
Open Database Connectivity
Open Database Connectivity (ODBC) is an open specification for providing application developers with a predictable application programmers interface (API) with which to access data sources. Data sources can be just about anything, provided someone has created an ODBC driver for it. The most common data source is an SQL server.
The two major advantages of coding an application with the ODBC API are portable data access code and dynamic data binding.
The ODBC API (or CLI, command-line interface), as outlined by X/Open and the ISO, is available on all major platforms. Microsoft platforms include many enhancements to this specification. The current version from Microsoft is 3.51. The idea is that a programmer using the ODBC API is likely to have data access code which is portable to other platforms. The same code will also be portable across different data sources. For example, data for an accounting program application can reside on a light SQL server during development and then be moved over to a heavy SQL server just by linking to a different ODBC driver. ODBC delivers platform and data source portability.
Dynamic binding allows the user or the system administrator to easily configure an application to use any ODBC-compliant data source. This is the single biggest advantage of coding an application with the ODBC API and purchasing such an application. Dynamic binding allows the end user to pick a data source, e.g., an SQL server, and use it for all data applications. Applications do not have to be recompiled or recoded for the new target data source. This is achieved by the ODBC Driver Manager which will pass the ODBC calls to the user's ODBC driver without the need to relink the code. ODBC enables the user to choose where the data will be stored.
The unixODBC Project's goals are to develop and promote unixODBC as the definitive standard for ODBC on the Linux platform. This is to include Microsoft extensions, where they make sense, and GUI clients. The unixODBC team is achieving this objective by providing the best technical solution to ODBC demands on the Linux platform. All unixODBC development is released under GPL or LGPL.
The components of this project are the Driver Manager, DataManager, ODBCConfig, Odbcinst, drivers and other utilities.
This share library is the hub of most ODBC activity, but its function is simple. Ninety percent of the Driver Manager's function is to validate arguments, load and unload drivers and pass the call to the driver in a manner consistent with the ODBC specification. Normally, an application links only to this share to get the ODBC support it requires (see Figure 1). The Driver Manager loads/unloads the appropriate driver and passes calls to the driver.
Figure 2. DataManager TreeView
This is a GUI-client utility. The current version is based upon Troll Tech's Qt class library (http://www.troll.no/). The DataManager allows the user to browse and manage data sources (see Figure 2). The right side of the TreeView contains a sizable canvas which can be extended to include properties for any TreeView selections. An example of this has been implemented for the data source TreeViewItem. When a data source is selected, the canvas becomes a handy editor which can be used to submit SQL, review results and save/load either SQL or the results. Table designers and data editors could be easily added to the DataManager using the same techniques. The DataManager is an easy way to manage ODBC data-source resources.

Figure 3. ODBC Data Source Administrator
This is another GUI-client utility. It has been created to be user compatible with the Microsoft ODBC administration utility (see Figure 3). ODBCConfig makes it easy, even for non-techies, to configure their data sources. ODBCConfig uses the Odbcinst library to read/write ODBC system information. ODBCConfig will make use of any installed driver configuration libraries to present a list of driver-specific options to edit. ODBCConfig functionality is an excellent candidate for the KDE (http://www.kde.org/) Control Center. ODBCConfig makes it easy to configure ODBC data sources.
This is a share library which implements many useful Microsoft extensions and a number of unixODBC extensions. It provides an API for reading and writing ODBC system information (see Figure 4). This essentially means reading and writing the various INI files and environment variables. unixODBC also provides a command-line interface to this library. This command-line tool (of the same name) can be used by driver programmers when creating their install script/RPM. The Odbcinst library is used heavily by ODBCConfig, the Driver Manager and drivers but is seldom used by other applications. Odbcinst implements many Microsoft extensions.
The drivers, and their data source-specific client libraries, typically implement the vast majority of the ODBC functionality. As important as the Driver Manager is, it is the driver that carries out most of the work. The unixODBC Driver Manager has been designed to be binary compatible with any compliant drivers compiled on Linux. unixODBC includes several drivers (and their sources) as examples. unixODBC also includes a driver template for those wishing to write a new driver. MiniSQL, MySQL and PostgreSQL are examples of drivers included in unixODBC. unixODBC maintains a driver-certification process which can be found at its web site (see Resources).
unixODBC also includes a library for working with INI files, a LOG library and a command-line tool for executing SQL commands. The INI library is used by Odbcinst for reading/writing the ODBC system information. The LOG library is used by the Driver Manager and Odbcinst to log ODBC activity, such as errors, and implement ODBC tracing. The isql command-line tool allows the user to submit SQL commands in a terminal window. isql can also be used in batch mode, which can be quite useful because it can return results wrapped in an HTML table or delimited with a chosen character. It supports piping and redirection.
You can download the source distribution from the unixODBC website. Unpack the file using tar, then follow the instructions in the README file. You will want the Qt dev libraries to build the GUI components and you will need the database-specific client libraries for any drivers you decide to build. The README talks about this in more detail. You must have at least one driver section in /etc/odbcinst.ini. You can add this section using the Odbcinst command-line tool or your favourite editor. Normally, odbcinst.ini will get updated by driver install scripts using the Odbcinst command-line tool, but at this time, you may have to edit this file directly. A driver section in odbcinst.ini should look something like this:
[MiniSQL 2.x] Description = MiniSQL ODBC Driver Driver = /usr/lib/libodbcmini.so.1.0.0 Setup = /usr/lib/libodbcminiS.so.1.0.0 FileUsage = 2
Now run ODBCConfig to add, edit or remove data sources. You will need to be root to work with system data sources, but any user can add, edit and remove user data sources. Now run the DataManager, and you should see all ODBC data sources. When you try to expand the TreeView below a data source, you will be prompted for login information to connect to the data source. You can also try to connect to your data source using the isql command-line tool. Simply execute the command:
$isql DataSourceName MyID MyPWD
Most database access can be accomplished using a simple handful of ODBC function calls. In fact, it is good practice to keep it simple, because each driver implements its own level of compliance and completeness. An application can expect to be used with very modest drivers from time to time. The isql command-line tool is an example of an application that uses only a small, simple set of ODBC functions. I will not get too deep into ODBC APIs, since you can pick up excellent reference material elsewhere. The typical sequence of events goes something like this:
Connect to a data source.
Create and Execute an SQL Statement.
Process results.
Close connection.
Initialize ODBC by calling SQLAllocEnv and SQLAllocConnect, then call SQLConnect.
Initialize a statement by calling SQLAllocStmt. Call SQLPrepare to allow the Driver Manager a chance to preprocess the SQL, then call SQLExecute.
The simplest way to process results is to call SQLFetch in a loop and SQLGetData for each column in the result set. SQLNumResultCols can be used to find out how many columns are in the result set.
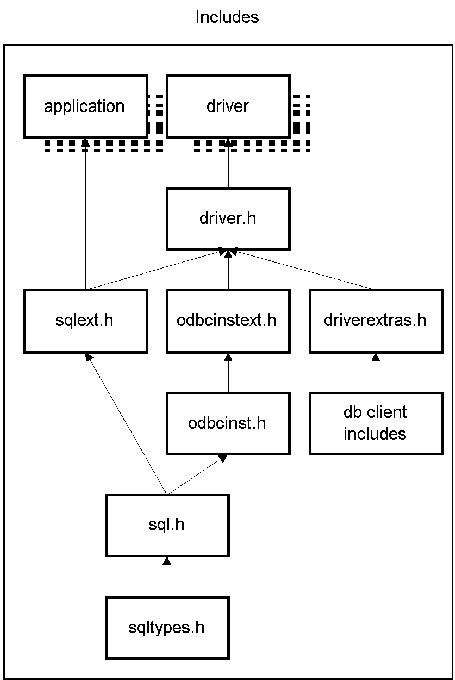
Figure 5. Include Files
Call SQLFreeStmt, SQLDisconnect, SQLFreeConnect and SQLFreeEnv to clean up. Your source should include sqlext.h (see Figure 5) and should link against libodbc.so (see Figure 1).
The driver and the Driver Manager share 98 percent of their function names. This is not surprising when you consider that the Driver Manager passes off most processing to the driver. An important difference, however, is that the Environment, Connection and Statement handles contain different information. For example, the driver's Connection handle will often contain some database-specific data such as a socket handle, while the Driver Manager's Connection handle will usually contain very little aside from a pointer to the driver's Connection handle. unixODBC contains a driver template which should act as a good starting point for anyone interested in creating a new driver. It should be very easy to port a driver to/from Linux using unixODBC, because unixODBC is designed to support driver code from other platforms. A useful driver will implement, at a minimum, the following functions: SQLAllocConnect, SQLFreeConnect, SQLAllocStmt, SQLFreeStmt, SQLConnect, SQLDisconnect, SQLPrepare, SQLExecute, SQLFetch, SQLGetData, SQLNumResultCols and SQLColAttribute.
Perhaps the best way to learn how a driver works is to look at some driver code. unixODBC contains a number of such examples. Your source will likely implement driver.h and driverextras.h, but at a minimum it should include sqlext.h and odbcinst.h (see Figure 5). Driver code from other platforms may have their own version of driver.h and driverextras.h or may not have them at all; this is okay, because these two includes are implemented in the local source directory and are not used by any other code. You should link against libodbcinst.so and any database-specific libraries (see Figure 1). unixODBC has something for just about every Linux user.
Application developers can now create portable data access code independent of the platform and the data source. Driver programmers can use the unixODBC driver template to get started on a new driver, then use Odbcinst when creating their install script/RPM. All Linux users can easily configure ODBC data sources for their applications with ODBCConfig, then take a look at what resources are available in a data source by browsing in the DataManager. Ease of use and functionality surpass other platforms which have had ODBC for a number of years. Most importantly, widespread adoption of unixODBC in popular Linux distributions will allow application developers to assume a desktop has these features and take advantage of them. Such features are of critical importance in having Linux fully accepted on an average user's desk.


{kind=link}
{kind=link}
{kind=link}