
The Collaborative Virtual Workspace
You walk down the hallway and go into the design room. It's as hectic here as always; stuff is lying all over the floor. Alex, the lead architect, is here with two other designers, Brad and Lynn. They have been discussing the architecture for the new project.
“I think we've almost got it,” says Alex, “take a look at our design.” He hands you a document, which you duly examine.
“Not too bad,” you reply, “but you might want to look at something.” You walk over to the whiteboard and draw out a rough sketch. Brad sees where you're heading, grabs a marker, and adds some components to your drawing.
Lynn notices a problem and says “We may have some problems implementing the security interface with that. Let me give Rachel in security a call.” She grabs the phone, and after a quick conversation, tells everyone the impact the security team sees from this implementation.
“Okay,” you say, “sounds like you guys are on the right track. I'll carry this preliminary design over to the programmers and get a rough estimate on the time they'll need to implement it.” As you walk out, you notice your beeper has a message from your secretary reminding you of a meeting at 3:00 with the division head.
Activities like these occur in work environments every day; however, in this scenario the individuals involved never physically moved. In fact, one person sits down the hall from you, another works at a remote site, and the third was at home. Yet everyone was able to interact as though individuals, objects and documents were physically colocated.
As computers move to take a dominant position in the workplace and at home, the interactions between people change significantly. Instead of gathering around a water cooler or at a small cafe, meetings have moved to the Internet. However, with this change of venue come certain restrictions. No longer can you read a person's body language or infer meanings from the tone of someone's voice. With many Internet collaboration tools, such as Internet Relay Chat (IRC) or instant messengers, you can only interpret the words others type.
The project on which I currently work, the Collaborative Virtual Workspace (CVW), looks to add more meaning to computer-based social interactions. Instead of relying solely on spoken words, CVW adds actions, audio and video, and a more descriptive virtual environment to social settings. Additionally, users within the CVW environment can create and pass around various artifacts, such as documents and pictures. This is because CVW implements a persistent storage mechanism in conjunction with the environment. Anything created within CVW can be saved for others to see whenever they like.
Best of all, CVW is freely available. To further encourage innovation in collaborative systems, The MITRE Corporation has made CVW an open source software product. By disseminating CVW in this manner, different communities can begin to experiment with and understand synchronous computer-based collaboration. We believe collaboration systems such as CVW will continue to evolve, and the Internet community will have much to offer.
Let's look at where CVW comes from and what makes up our virtual environment.
From it's inception in 1994, CVW was built on a client-server architecture. At the heart of the server is a MUD, Object-Oriented (MOO) from Xerox PARC (ftp://ftp.lambda.moo.mud.org/pub/MOO/). Once only within the domain of dungeons and dragons players, MUDs and MOOs have progressed to incorporate numerous social settings. Although providing a very descriptive environment, MOOs present one challenge to the average computer user today—they are predominantly text driven. With no fancy graphic interfaces or elaborate designs, a user simply connects to a server using a MOO client program or telnet, logs in and begins interacting within the environment.
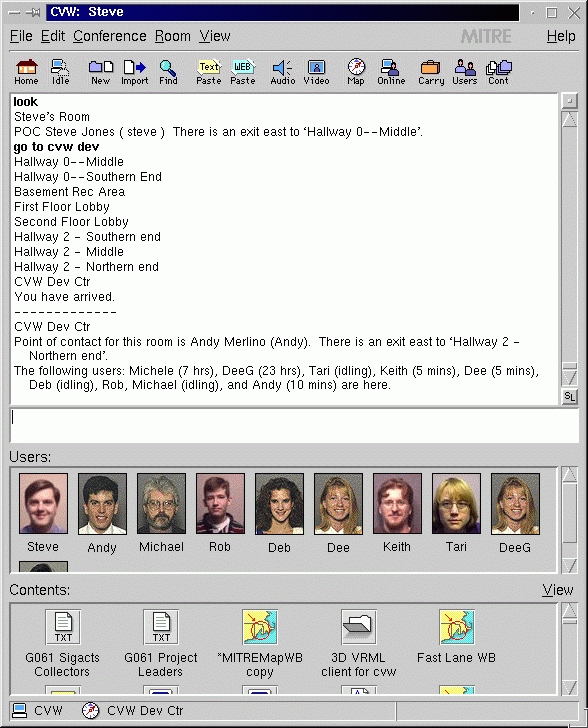
Figure 1. Room Screenshot
One of the true strengths of a MOO server is its extensibility. The server contains an object-oriented programming language called “MOO”. Using the MOO language, programmers can create new rooms, implement new actions, and provide various means of interacting with others within the virtual environment. Add the ability to allow a large number of people to connect simultaneously, and it's easy to see why MOOs have become a popular collaboration environment.
If you download the LambdaMOO source code and run it on your Linux box, you'll notice not much exists in that environment by default. Each MOO administrator must either build a new virtual environment, or obtain the code someone else has written.
CVW's MOO server already contains the code for our virtual environment. We have extended our MOO server in order to create a large building, the floor plan of which displays graphically in the client. Although this tightly couples the client to a CVW server exclusively, it does provide a more intuitive interface for new users. The building consists of several floors, each with seven rooms and various other meeting places (hallway, lobby). These can be modified to suit any group's needs.
Using a room-based metaphor provides two other distinct advantages. First, session management can be logically partitioned. Each room will administer the particular session requirements for the users in that area. By having this controlled at the server side, any clients connecting to the server do not have to configure their audio, video or document settings to communicate with the other users. Secondly, security can likewise be easily controlled. As each room may implement an individual access control policy, private meeting places can be created. Again, this provides a very intuitive means of implementing security—if the server denies a user access to a room, they usually understand they don't have permission to enter that area.
In addition to the MOO server, we incorporated document persistence into our collaboration system. This allows CVW to encompass the role of a collaboration framework. If individuals meet to discuss a topic, they may create documents or graphics using whatever tools that may be available to them (document editors, drawing programs). Using CVW, users can import these external documents and allow others to view or edit them. Although MOOs do allow users to create objects, these are normally simple text documents that can't be easily exported to other external applications. This persistence capability allows for asynchronous collaboration—users may enter or leave the room whenever they desire, but they would still have access to the work being performed.
Since the addition of persistence incorporated a significant change to a MOO environment, we implemented this functionality as a unique server process, the Document server. This server does not have to run on the same machine as the MOO server, but it should have enough disk space available to store all the documents created by the users. Storage of documents is quite simple—basically, a flat database directory. To date this has proven sufficient, but a large implementation of CVW may want to look to re-engineer this process.
The first step in creating a CVW environment is to obtain and install the CVW MOO server and document server software. If you browse the web site (http://cvw.mitre.org/) you'll find both a binary and a source build available for downloading. I'll step through the binary release installations, although the source releases require only a few more steps. Both downloads include detailed documentation, so I'll only highlight the important steps and try to point out any possible stumbling blocks for getting the server running.
As for system requirements, the size of your CVW system depends on the size of the virtual community you wish to build. My Linux system contains a Pentium 300 with 64MB RAM running Red Hat 5.1 and a 2.2 kernel. Although we haven't tested this configuration under a load, it should suffice for 40 to 50 simultaneous users at a minimum. We have seen over 250 users simultaneously on a Sun Ultra 2 dual-processor machine, so an appropriately configured Linux workstation should perform likewise. Additionally, the server running the document server process requires installation of the Java 1.1 JRE.
During the CVW software download process, after accepting the license agreement you'll be asked for some personal information. MITRE is a not-for-profit organization, and as such, does not use advertisements or sell user lists to other organizations. Our only reason for maintaining a user list is to inform you of any changes in the software and any other activities that might occur with the CVW software.
To begin installation of the CVW server, download the two binary packages, cvw-moo-server-3.2.0-x86-Linux2-libc6.tar.gz and cvw-doc-server-3.2.0-any.tar.gz, and place them in a temporary directory. Extracting these packages using the command tar xvzf package_name will create separate directories with the required binary files.
I decided to make /opt/CVWserver my installation directory. Before creating this directory, create a user named “cvw” on your system. This user will be the owner of the installation, so the binary won't execute as root. Although we haven't discovered any real problems running the software as root, this tends to be a good rule-of-thumb. After creating the user, make your installation directory using mkdir and assign your cvw user as its owner.
Move the following files into your installation directory from the moo-server binary directory—the moo executable, the restart script and the CVW.db file. If you like, you may rename CVW.db to something that better describes your environment. The name you choose doesn't matter, but you need to remember it, as you will be using it later on.
The Document server also requires a document repository. This repository directory must be large enough to store all your documents within CVW. Depending on your potential use, you may create a directory under the server directory you just created or mount a separate partition on your system. I created an /opt/CVWserver/docstore directory since I expected to have a small number of documents. You could also create a /docstore directory and mount another disk to it. The route you take depends a great deal on your projected use.
Next, the document server requires files to be installed from the document server binary directory. Move docserver.jar, docserver.cfg and the start-dserver script into your installation directory. You will need to modify docserver.cfg to point to your document repository. Finally, change all file ownerships within the installation directory to be owned by the cvw user.
To start the processes automatically when I boot my system, two init scripts have been provided. These include cvw.boot for the MOO server and cvwds.boot for the docserver. Move these scripts to /etc/rc.d/init.d and edit them for your personal configuration. By default, we use 8888 as our MOO server communication port and 8889 for the docserver; if any other programs on your system use these ports, change the numbers in the scripts to an unused port. Links can then be created from /etc/rc.d/rc3.d/S99cvw and /etc/rc.d/rc0.d/K99cvw to cvw.boot, and also /etc/rc.d/rc3.d/S99cvwds and /etc/rc.d/rc0.d/K99cvwds to cvwds.boot to allow the startup and shutdown to occur automatically. To start the processes manually, simply type:
/etc/rc.d/rc3.d/S99cvw start /etc/rc.d/rc3.d/S99cvwds start
To test whether the server processes are operational, a TELNET session can be used. See Listing 1 for information on running these tests.
To present your users with a complete CVW experience, you'll want to build a repository of user images. These images will be presented on the client software as the users move from room to room to allow a virtual “face-to-face” feeling. The user images should optimally be 50x60 dpi gif images (although other sizes should scale within the client) that may be stored in one of two locations. First, if you have a distributed file system (e.g. NFS), the images may be stored there to allow for global access. The second option is to make the images available from an HTTP server. In either case, as long as the image repository is globally accessible, the client software can be configured to find the images.
Now we need to get a client. Since many computer platforms normally exist within any given area, we've built client programs that run under Unix platforms as well as Microsoft Windows. Even though users may prefer to work on different systems, they can still collaborate using CVW.
Two versions currently exist that can run on a Linux system: the original Tcl/Tk client and a newer Java client. Both are available in source distributions, but only the Tcl/Tk can be downloaded as a binary. Additionally, only the Tcl/Tk client can support administration functions, although we hope someone will want to fix this soon. For this reason, I'll discuss the installation of the Tcl/Tk binary distribution. However, I will touch on the Java source distribution later.
Download the Linux client distribution and save it into a temporary directory. For the Tcl/Tk client, retrieve the package named cvw-tk-client-3.2.0-x86-Linux2-libc6.tar.gz. Move to the directory where you want the client software installed, then run tar xvzf package_name. In addition to the client software available from our web site, several tools can be obtained from other sites. These include vat for multicast audio-conferencing and vic for multicast video-conferencing originally developed by the Lawrence Berkeley National Laboratory (www.lbl.gov). Currently, we don't include these tools because we don't have permission to redistribute them. Once this hurdle has been cleared, we hope to include everything within the client package.
Another important configuration step for the client is to modify the mime types. CVW uses a simple mime lookup to associate file types with their parent application. This file can be found in the installation directory under lib/mime-db. To add new mime associations, simply provide an application to open a given document type for both reading and writing.
The README file fully details the remaining configuration required to connect to your CVW server. Once completed, executing bin/xcvw from your installation directory will start the application.
A default login of “User: admin, Password: admin” will allow you to log into your CVW server and CVW. After snooping around for a minute, you need to accomplish a couple more configuration steps.
The “Admin” menu on the main menu bar provides access to the system administrator functions. Open the “System Settings” menu selection and provide the requested information. Note you should provide a multicast prefix that will not interfere with other multicast users on the network. Multicast prefixes can range from 224.0 to 239.255.
Before proceeding with commands you can use in CVW, I'll describe more about your virtual user. Individuals will usually be assigned a normal user within CVW. This user has the ability to do a variety of things: move around the environment, create and read objects, place objects in a room or carry them along in a carrying folder, and communicate with others within the MOO. The users may also modify their description to personalize their appearance to others. Additionally, a user may be made the owner of a room, allowing him or her to modify the access list and the description of the room.

Carrying Folder
A user can be given additional privileges to become a programmer within the CVW environment. Although CVW doesn't recognize a programmer as having additional capabilities, a programmer can modify code and create objects within the MOO environment.
The CVW admin is the analogue of a MOO wizard. In other words, this user has the most capabilities within CVW. The admin has the ability to: create rooms and users, modify objects, assign privileges, and configure the CVW environment. Although admin capabilities can be assigned to anyone, it's advisable to limit the number of people having this permission.
After logging into CVW, you enter a building with several floors. On each floor, you'll find eight rooms and connecting hallways. Unless permissions intercede, you may move freely around the building. You may also pick up and examine objects that exist within CVW.
Now let's try it out. For the following examples, enter the MOO commands in the input window just below the scrolled text area. To find both extra information and examples, use the help command, either alone or in conjunction with the command you want to use:
help say
First, to speak to everyone currently in the room, use the say command:
say Hello, WorldYou may also direct speech to a particular person. Although others may see this conversation, the receiving party will notice you are directing the conversation to them.
to admin HelloFinally, to communicate privately so no one else sees the communication, use the whisper command, or if the user is in another room, the page command:
whisper Hello to admin page admin Hello page admin !HelloThe last example displays a pop-up to the admin user. This command makes your comments more noticeable to the receiving party.
As in everyday human communications, actions sometimes speak louder than words. MOOs by default allow for these kinds of communications. Called an emote, a user may let their actions speak for them:
emote types furiously at the keyboard
Shortcuts for many of these commands can be found on the user images. By right-clicking on a user image, you will find a pop-up menu with several communication methods, along with an information selection. This menu will generate directed communications with the selected individual that can be seen by everyone.
Two other popular communication methods supported within CVW are audio and video. CVW implements these capabilities by tying in two common mbone tools from the Lawrence Berkeley National Laboratory: vic and vat. To launch these tools, press either the Video or Audio button on the top toolbar. You will notice no configuration will be needed to initiate conferences with anyone else in the room. CVW automatically handles session management tasks. Naturally, your Linux kernel will need to support the audio and video drivers necessary for your particular hardware to use this functionality.
You may not always be able to converse with others over CVW, either because you're away from your desk or busy on something else. CVW provides commands that allows you to let other users know you're unavailable:
idle gone fishing busy working on project proposal
CVW provides two methods for moving between rooms. First, you can use the navigation commands (north, south, east, west, up, down) to simply direct where you would like to go. The go to command can also move you automatically to your destination:
go to CVW Help DeskHowever, you may have noticed the CVW map button. Clicking on this button will open a separate window with a blueprint of your building. This map will also allow you to navigate around the building. You can choose the floor you wish to see by using the slide bar at the bottom of the window, and double-clicking on a room allows you to move quickly between rooms.
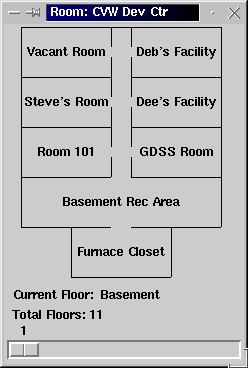
Figure 3. Building Map
Once in a room, objects currently residing in the room will be listed in the Contents window. Some of the objects you'll find include folders, documents, whiteboards and URL links. Menus for these objects can once again be found by right-clicking their icons. Options normally found on these menus will allow the user to view, copy, make a shortcut (link) or delete a document depending on the user's privileges for the item. You may also take objects from the room, which will move them to your carrying folder, and also drop items from the carrying folder back into the room.
The CVW client will allow you to perform many more actions with documents and people. These include importing and exporting documents, getting a listing of people connected to the server, finding particular people or items, and even creating groups of people to make communication easier. Rather than stepping through the myriad of options available (which can take four hours to teach), I'll instead point to our user-guide, CVW 3.0 Unix Client Quick Reference Guide, which can be found at our web site.
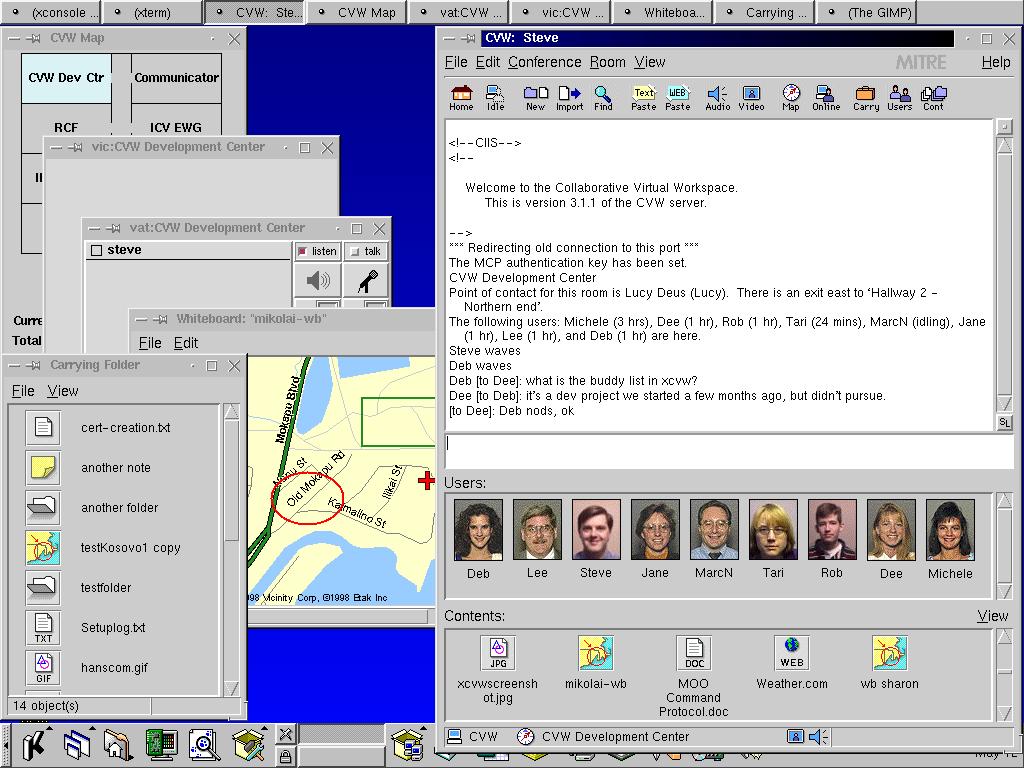
Figure 4. CVW Screenshot
As I mentioned earlier, a Java source client also exists for CVW. This client uses the Java 2 port recently released by the Blackdown organization (http://www.blackdown.org/). Although this client does provide some newer and more advanced features and also works on Linux, it can be considered a beta-release and requires some bug fixes. We do believe, however, this client will eventually become the standard CVW client. We hope that many users will find it interesting and build it up to match the capabilities of the Tcl/Tk client.
Some investigation into replacing the document server has begun. Although the current server performs sufficiently, it has several drawbacks: the interactions between the client and server can't be made secure, the repository consists of one large directory, and no real authentication mechanisms exist. We hope to address these issues with a new document server that provides greater capabilities and performance.
Since CVW has been made into an open-source project, MITRE will be concentrating more on developing a next-generation collaboration system. We hope many people will find CVW as useful to them as it has been to us and continue to improve on it. Since it is a relative newborn as an Internet project, many development possibilities exist. We hope CVW will continue to expose many people to the possibilities of computer collaboration.
Stephen Jones currently works as a software engineer for The MITRE Corporation. When he's not out on his Harley, he enjoys hanging out with his wife Lynn, two-year-old computer-fiend son Bradley, and new arrival, son Derek. He can be reached via e-mail at srjones@mitre.org.

