
Builder Xcessory
Manufacturer: Integrated Computer Solutions (ICS)
E-mail: sales@ics.com
URL: http://www.ics.com/
Price: $250 US for personal-use license
Reviewer: Robert Hartley
Builder Xcessory (BX) is a mature, high-end, object-oriented-based UNIX GUI development tool for Motif and Java, released just over a year ago for use on Linux. Along with Code Fusion from Cygnus, BXPro won Linux Journal's “Editors Choice” Award for Best New Application: Software Development in 1999.
In addition to highly intuitive widget layout, BX allows the developer to:
Build components by grouping widgets together and making them into primary classes, with their own methods and data interfaces, without the need to compile them into separate shared libraries for placement on the palette.
Implement well organized ways to apply styles for a consistent look and feel. Many organizations such as government and military subcontractors have their own strict standards for how a GUI should look, declaring their own font, color and other conventions for particular systems.
Transparently keep code intact while the GUI is undergoing evolutionary changes. Callback code is not lost when changes to the GUI are made.
Invoke and use standard development tools, such as Code Fusion, Purify, CVS, SGI Developer Magic and others.
Add new components and widgets on the palette and use them “live”.
Develop C, C++, ViewKit, UIL and Java applications, using industry-standard Motif and Lesstif.
Builder Xcessory is the finest X and Motif GUI development tool available today for OOD/OOP developers working in C/C++ and Java, with enterprise development tools in the works, including other GUI APIs. For application frameworks, it allows the use of ViewKit and a MotifApp-based C++ class system, in addition to straight C for those maintaining legacy applications.
ViewKit is ideal for C++ and Motif work, but for the platforms on which it is not currently available, the MotifApp-based C++ framework provided runs like a charm when used with either Motif or LessTif. I found this especially helpful while porting Motif applications to the Rebel NetWinder, since its ViewKit port is still in the works at the time of this writing. One advantage to using the free Lesstif libraries, when Motif is absent, is that source is compatible across all UNIX/Linux-based X11 platforms.
Running various window managers does not affect the operation of the builder, as it has the Motif libraries statically bound, which also means it can be run without having Motif installed at all.
The Linux version of BX does not mess around with licensing daemons, using an encrypted license string instead. As of this writing, BX is available on Linux for $250 US for the personal-use license.
In addition to the comprehensive hard-copy manuals, all documentation is installed locally in HTML format and is easily invoked from the help menu. The manuals also have complete tutorials, describing in detail the steps needed to make use of each feature of BX. Tutorial data files and example code abound, and updates are freely available via the ICS FTP and web site.
As with most other GUI builders, it takes very little effort to implement what is referred to as the façade design pattern.
Modeling a complex object in a class, providing simplified access functions or methods to control it, and then using the GUI interface to view it allows us to make use of the Model View Controller (MVC) concept. This means we could, at any time, convert our program to a CORBA-type distributed application. Simply by substituting a method invocation on a CORBA-based object from within our GUI's event response routine, referred to as callbacks in X parlance, we now have a modernized distributed application. Keeping our GUI only loosely coupled to the data means we have little or nothing to update when changing how the back end of our application is implemented.
BX is a true WYSIWYG GUI builder. It will allow you to add widgets and components to other widgets and components intuitively. As you build up the GUI, the design tree reflects the widget hierarchy. This is more intuitive than other systems, where a widget is added onto the design tree and the widget placement appears on the screen. It is much more natural to interact with the widgets directly without this level of indirection. BX will also interactively show what happens to the window contents as it is being resized, making manipulation of Motif's more complex container widgets a breeze to configure.

Figure 1. Illustration of widget constraint settings for a push button inside a form widget
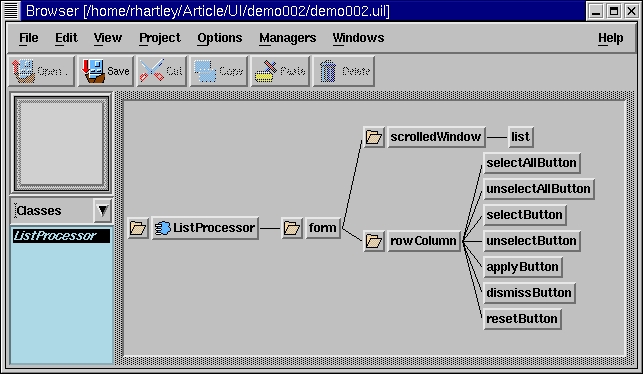
Figure 2. Browser window with sample widget tree displayed

Figure 3. Sample GUI as it can appear in the builder
Each Motif widget has its own list of resources which can be set using the resource editor. This allows for setting resources not related to geometry, such as fonts, colors and various callbacks.
There are a number of options for displaying which resources are viewable. As can be done with all of the BX menu items, the “View” menu shown in Figure 4 has been “torn off” and displayed in its own window, making for a more efficient workspace. If the user has selected the “All resources” option, there can be more resources potentially available for viewing than what is easily scanned through. BX provides a resource finder that allows the user to enter a search string, and any resource containing it will be scrolled to and highlighted, as shown in Figure 5.

Figure 4. View Menu

Figure 5. Search for Word “font”
The styles manager in BX allows us to apply pre-set values easily to the resources of any number of widgets. Suppose, for example, we wanted a pushbutton with a label indicating “Dismiss”, a bold font, with a black foreground and a somewhat olive-colored background; we could use the style editor as shown in Figure 6. Saving this style to a DismissButtonStyle, our style hierarchy tree would look like Figure 7. When we create a pushbutton and apply the style, it would look like Figure 8.
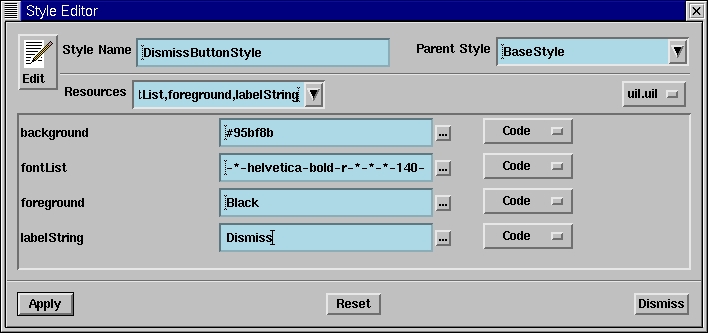
Figure 6. Style Editor

Figure 7. Hierarchy Tree

Figure 8. Push button in Defined Style
In addition to being able to apply styles to multiple widgets at once, styles can easily be made shareable so they are available to other applications being developed.
BX has two modes of looking at widget hierarchies: class and instance. Class mode indicates what the predefined appearance and behavior of a component will be, in effect defining new types. Instance mode tailors them for a particular widget or component, so we can tweak what makes them different from others of the same type.
From the most general class, we can define more specific sub-classes, each time progressively getting more refined or changing and overriding things as we go along.
To save time redesigning our standard layout, we can join a number of logically related widgets together into a single entity by turning it into a class. This makes reuse a snap, since all newly created classes get added to the palette.
To create a class containing one or more widgets, select the highest-level widget to use, then select the “Make Class” menu option. In the previous widget tree containing a form widget with a few buttons and a scrolled list, I performed the “Make Class” operation, and now have a new component called ListProcessor which I can treat as a stand-alone component. It is much more than a simple widget, because we avoid having to delve into the depths of Xlib, Xt and Motif, remaining at a relatively high level without ever giving up control of any of the underlying widgets.
In class mode, we can use the widget class tree to select which resources to expose, giving us a simplified means to control our newly created component without the clutter of having to view every resource of every widget it contains. As a convenience, any resources flagged as “exposed” have set type methods defined, so we don't have to worry about the exact Motif name for widget resources and the functions to set them.
New class methods (functions and procedures) and data can be added easily when we select the class entity in the browser. Our resource editor puts us into class edit mode automatically when we click the “New” button to add data or methods. (See Figures 9 and 10.)
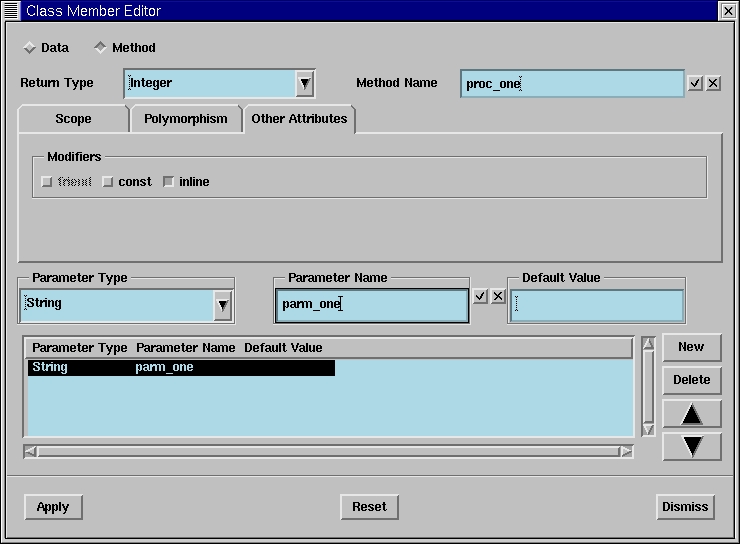
Figure 10. Adding New Class Methods

Figure 11. Resource Editor
Our resource editor now appears as shown in Figure 11, with the new entry inserted. We can now select the “Edit” button, and if needed, our source code will be generated before whatever source editor is brought up. At this point, we can look at our code with the cursor placed automatically on the line where our function starts.
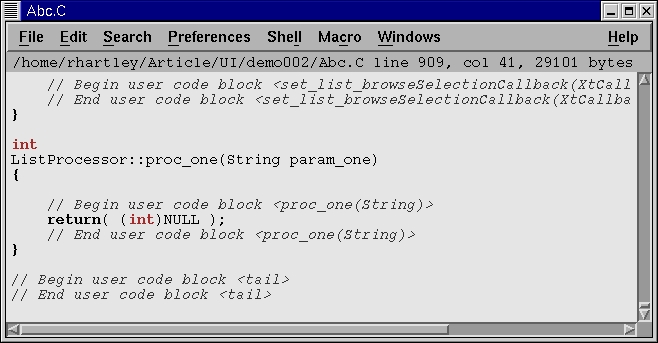
Figure 12. User Code Block
One thing we notice from the snapshot in Figure 12 are the “user code block” begin and end comments around the user code blocks. Anything between these can be modified by the programmer. BX reserves the right to make changes outside of these user code blocks, but will otherwise not interfere. BX avoids clobbering user-written code by scanning for and skipping over sections that are reserved by the developer. At the beginning of a project, these are empty lines bounded by the comment delimiters. Throughout the BX-generated code, these comment blocks will be found before, during and after any major code operation. This may seem superfluous to the new GUI programmer used to having only callback code stubs generated, but they can be a big help in tweaking final production code for major systems.
Until recently, Douglas A. Young was a principal scientist at Silicon Graphics Inc. (SGI). He has written a number of books on Motif development and is the most-quoted and read author on GUIs, having specialized on Motif in particular. His Object-Oriented Programming with C++ and OSF/Motif remains a much-cherished classic. In it, he develops the MotifApp GUI application frameworks, which have matured into the ViewKit product, originally available from SGI but now free on Linux, and commercially available for other UNIX platforms.
To understand what is meant by the “Doug Young method”, we need to look at the choices available to an application framework developer wanting to create an OOP framework using a GUI API based on a non-OOP language, such as Motif.
In some ways, Motif is an OO package. It uses inheritance to create new widget classes based on old ones, passing data and methods down from a super class to a newly derived subclass. Since it is written in C, some marshaling code is needed to overcome language features present in true OOP languages like C++. Gtk+ uses many of the same concepts, since it too is written in C, so the strategies here hold true for Gtk+ as well.
Doug Young's observations about using C++ and a C GUI can be paraphrased with his three strategies as follows:
Our first option is not to use the OOP features of C++, simply using the compiler's stronger type checking. This, of course, will disallow us the greater advantages of using C++ and OOP.
Our second choice is to encapsulate each and every widget into C++ wrapper classes. Although this may provide some aesthetic appeal, it obfuscates the fact that adding extra marshaling code to obtain derived Motif objects is not true OOP, and can induce a performance hit compared to straight C. We cannot simply create a subclass of a C++-wrapped widget and expect it to work properly, since this would extend only the wrapper class and not the widget itself. In order to have an entire OOP widget class hierarchy, we need to have our widgets written in an OOP language from the ground up, the way the Qt widget set does.
The third and most natural approach to using C++ with a C GUI API is to create high-level components composed of (instead of derived from) collections of GUI widgets. All programmers make use of this functional, instead of object, approach at one level or another, as we have yet to see an entirely OO CPU make it to widespread use. Even things such as the Java machines on a chip are, at some microcode level, non-object-oriented machines.
The ViewKit application frameworks, the commercial descendent of MotifApp, have been developed using this third approach.
To make things more intuitive, ViewKit has a feature called VkEZ, which is comprised of a header file and a library. Instead of forcing a programmer to use a number of Motif functions directly, VkEZ overloads many of the assignment operators, at the same time adding some extra helper functions. Examples of this include the ability to assign strings to text and label widgets directly and easily using the “=” operator. Although this may help get an initial version of a program up and running, it is usually the case that the VkEZ functions are replaced with their counterparts in the way of direct Motif function calls.
Robert Hartley can be reached via e-mail at rhartley@srougi.com.

