edit Menu provides a graphical interface to four external version control systems. Each of these four products has already been integrated with SN. You must have one of them installed on your platform before SN can use it. On the non-commercial side, you can select either the Revision Control System (RCS), Concurrent Versions System (CVS) or Source Code Control System (SCCS). The fourth choice is a commercial version control product called ClearCase. All systems provide the basic checkout with lock, checkout without lock, check-in, check-in with lock, change description, file comparison and discard changes functionality. I'm not familiar with ClearCase. Since it is a commercial product, it may possess additional functionality.
Version control in a distributed environment implies all developers are ultimately checking code in and out of the same code repository. Several techniques for sharing file systems are available. In my current setup, I was unable to review how the product behaves in a shared version control environment.
Printing definitely requires a PostScript printer. Depending on the printer/plotter capabilities, SN can print on several paper sizes. Supported paper sizes range from 8.5 by 11 inches to 42 by 59.5 inches. The print dialog box provides several additional options including image scaling, pagination, paper orientation and print color. Your printer's capabilities will determine which options you can use.
SN Developer and Enterprise Editions are supported on at least Sun Solaris 2.5.1, SuSE 6.0/6.1 or Red Hat 6.0. It is also supported on Wintel platforms running NT 4.0 and Windows 95/98. The Enterprise Edition is also supported on HP-UX 10.20. Literature indicated SN should run on the Caldera Linux distribution. The platform used in this review used the Caldera v1.3 and v2.2 Linux distributions.
By default, the product is installed under the installer's ID in the installer's home directory. An option to install the Source-Navigator product according to your product install conventions is provided.
Source-Navigator is a breeze to install. First, start the install script from within the X environment. Next, enter the desired target installation directory and identify how any problem reports will be sent to Cygnus. The option of installing a demonstration project is offered once the above choices have been made. Any or none of the six demonstration projects can be selected for installation. The tutorial is based on the C++ demonstration project. A dialog keeps you posted on the install progress.
The product installed without problems the first time. On the Caldera v2.2 install, some of the subdirectories and files had UID and GID numbers that were nonexistent on my system. To correct this, I assigned valid user and group IDs to the subdirectories and files.
SN uses a network floating-license scheme to control product access. I didn't find installing the license manager asset-key as seamless as the install guide indicated. I had to manually create the license file to include the asset-key information.
Running the license manager under Caldera v1.3 was straightforward. It wasn't quite as smooth under Caldera v2.2. The license manager wants to place a lock file in /usr/tmp. This directory did not exist in my v2.2 installation. I chose to create a soft link between /usr/tmp and /tmp. This link allowed the license manager to create its lock file. On a side note, the license-manager documentation doesn't recommend running the license manager under the root ID.
Source-Navigator comes with a User's Guide and a Programmer's Reference Guide. The User's Guide clearly presents installation instructions, contains a tutorial on creating a project, and factually describes each of the Source-Navigator browsers. The Programmer's Guide serves as a reference for customizing and extending Source-Navigator functionality. Descriptions and narrations in each of these manuals are supported with screen captures. Where appropriate, sample code is included in the manual.
The Installation Guide clearly presented UNIX system memory, disk, X11 and printer requirements. Comparable Wintel requirements are also given. I found the example of UNIX memory utilization for startup, post-project creation and per open browser informative. The Installation guidance also provided a rule of thumb for estimating disk storage requirements on a per-project basis. The default directory table leaves little doubt as to what directories are being created and the type of files being placed in the directories.
Cygnus uses GLOBEtrotter Software's FLEXlm to manage the SN license. The User's Guide contained virtually no information on starting, stopping or checking the current status of FLEXlm. The only reference I could find about starting this license manager was in the asset-key e-mail. A list of available commands and options is displayed if you enter lmutil at the command line without any options. More can be learned about the FLEXlm license manager by going to the http://www.globetrotter.com/ web site; there you will find a FLEXlm FAQ and a User Manual.
There is a 17-page tutorial introducing project creation and the basic use of each browser and editor. The User's Guide portion of the manual provides more detail on each of the items covered in the tutorial. I found the tutorial worth the time.
Out of the box, SN supports seven languages: C, C++, Tcl, [incr tcl], FORTRAN, COBOL and assembly. An SDK is included with the base product. Using the included SDK, one can modify the graphical user interface, write a new parser to incorporate additional languages, build applications to access the SN project database and implement communications between SN and external applications.
The developer edition is designed for the single developer. This edition can accommodate small- to medium-sized projects. According to Cygnus literature, small- to medium projects are less than 100,000 lines of source code. The Enterprise Edition of Source-Navigator supports work groups and large projects. Projects with more than 100,000 lines of code are considered large. The maximum project size seems to be limited only by disk space and system memory.
Whether doing code archaeology or building the next killer application, this is one of those products that should be in every tool kit. It can provide substantial support, structure and advance software development efforts.
By the way, a fully functional evaluation copy of SN is available from the Cygnus web site. Hopefully, I've piqued your interest enough to download a copy and use it for the evaluation period. It doesn't take long to see the possibilities.
Daniel Lazenby (d.lazenby@worldnet.att.net) first encountered UNIX in 1983 and discovered Linux in 1994.
