
IP Bandwidth Management
The success of the Internet is attributed mainly to the simplicity and robustness of the protocol that ties it together, IP (Internet Protocol). Lately, everyone wants to run on IP. Major drivers include telephone companies wishing to replace traditional circuit-switched voice networks by carrying voice on IP networks, and multi-site corporations wanting to replace their dedicated connections with virtual private networks (VPNs) over shared IP networks.
However, IP suffers a small handicap. Unlike protocols such as ATM, it treats everyone equally. All data that goes through IP networks is equally forwarded on a best-effort basis. What if I was willing to pay $2 more a month so customers could get my web pages loaded about half a second faster? What if I was willing to pay a little more so I could have a coherent audio conversation, across the Internet, with someone across the Atlantic? In both instances, those particular willing-to-pay-more packets will have to be treated more fairly for this to work, thus, IPs equality for all fails. Now, the new big buzzword is here: Quality of Service (QoS), that is, trying to streamline IP to meet these new requirements. Although not a new concept per se, QoS has gained more momentum lately due to the interest of large corporations in using IP.
QoS means different things to different people. An order of a burger and fries at McDonald's is cheaper than at a fancy restaurant, where you are served a glass of water and lots of courtesy before your order arrives. You pay more at the restaurant for the QoS. Someone might argue that the QoS is better at McDonald's because you get served faster. Another analogy is the airline model, where the same plane has economy and first-class customers. In simplistic terms, one can define QoS as paying more to get better service. As such, it is a good way for the Net to be self-sustaining.
An implication embedded in this is that the socialist days of the Internet are over. Socially, the advent of IP-QoS is already being blamed for introducing a caste system on the Internet: the “bit-haves” and “bit-have-nots” are becoming reality.
The ability to divvy up bandwidth owned by a service provider for QoS is referred to as “bandwidth management”. Several techniques have been proposed and implemented over the years. The Internet Engineering Task Force (IETF) has in the past proposed integrated services, via RSVP, which is host driven. RSVP has failed to take off as a widely deployed standard, mainly due to scalability issues. Currently, the IETF is pushing a new solution known as differentiated services (diffserv), which gives more control of bandwidth management to network owners. This article will not delve into the details of the two techniques. The good news is that both are currently supported in Linux.
The unsung hero of the new 2.1.x Linux traffic control (TC) code (and much more) is Alexey Kuznetsov (kuznet@ms2.inr.ac.ru). Alexey invested a great deal of thought in the design in order to make it extremely flexible and extensible.
What I describe is just the tip of the iceberg of the possibilities presented by Linux traffic control, without going deep into detail. The intended scope is to show via a simple example how one could unleash the power of Linux traffic control.
The TC features give ISPs the ability to manage (or carve) their bandwidth as they see fit. In the past, there have been other less-organized ways of doing this. The ISP could bandwidth-limit the customer's access rate by selling services based on interface capabilities, e.g., 28.8 vs. 56Kbps modems or 1 vs. 3Mbps xDSL modems.
Another more innovative but less ambitious (relative to TC) way of rate-limiting bandwidth is to use Alan Cox's shaper device. The shaper device is first attached to an already configured network device (e.g., Ethernet) using the shapecfg utility, which is also used to configure the shaper's speed. The next step is to use the ifconfig utility to configure the shaper to have the same IP address as the device to which it is attached. The final step is to map the packets to be treated by the shaper; this is known as classification. This is done using the common route command, pointing the route in which the packets are to be conditioned to the shaper. The advantage of the shaper is that it also runs on the 2.0.x kernels (included from 2.0.36 onwards and available as a patch for earlier kernels). The shaper's limited classification capabilities can be enhanced in the 2.0.x kernels by using Mike McLagan's (mmclagan@linux.org) patch to allow routes to be specified by source/destination pairs. The new TC capabilities encompass shaping as well as a great deal more.
Another technique to enable bandwidth management is to use the multi-routing table capabilities implemented by Alexey Kuznetsov. Linux 2.2 has a new feature that allows a single Linux box to have multiple routing tables. In essence, one could have a special routing table for a higher-paying customer and redirect their traffic through higher-bandwidth or less congested devices (e.g., to a T3 rather than an ISDN line, both of which are headed the same way). Perhaps the best-kept secret in Linux bandwidth management is that the Apache web server has a bandwidth limiting module, mod_throttle, to rate limit individual users as defined in a config file. For details, see http://www.bigrock.com/~mlovell/throttle/.
The Linux TC conditions packets after the next hop has been decided, i.e., after the forwarding code has decided which interface the packet will go out on. This means that only outgoing packets are subjected to the TC. The TC consists of three building blocks.
The queueing discipline can be thought of as the traffic/data-packet manager for a device. It encapsulates within it the two other major TC components and controls how data flows through them. Only one such managing component can be attached to a device. Currently, a few device queueing disciplines are available to manage devices, including class-based queueing (CBQ), Priority and CSZ (Clark-Shenker-Zhang). An example configuration with CBQ will be shown later.
The class(es) are managed by the device queueing discipline. A class consists of rules for messaging data owned by that class. For example, all data packets in a class could be subjected to a rate limit of 1Mbps and allowed to overshoot up to 3Mbps between the hours of midnight and 6AM. Several queueing disciplines can be attached to classes, including FIFO (First-In-First-Out), RED (Random Early Detection), SFQ (Stochastic Fair Queueing) and Token Bucket. If no queueing discipline is attached to a device, basic FIFO is used. In the example shown later, no specific class queueing disciplines are attached, thus defaulting to simple FIFO. CBQ, CSZ and Priority can also be used for classes and allow for subclassing within a class. This shows how easily very complex scenarios using TC can be built. The queueing disciplines managing classes are referred to as class queueing disciplines. Generally, the class queueing discipline manages the data and queues for that class and can decide to delay, drop or reclassify the packets it manages.
Classifiers or filters describe packets and map them into classes managed by the queueing disciplines. These normally provide simple description languages to specify how to select packets and map them to classes. Currently, several filters (depending on your needs) are available in conjunction with TC, including the route-based classifier, the RSVP classifier (one for IPV4 and another for IPV6) and the u32 classifier. All of the firewalling filters can be used subject to their internal filtering tags. For example, ipchains could be used to classify packets.
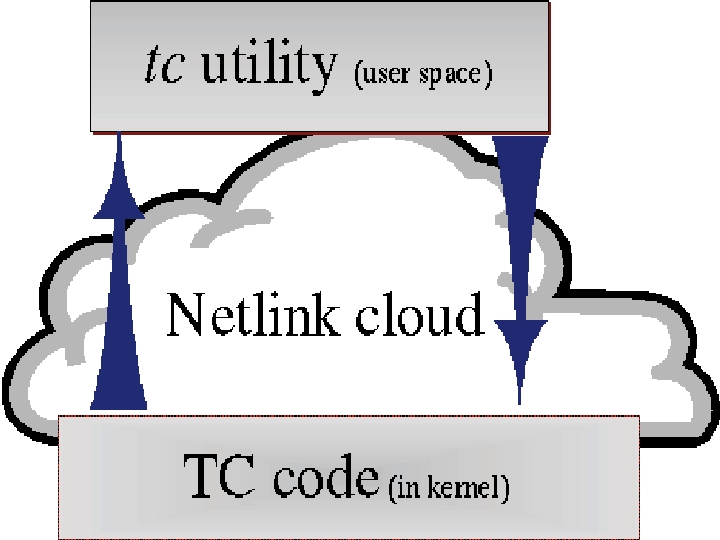
The TC code resides in the kernel and the different blocks can be compiled in as modules or straight into the kernel. Communication and configuration of the kernel code or modules is achieved by the user-level program tc written by Alexey. The interaction is shown in Figure 1. The tc program can be downloaded from ftp://linux.wauug.org/pub/net/ip-routing/iproute2-current.tar.gz. You will need to patch it for glibc, if you are using a glibc-only system. The patches are available in the same directory. Note that the package also includes the ip and rtmon tools.
TC is very flexible: you decide what you want to configure as a service. An ISP that offers virtual servers with different QoS levels is a good example of the power of Linux traffic control. Note that similar services can be applied within an intranet. The traditional offer differentiator when ISPs sell virtual, web-server, hosting services is disk space. For $5 more a month, you could get an additional 100 megabytes of disk space for your hosted web server. Other ISPs differentiate services based on access to other services, such as Realvideo and SSL, from your web pages. Still others base it on how many hits your web pages get and such things. With Linux traffic control in place, a new dimension is added to differentiating services. This presents many new opportunities for differentiating services offered to your customers. For example, if you offer virtual web hosting, you could offer four different packages:
Service Level Agreement (SLA) 1: cost $5/month—visitors to customers' virtual servers can get up to 250Kbps coming out of the server.
SLA2: cost $7/month—250Kbps, which can overshoot to 1Mbps between the hours of midnight and 6AM.
SLA3: cost $9/month—250Kbps, which can overshoot to 1Mbps when bandwidth is available at any time of the day.
SLA4: cost $50/month—up to 1Mbps of high-priority, low-latency bandwidth suitable for video and audio delivery (as well as IP telephony), with extra filters to give very low bandwidth to low priority visitors (e.g., those who get their services free).
A wide range of creative services could be offered. The time-of-day features could easily be added by using crontab-activated scripts to change configurations.
The following is an example of a Linux box with two virtual servers (web, FTP, etc.) and how an ISP can sell them as two separate packages based on the maximum bandwidth one gets when visiting those two virtual servers.
Kernel Compile
I'll assume you know how to compile the kernel and add network and aliasing support. I used kernel 2.1.129 and a few other patches at the time of this writing. Linux 2.2 pre1 had just come out, but the patches had not made it in yet. By the time you read this, 2.2 will be out and everything I used will be included.
The first challenge is the clock source. In order to accurately determine bandwidth measurements, you need a very fine-grained clock. In Linux, the clock runs at a frequency of HZ, defined to be 100 for the ix86, i.e., 100 clock ticks per second which translates to a granularity of 10ms for each clock tick. On Alphas, HZ is defined as 1000, giving a granularity of 1ms. I would not suggest changing the value of HZ in the code. The TC clock sources are adjusted by editing the file /include/net/pkt_sched.h under the kernel tree and modifying the line which defines PSCHED_CLOCK_SOURCE. To start, I suggest leaving the clock source alone until you get comfortable with running other things. The default clock source, PSCHED_JIFFIES, will work fine on all architectures. Use PSCHED_CPU on high-end Pentiums and Alphas. The most precise and expensive clock source is PSCHED_GETTIMEOFDAY. Use this if you have a truly high-end Pentium II or Alpha. Do not try to use it on a 486.
Next, compile the kernel. Select Kernel/User netlink socket and Netlink device emulation to allow use of netlink so that tc can talk to the kernel. The second option is a backward compatibility option and may be obsolete now that 2.2 is out, so don't worry if you don't see it. Next, compile in all the queueing disciplines and classifiers. Although each can be selected as a module, I compiled them straight in. The selections are QoS or fair queueing, CBQ packet scheduler, CSZ packet scheduler, the simplest PRIO pseudoscheduler, RED queue, SFQ queue, TBF queue, QoS support, rate estimator, packet classifier API, routing-tables-based classifier, U32 classifier, special RSVP classifier and special RSVP classifier for IPv6.
Go through the normal procedure of compiling and installing the kernel.
Compiling and Setting Up TC
If you use glibc as I do (Red Hat 5.2), you will need to apply the glibc patch. A glibc patched source for tc is included (tc-glibc-patched.tgz). The major catch is to change the Makefile to point to where the kernel include file is. Typing make should then cleanly compile tc and ip for you. The ip-routing directory contains patches with names iproute2-*.glibc2.patch.gz. Get the latest one to match with the current tc. I downloaded iproute2-2.1.99-now-ss981101.glibc.patch.gz at the time of this writing.

Figure 2. CBQ Tree Diagram
Figure 2 shows the simple scenario we are going to set up. Two leaf nodes are emanating from the root. IP address 10.0.0.10 (classid 1:1) and 10.0.0.11 (classid 1:2) are aliases on device eth0. They all share the same parent—classid 1:0 (the root node). Again, the intent is to show what one can do without going into fine details or building a complex TC setup. With some modifications, one can build more interesting setups with multiple devices.
The general recipe for setting up the QoS features is to first attach a qdisc to a device. In the sample script, this is achieved by the line
qdisc add dev eth0 root handle 1: ...
Next, define your classes. This allows you to discriminate between the different traffic types going out. In the sample script, this is achieved by the lines which start with
tc class add dev eth0 parent 1:0 classid X:Y ...In the sample script, a one-level tree is shown. However, one can build a multiple depth tree. Basically, a child node (as shown in Figure 2) inherits from a parent and is then further resource-restricted by the class definition. For example, the root class 1:0 owns the device's bandwidth. The child node 1:1 cannot have more than 10Mbits allocated to it, but is restricted to 1Mbps. Eventually, the leaf nodes get packets sent to them based on the classifier mapping packets to them. This is quite similar to the UNIX directory and file tree structures. You can think of non-leaf nodes as directories and leaf nodes as files.
Finally, define your packet-to-class mappings to tell your classifier which packets to send to which class. You must define the classes for this to make sense. First, attach a classifier to the proper class. In the sample script, this is achieved by the construct which starts with the line
filter add dev eth0 parent 1:0 protocol ip ...
Next, define the packet-to-class mappings that will be used. In the sample script, this is defined in the constructs that define the matching criteria (such as match ip src ...). Always map packets to leaf classes.
If you follow this recipe and substitute the right syntax for the different queueing disciplines and filters, you will get it right. The appropriate details are in the options.
In our setup, we have two virtual web servers on a single Linux machine. The setup script (Listing 1) includes some commented sample IP-aliasing examples using the supplied ip utility. The ip utility is feature-loaded and not in the scope of this article. IP addresses 10.0.0.10 and 10.0.0.11 are attached (aliased on) to device eth0 in the example.
To test, use ftp to get to another machine on the network. First, use ftp to get to IP address 10.0.0.10, where you should observe a rate of approximately 1Mbps. Quit that ftp session and start another one to 10.0.0.11, where you should observe a throughput of approximately 3Mbps.
These are very exciting times for Linux. As far as I know, Linux is the most sophisticated QoS-enabled OS available today. The closest second is probably BSD's ALTQ, which lags quite a bit behind the sophistication, flexibility and extensibility found in Linux TC. I am not aware of any such functionality in Microsoft products (perhaps someone could provide pointers if they exist). Sun Solaris does have a CBQ and RSVP combo they sell as a separate product. I predict a huge increase in the use of Linux servers as a result of the many features available with TC. Alexey has taken Linux to a new level.
Support for the IETF diffserv features is also in Linux. The work extends the TC to add the most flexible diffserv support known today. Diffserv support was made possible through efforts by Werner Almesberger (who also wrote LILO, Linux-ATM and more) and myself. For more details, see http://lrcwww.epfl.ch/linux-diffserv/.
All listings referred to in this article are available by anonymous download in the file ftp.linuxjournal.com/pub/lj/listings/issue62/3369.tgz.
Jamal Hadi Salim (hadi@cyberus.ca) is a hacker wannabe. He spends a fair amount of his spare time staring at Linux networking code. Jamal was the original author of the Sendmail-UUCP HOWTO and is the CASIO digital diary serial driver/application author, which he still maintains. He also has sent the occasional patches to many things, including the kernel, biased towards networking issues. Currently, his efforts are focused mainly in the network scheduling code where he co-authored the Linux diffserv code with Werner Almesberger.


{kind=link}