
Securing Name Servers on UNIX
The Domain Name System (DNS) is essential to the functioning of the Internet. The DNS organizes the Internet into distributed hierarchical domains. This hierarchical domain structure provides ease of administration and scalability. It must be kept secure.
In July of 1996, Eugene Kashpureff was able to hijack the www.internic.net (Internic) web site to www.alternic.net (Alternic). As a result, visitors to the Internic net site were directed to the Alternic web site. This was done without authorization from Internic. In late 1997, Kashpureff was arrested in Canada. He pleaded guilty to computer fraud in March of 1998. This incident serves to demonstrate the importance of DNS and the impact that a security attack on the DNS could have on organizations that provide services on the Internet. In today's era of e-commerce and “webification” of everything, DNS security is imperative.
BIND (Berkeley Internet Name Domain) is an implementation of DNS. I will describe here the vulnerabilities discovered in BIND and measures you can take to protect against them. I will assume you are familiar with the workings of the Internet and the DNS architecture.
Two major BIND versions are available today: BIND version 4.9 and the BIND 8 series. Most new development of BIND continues on the 8 series. The latest BIND, version 8.2.1, was released on June 21, 1999, and is available from http://www.isc.org/. In the 4.9 BIND series, the latest version of BIND is 4.9.7.
BIND is usually available as part of most UNIX-based operating systems. However, vendors tend to be behind in adapting to the latest BIND version. You can determine the version of BIND provided by the vendor of your operating system by checking the system log files.
The Internet Software Consortium (ISC) sponsors the development of BIND. The latest version of BIND provides many new features and security enhancements. Chief among these are full support for negative caching, the ability to run multiple virtual DNS servers, bug fixes from previous versions and performance enhancements. Table 1 compares some of the primary differences between BIND 8 and BIND 4.9.7. The ISC states the following about the two different streams of BIND:
BIND version 4 is officially deprecated in favor of BIND version 8 and no additional development will be done on BIND version 4, other than for security-related patches.
The risk to a BIND server may arise from a need for a functionality that can leave the BIND server susceptible to attacks, mis-configuration of BIND and vulnerabilities in BIND. The following vulnerabilities/issues in BIND could be exploited.
This vulnerability exists in all versions of BIND prior to version 4.9.6 and version 8.1.1. It allowed an intruder to cause a victim name server to query a remote name server controlled by the intruder. The remote name server would return bogus information to the victim name server. The bogus information would be cached on the victim name server for a period specified by the TTL field of the record returned by the remote name server. Very simply, this attack allowed the intruder to point the victim name server's host name IP address mapping to an alternate IP address of the intruder's choice. Eugene Kaspureff used cache poisoning to divert the traffic from www.internic.net to www.alternic.net.
BIND versions prior to BIND 4.9.7 and BIND 8.1.2 are vulnerable to this. This vulnerability allowed an intruder to gain root-level access on the victim name server, or just cause the server to crash. Earlier versions of BIND allowed the inverse-query feature (see Glossary). Actually, according to the DNS specification, the inverse queries are optional. By default, the servers are not configured to respond to fake queries. However, BIND 8 can be configured to provide fake responses to inverse queries. It is those servers configured to respond to fake queries that are vulnerable. The inverse-query feature code is disabled (commented out in source code) in BIND versions 4.9.7 and later.
BIND version 4.9.7 and 8.1.2 perform better bounds checking than the previous versions. The previous BIND version could be exploited to access an invalid memory location causing the server to crash. A crash leaves the name server unable to answer queries, which is a denial of service.
Slave name servers perform a zone transfer from the master name server to update their zone database. By default, the master name server will permit zone transfer requests by any host. This does not strictly fall in the category of vulnerabilities. However, the name server contains valuable information about network resources. Information such as the host names, number of hosts, textual information on the hosts (HINFO, TXT) and names of mail servers is made available in zone transfers. Hence, it provides the intruder with intelligence information that can be utilized to launch other types of attacks on an enterprise.
Dynamic updates are associated with BIND versions 8 and later only. Dynamic updates do not apply to the BIND 4 series. The dynamic update feature allows authorized hosts to update the zone records of a name server. If improperly configured, an intruder may be able to add/delete/replace the records for a zone.
This falls more in the category of misuse or abuse of the name server by individuals outside your organization. To put it simply, anyone on the Internet can use your name server to perform recursive queries. This can cause your name server to become extremely busy in responding to everyone else's queries. Additionally, everyone on the Internet will be using your bandwidth to do so. Furthermore, this is related to the cache-poisoning vulnerability.
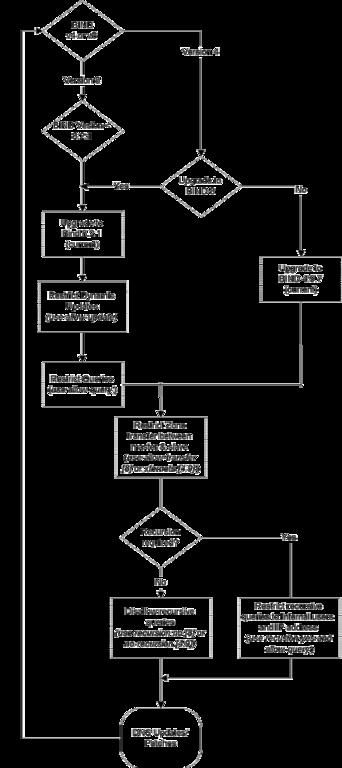
Figure 1
This section focuses on measures that name-server administrators can take to secure their DNS environment on UNIX. Figure 1 displays a flow-chart-based approach to securing BIND. The following measures, when implemented properly, will assist in securing BIND.
The system syslog files contain information about the current version of BIND a system is running. The BIND 8 series provides greater granularity in defining ACLs (access control lists) and configuring the name server. More specifically, BIND 8 series is preferred over BIND 4. Using the most current version of BIND 8 series will protect against the cache poisoning, inverse query buffer overrun and the denial of service vulnerabilities.
BIND provides configuration options to restrict zone transfers. By default, Zone transfer is enabled and anyone can perform zone transfers against the name server database. The ls {domain_name} command in nslookup facilitates this. To restrict zone transfers, use the allow-transfer and xfernets configuration statements in BIND version 8 and 4.9, respectively.
This is necessary to restrict the hosts that can query the name server. In particular, this is useful for zones internal to an organization. Furthermore, restricting queries minimizes exposure to the cache-poisoning vulnerability. By default, BIND permits anyone to query, even for zones for which a name server is not authoritative. Only BIND 8 provides ACLs for queries. The BIND 8 configuration statement allow-query is used to define the ACL for queries based on IP addresses.
If recursion is not desired, it is best to disable it. Such non-recursive servers are responsible for answering queries for the zones for which they are authoritative. In addition, these servers are difficult to spoof because the server does not cache any data. Most often, internal clients send a recursive query to the name server. In such cases, recursion may be desired and must be enabled. Such servers must permit recursion and establish ACLs on queries (allow-query).
Dynamic updates are a feature of BIND 8. By default, BIND 8 disables dynamic updates. If dynamic updates are required, such updates should be restricted to individual IP addresses rather than network addresses. The allow-update configuration statement defines the addresses from which a server will accept updates.
BIND statements such as xfernets, allow-transfer, allow-query and allow-update statements define ways of restricting many features by IP addresses. This type of configuration does not provide any protection if the IP addresses are spoofed. To protect against IP spoofing, network administrators must establish proper IP spoofing controls on the firewalls, bastion hosts and intrusion detection systems (IDS).
Some other measures that can be used to secure the name servers include the use of split-brain name servers and removing unnecessary information from the DNS database.
A split-brain name server consists of two separate name servers. These are quite common in a firewalled environment. Typically, one name server (sometimes referred to as the external name server, outside the firewall) provides information on the web servers, the MX records, other name servers and names associated with any other services offered by a location. The other name server, inside the firewall, contains information on the other name servers in the enterprise. As you can see, the external name server is the interface to the outside world and therefore provides only minimal information. To provide further protection, the external name server can be configured to turn off recursion.
The idea is to differentiate between name servers that permit recursion and those that do not. It is necessary to permit recursion on some name servers so that clients issuing recursive queries continue to operate. In such situations, one name server can be configured with recursion turned off. Such a name server is authoritative for its zone and will reject recursive queries. Typically, this is the type of server registered with the network domain registries. The other name server permits recursion; however, it permits such queries from only a few authorized hosts/networks. This allows only authorized resolvers to query the recursive name server.
Unnecessary data in the name server makes it easier to gather intelligence from the name server. Information such as the names of users and administrators, phone numbers and detailed information about the host's make and model, if unnecessary, may be omitted from the name server database.
BIND normally runs as root. Running BIND as root may allow an intruder to exploit vulnerabilities, allowing them to run commands and read/write files as root. BIND server 8.1.2 and later provide you with the option to run BIND as a user other than root. In addition, BIND 8 also provides the option to chroot the name server. The u and t options to the name server daemon accomplish this.
Significant security enhancements and improvements have been made in the BIND implementation of DNS. At a minimum, install the most recent version of BIND to protect against commonly known BIND vulnerabilities. To further secure your environment, use the security configuration options in the latest release of BIND. Be careful when you apply BIND updates to your environment, especially if you obtain them from the ISC web site as opposed to your OS vendor. Proper care must be taken when applying vendor patches. Often, vendor patches will overwrite the BIND executable and other related files. The result may be a broken or vulnerable name server.
To keep up with the latest developments in BIND, read the BIND newsgroups, periodically check the ISC web site, and review all DNS-related announcements from your OS vendor. BIND 8.2 includes DNS security features as specified by RFC 2065 (DNSSEC, DNS Security Extensions). The DNS security features use public key cryptography to provide data origin authentication and data integrity. Each zone has its own private/public key and uses its private key to sign the resource records. The DNSSEC extensions are currently not widely deployed. Under DNSSEC, the public key of a zone needs to be signed by its parent zone. As of this writing, the Internic does not yet sign the child zone keys.
Finally, it is most important to say that DNS is only a service, meaning you will be able to access a resource if you have its IP address. Your name server is only as secure as the network and other servers on the network. It is thus paramount that you have suitable network and server security measures in place before trying to protect your name servers.
Nalneesh Gaur (Nalneesh.Gaur@gte.net) is a manager in the eRisk Solutions practice of Ernst & Young LLP in Dallas, Texas. He has specialized in UNIX and Windows NT systems, integration and Internet/intranet security issues for a number of years.

