
A High-Availability Cluster for Linux
Although Linux is known to be an extremely stable operating system, the fact that the standard PC hardware is not quite so reliable must not be overlooked. I have been maintaining Linux servers for a long time, and in most cases when a system has failed, it has been due to server hardware failure. UNIX in the commercial world is known for having good clustering and high-availability (HA) technologies.
In my present company, Electec, we rely heavily upon e-mail (Sendmail and IMAP4), Windows file sharing (Samba), FTP and dial-up authentication (radius) services on a 24-hour basis for communication with our suppliers, staff and customers who are located in different time zones. Until recently, all of these services were consolidated on one Linux server. This system had served us very well. However, it was just a matter of time before a hardware failure occurred, which would cause us loss of productivity and revenue.
High availability is becoming increasingly important as we depend more and more on computers in business. I decided to design and implement an inexpensive high-availability solution for our business-critical needs without requiring the use of expensive additional hardware or software. This article covers the design aspects, pitfalls and implementation experiences of the solution.
Quite a few different approaches and combinations of approaches exist for high availability on servers. One way is to use a single, fault-tolerant server with redundant power supplies, RAID, environmental monitoring, fans, network interface cards and so on. The other way involves the use of several units of non-redundant hardware arranged in a cluster, so that each node (or server) in the cluster is able to take over from any failures of partner nodes. The fault-tolerant server approach has the advantage that operating system, application configurations and operations are the same as if you were using a simple, inexpensive server. With a cluster, the application and OS configurations can become very complex and much advanced planning is needed.
With a fault-tolerant server, failures are taken care of in such a way that clients do not notice any downtime—recovery is seamless. Ideally, this should also be the case with node failures in a cluster. In many cases, the hardware cost of a cluster is far less than that of a single fault-tolerant server, especially when you do not have to spend a great deal of money for one of the commercial cluster software offerings.
A trade-off is present between cost and client disruption/downtime. You must ask yourself how much downtime you and your users can tolerate. Shorter downtimes usually require a much more complex or costly solution. In our case, I decided we could live with approximately five minutes downtime in the event of a failure; therefore, I chose to use a cluster as opposed to a single fault-tolerant server.
Many clustering solutions are available to the UNIX market, which can provide almost zero downtime in the event of a node takeover by means of session and network connection takeover. These solutions are mostly expensive and normally require the use of external shared storage hardware. In our case, we can allow for sessions and connections to be lost. This simplifies the task of implementing a high-availability cluster.
When implementing HA clustering, some recommend that a shared storage device, such as a dual-port RAID box, be used. However, it is possible to approach the problem by using a separate storage device for each node in the cluster and mirroring the storage devices when necessary. Each avenue has its own merits. The shared storage approach has the benefit of never requiring any software mirroring of data between cluster nodes, thus saving precious CPU, I/O and network resources. Sharing is also beneficial because data accessible from another cluster node is always up to date. The mirroring approach, which uses separate storage devices, has the advantage that the cluster nodes do not have to be in the same geographical location and are therefore more useful in a disaster recovery scenario. In fact, if the mirror data was compressed, it could be sent over a WAN connection to a remote node.
RAID systems are available, which allow the disks to be geographically distributed and which require interconnectivity by optical fiber; however, these are rather expensive. Two sets of simple storage devices are less expensive than a dual-port RAID box of similar capacity. The dual-port RAID box can, in some cases, introduce a single point of failure in the cluster. If the RAID file system is somehow corrupted beyond recovery, it would cause serious cluster downtime. Most RAID systems mirror the data at the device level and have no regard for which file system is in use. A software-based system can mirror files in user space, so if a file becomes unreadable on one node it will not necessarily copy the same file system corruption to the other node. Due to this advantage and the cost factor, I decided to use separate storage devices on each node in the cluster. It should be noted that even if a dual-ported storage device is used, both nodes in the cluster should never mount the same partition read/write simultaneously.
Spreading the workload evenly across the nodes in a cluster is preferable to having one node do all the work until it fails, then having another node take over. The term for this is a hot standby system.
Load balancing can take many forms, depending on the service in question. For web servers, which provide simple static pages and are often read-only, a round-robin DNS solution can be quite effective. Unfortunately, with the read/write or transactional type of services such as e-mail or database access, unless the connection and session information from the service on one node can be shared and used by other nodes, it would be very difficult to provide seamless load balancing over the cluster. It would also require the disk mirroring to be near-instantaneous and use lots of distributed locking techniques, which most daemons will not support without complex modifications. To avoid these drawbacks, I decided to use a simpler approach which stands between the hot standby and the network-level load balancing.
In my two-node cluster, I put half of the required services on node “A” (serv1) and the other half on node “B” (serv2). A mutual failover configuration was employed so that if node A failed, node B would take over all of its services and vice versa.
We had to decide which services needed to be running on the overall cluster. This involved comparatively rating how much computing resource each service would consume. For our previous Linux server, it was found that Samba and Cyrus IMAP4 were the most resource-intensive services with FTP, httpd and Sendmail following close behind. Careful consideration had to be given to which services were suited to running on two or more nodes concurrently. Examples of such services included Sendmail (for sending mail only or as a relay), bind, httpd, ftpd (downloading only) and radius. Examples of services which cannot be run in such a way are Cyrus IMAP4, ftpd (uploading) and Samba. Samba cannot be run on two servers at once, as that would result in two servers broadcasting the same netbios name on the same LAN. It is not yet possible to have PDC/BDC (primary and backup domain controller) arrangements with the current stable versions of Samba. The pages on a simple web site, on the other hand, do not change often. Therefore, mirroring is quite effective and parallel web servers can run quite happily without major problems. The servers were configured so that each one took primary care of a specific group of services. I put Samba on serv1 and Cyrus IMAP4 on serv2. The other services are shared in a similar way; httpd, bind and radius run on both nodes concurrently.
In the event of a node failure, the other node takes over all the services of the failed one in such a way as to minimize disruption to the network users. This was best achieved by using IP (Internet protocol) and MAC (mandatory access control) address takeover from the failed node onto an unused Ethernet card on the takeover node. In effect, the node would appear to be both serv1 and serv2 to the network users.
The use of MAC address takeover was preferred in order to avoid potential problems with the clients' ARP (address resolution protocol) cache still associating the old MAC address with the IP address. MAC address takeover, in my opinion, is neater and more seamless than IP takeover alone, but unfortunately has some scalability limitations.
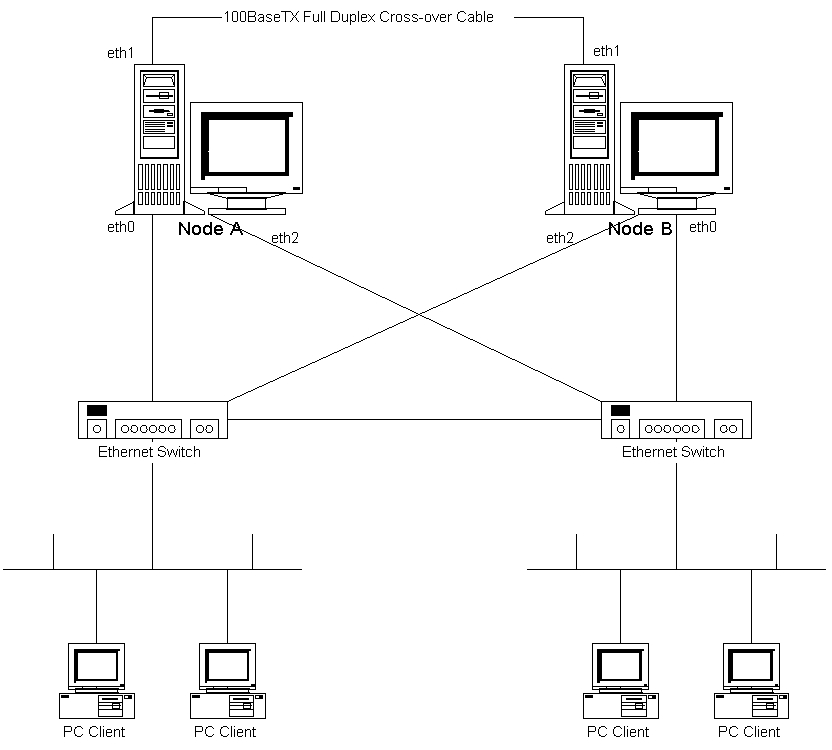
While considering the HA network setup, it was very important to eliminate all possible single points of failure. Our previous server had many single points of failure; the machine itself, the network cable, the Ethernet hub, the UPS, etc. The list was endless. The network has been designed to be inexpensive and reliable as shown in Figure 1.
Figure 1. Network Diagram for Our Two Nodes
The network diagram shows the three network interface cards (NICs) in each server. The first NIC in each server is used for the main LAN access to clients. Each node is plugged in to a separate Ethernet switch or hub to give redundancy in case of a switch lockup or failure. (This actually happened to us not so long ago.) The second NIC is used for creating a private inter-node network using a simple cross-over 100BaseTX full-duplex Ethernet cable. A cross-over cable is far less likely to fail than two cables plugged into an Ethernet hub or switch. This link is primarily used for disk mirroring traffic and the cluster heartbeat. It also helps take the network traffic load off the main interface and provides a redundant network path between the nodes. The third NIC is the redundant LAN access card used for MAC and IP address takeover in the event of a remote node failure in the cluster. Again, they are plugged in to different Ethernet switches or hubs for greater network availability.
If a node fails in some way, it is vital that only one of the nodes performs the IP and MAC address takeover. Determining which node has failed in a cluster is easier said than done. If the heartbeat network failed while using a simplistic takeover algorithm, both of the nodes would wrongly perform MAC, IP and application takeover and the cluster would become partitioned. This would cause major problems on any LAN and would probably result in some kind of network and server deadlock. One way to prevent this scenario from taking place is to make the node which first detects a remote node failure, remote login to each of that remote node's interfaces and put it into a standby run level (e.g., single-user mode). This run level would prevent the failed node from attempting to restart itself and thus stop an endless failure-recovery loop. There are problems with this method. What if node A (which has a failed NIC) thinks node B is not responding, then remotely puts node B into single-user mode? You would end up with no servers available to the LAN. There must be a mechanism to decide which node has actually failed. One of the few ways to do this on a two-node cluster is to rely on a third party. My method of implementing this is to use a list of locally accessible devices which can be pinged on the LAN. By a process of arbitration, the node which detects the highest number of unreachable devices will gracefully surrender and go into the standby runlevel. This is shown in Figure 2.
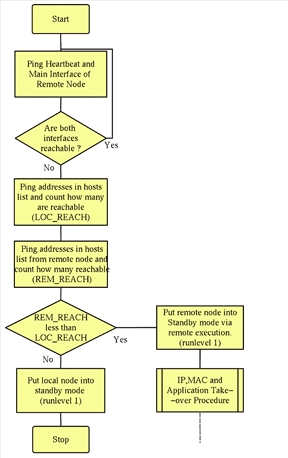
Figure 2. Flow Chart Showing Overview of Cluster Daemon Algorithm
To implement this solution with minimal risk of data loss, the data on the two servers must be constantly mirrored. It would be ideal if the data written to serv1 was simultaneously written to serv2 and vice versa. In practice, a near-perfect mirror would require a substantial kernel implementation with many hurdles along the way, such as file system performance and distributed lock management. One method would be to implement a RAID mirror which used disks from different nodes: a cluster file system. This is supposed to be possible in later incarnations of the 2.1 and probably the 2.2 kernel by using md, NFS and network block devices. Another solution, which also remains to be evaluated, is the use of the CODA distributed file system.
A practical way to have a mirror of data on each node is to allow the frequency of the file mirroring to be predefined by the administrator, not only for nodes but rather on a per file or directory basis. With this fine-grained level of control, the data volatility characteristics of a particular file, directory or application can be reflected in frequency of mirroring to the other node in the cluster. For example, fast-changing data such as an IMAP4 e-mail spool, where users are constantly moving, reading and deleting e-mail, could be mirrored every minute, whereas slow-changing data such as the company's mostly static web pages could be mirrored hourly.
Trade-offs must be considered when mirroring data in this way. One major trade-off is mirror integrity with CPU and I/O resource consumption. It would be nice if I could have my IMAP4 mail spools mirrored each second. In practice, this would not work because the server takes 15 seconds to synchronize this spool each time. The CPU and disk I/O usage could be so high that the services would be noticeably slowed down. This would seem to defeat the objective of high availability. Even if the CPU had the resources to read the disks in less than one second, there might still be problems transferring the data changes between the nodes due to a network throughput bottleneck.
This mirroring approach does have flaws. If a file is saved to a Samba file share on serv1, and serv1 fails before they are mirrored, the file will remain unavailable until serv1 fully recovers. In a worst-case scenario, the serv1 file system will have been corrupted and the file lost forever. However, compared to a single server with a backup tape, this scenario is less risky because traditional backups are made far less frequently than the mirroring in the cluster. Of course, a cluster is no replacement for traditional backups which are still vital for many other reasons.
A major design factor is resynchronization (mirroring back) of the files once a failed node has recovered. A reliable procedure must be employed so that data which has changed on the failover node during the failure period is mirrored back to the original node and not lost, because the original node overwrites or deletes it in the restoration procedure. The resynchronization procedure should be implemented so that a node cannot perform any mirroring while another node has taken over its services. Also, before the services can be restarted on the original node, all files associated with it must be completely mirrored back to this original node. This must be done while the services are off-line on both nodes to prevent the services from writing to the files being restored. Failure to prevent this could result in data corruption and loss.
The main problem when using this solution was with IMAP4 and pop3 mail spools. If an e-mail message is received and delivered on serv2, and serv2 fails before mirroring can take place, serv1 will take over the mail services. Subsequent mail messages would arrive in serv1's mail spool. When serv2 recovers, any e-mail received just before failure will be overwritten by the new mail received on serv1. The best way to solve this is to configure Sendmail to queue a copy of its mail for delivery to the takeover node. In the event that the takeover node is off-line, mail would remain in the Sendmail queue. Once the failed node recovered, e-mail messages would be successfully delivered. This method requires no mirroring of the mail spools and queues. However, it would be necessary to have two Sendmail configurations available on both nodes: one configuration for normal operation and the other for node takeover operation. This will prevent mail from bouncing between the two servers.
I am not a Sendmail expert. If you know how to configure dual-queuing Sendmail delivery, please let me know. This part is still a work in progress. As a temporary measure, I create backup files on resynchronization of the mail spool with manual checking on node recovery, which is quite time consuming. I also prevent such difficulties by mirroring the mail spool as frequently as possible. This has an unfortunate temporary side effect of making my hard disks work overtime. Similar problems would be encountered when clustering a database service. However, a few large UNIX database vendors are now providing parallel versions of their products, which enable concurrent operation across several nodes in a cluster.
A node could fail for various reasons ranging from an operating system crash, which would result in a hang or reboot, to a hardware failure, which could result in the node going into standby mode. If the system is in standby mode, it will not automatically recover. The administrator must manually remove a standby lock file and start run-level 5 on the failed node to confirm to the rest of the cluster that the problem has been resolved. If the OS hangs, this would have the same effect as a standby run level; however, if the reset button is pressed or the system reboots, the node will try to rejoin the cluster, as no standby lock file will exist. When a node attempts to rejoin the cluster, the other node will detect the recovery and stop all cluster services while the resynchronization of the disks takes place. Once this has completed, the cluster services will be restarted and the cluster will once again be in full operation.
My choice of Linux distribution is Red Hat 5.1 on the Intel platform. There are, however, no reasons why this could not be adapted for another Linux distribution. The implementation is purely in user space. No special drivers are required. Some basic prerequisites are necessary in order to effectively deploy this system:
Two similarly equipped servers, especially in terms of data storage space, are needed.
Three network interface cards per server are recommended, although two might work at the expense of some modifications and extra LAN traffic.
Sufficient network bandwidth is needed between the cluster nodes.
My system consists of two Dell PowerEdge 2300 Servers, each complete with:
three 3C905B 100BaseTX Ethernet cards
two 9GB Ultra SCSI 2 hard disks
one Pentium II 350 MHz CPU
The administrator can configure groups of files which are mirrored together by creating small mirror description files in the configuration directory. Note directory entries must end with a forward slash (/). Below is the description file for my lpd mirroring, /etc/cluster.d/serv1/Flpd:
/var/spool/lpd/ /etc/printcap
The frequency of the mirroring is then controlled by an entry in the /etc/crontab file. Each entry executes the sync-app program, which examines the specified service mirror description file and mirrors the contents to the specified server IP address. In this example, the specified server address is the cross-over cable IP address on serv2. Mirroring of the lpd system is done every hour. These crontab entries are from serv1:
0,5,10,15,20,25,30,35,40,45,50,55 * * * * root \ /usr/local/bin/sync-app /etc/cluster.d/serv1/Fsmbd \ serv2-hb 0 * * * * root /usr/local/bin/sync-app \ /etc/cluster.d/serv1/Flpd serv2-hb
The brains of the system lie in the cluster daemon, clusterd. This was written in the Bourne shell and will soon be rewritten in C. The algorithm outline is shown as a flow chart in Figure 2.
clusterd continuously monitors the ICMP (Internet control message protocol) reachability of the other node in the cluster, as well as a list of hosts which are normally reachable from each node. It does this using a simple ping mechanism with a timeout. If the other node becomes even partially unreachable, clusterd will decide which node actually has the failure by counting the number of hosts in the list which each node can reach. The node which can reach the fewest hosts is the one which gets put into standby mode. clusterd will then start the failover and takeover procedures on the working node. This node then continues to monitor whether the failed node recovers. When it does recover, clusterd controls the resynchronization procedure. clusterd is invoked on each node as:
clusterd <local-nodename> <remote-nodename>
It has to know which applications and services are running on each node so that it knows which ones to start and stop at failover and takeover time. This is defined in the same configuration directories as the service mirror description files discussed earlier. The configuration directories in each node are identical and mirrored across the whole cluster. This makes life easier for the cluster administrator as he can configure the cluster from a single designated node. Within the /etc/cluster.d/ directory, a nodename.conf file and a nodename directory exist for each node in the cluster. The reachlist file contains a list of reachable external hosts on the LAN. The contents of my /etc/cluster.d directory are shown here:
[root@serv1 /root]# ls -al /etc/cluster.d/ total 8 drwxr-xr-x 4 root root 1024 Nov 15 22:39 . drwxr-xr-x 23 root root 3072 Nov 22 14:27 .. drwxr-xr-x 2 root root 1024 Nov 4 20:30 serv1 -rw-r--r-- 1 root root 213 Nov 5 18:49 serv1.conf drwxr-xr-x 2 root root 1024 Nov 8 20:29 serv2 -rw-r--r-- 1 root root 222 Nov 22 22:39 serv2.conf -rw-r--r-- 1 root root 40 Nov 12 22:19 reachlistAs you can see, the two nodes are called serv1 and serv2. The configuration directory for serv1 has the following files: Fauth, Fclusterd, Fdhcpd, Flpd, Fnamed, Fradiusd, Fsmbd, K10radiusd, K30httpd, K40smb, K60lpd, K70dhcpd, K80named, S20named, S30dhcpd, S40lpd, S50smb, S60httpd and S90radiusd.
Files beginning with the letter F are service mirror description files. Those starting with S and K are linked to the SysVinit start/stop scripts and behave in a similar way to the files in the SysVinit run levels. The S services are started when node serv1 is in normal operation. The K services are killed when node serv1 goes out of service. The number following the S and K determine the order of starting and stopping the services. clusterd, running on node serv2, uses this same /etc/cluster.d/serv1/ directory to decide which services to start on serv2 when node serv1 has failed. It also uses the serv1 service mirror description files (those files starting with F) to determine which files and directories need to be mirrored back (resynchronized) to serv1 after it has recovered.
The configuration directory for node serv2 contains Fftpd, Fhttpd, Fimapd, Fsendmail, K60sendmail, K80httpd, K85named, K90inetd, S10inetd, S15named, S20httpd and S40sendmail. As you can see, the serv2 node normally runs Sendmail, named, httpd, IMAP4 and ftpd.
Whenever the network interfaces need to be brought up or down I have used Red Hat's supplied ifup and ifdown scripts. This makes the network interface configuration more tightly integrated with the GUI network configuration tools. The node configuration files, /etc/cluster.d/nodename.conf, allow you to specify the Ethernet NIC and its purpose on each node in the cluster. My two node configuration files are shown in Listings 1 and 2.
Listing 1. serv1 Configuration File
Listing 2. serv2 Configuration File
To implement the MAC address take over, one important addition must be made to the Red Hat Ethernet configuration files. You must add a line to the /etc/sysconfig/network-scripts/ifcfg-eth2 file to set the MAC address. eth2 is the redundant interface in my case, so I need it to take over the MAC address of the main service interface on the other node in the cluster. In other words, the MAC address of eth2 on serv2 must be the same as the MAC address of eth0 on serv1. The line 'MACADDR=00:10:4B:63:1C:08' was appended to this file on node serv2. The Red Hat ifup command will use this variable when bringing up an interface. A similar modification must be made to each node.
If you use an Ethernet switch (instead of a hub), it will be necessary to set the MAC address cache timeout to a suitable period to avoid the cluster losing communication with the LAN clients after a MAC address takeover. I set ours to 20 seconds for the ports which are connected directly to the nodes. Consult your switch manual or vendor if you need information on how to do this. It can usually be done via the console cable.
I have created service mirror description files and crontab entries for /etc/hosts, passwd/group files and the entire /etc/clusterd/ directory so that I can administer the cluster from a single node. This greatly simplifies cluster configuration. To avoid confusion, I found it helpful to create a DNS alias for each service used on the cluster which points to the primary node for that service. Thus, when I need to configure Samba, all I need to do is remotely log in to samba.yourdomainname.com. If the secondary node for a service is configured by mistake, any changes will be ignored until the primary node fails.
Currently for my system, only two nodes may be in a cluster. Scaling this up to clusters of more than two nodes should not be difficult, although instead of MAC address takeover, a different approach will probably have to be used because of the large number of NICs required for larger clusters.
Several useful utilities enabled me to do efficient mirroring. rsync is an invaluable utility which uses the rsync algorithm. This program will look for changes in files and mirror only the parts which have changed rather than the whole file. It also checks if the file has been updated by examining the modification date and file size before doing any further comparisons. ssh (secure shell) can also be used between the nodes in conjunction with rsync so that the mirrored data is sent via an encrypted and authenticated connection. Alternatively, you can use rsh if you prefer.
When rsync is doing file comparisons, it uses the file's date and time; therefore, it is vital that the nodes all agree on the same time. I chose to run the netdate utility every hour from cron. The nodes used a list of remote trusted time sources. To make sure a failed node boots with the correct time, the CMOS PC clock is updated after running netdate.
rsync was configured so that files in the source directory which do not exist on the target directory are deleted. This behaviour is necessary to avoid accumulative and excessive disk usage on the target node. If this setting is not used, a user connected to a Samba file share would effectively not be able to delete any file on the mirrored node. The same goes for almost all applications. clusterd is configured to create backups of deleted or changed files when the resynchronization procedure is in progress. This can help minimize the risk of data loss in the event of mirroring failure prior to a node takeover. Subsequent removal of backup files would necessitate some human intervention, after it has been confirmed that files or data were not lost after the node recovery. This is done using the --backup option of rsync version 2.2.1. You may find it more CPU efficient to turn off the rsync algorithm and fully mirror files which have changed instead of mirroring the changes; however, this will utilize more network bandwidth.
The resynchronization (mirroring back) procedure was implemented using rsync, which uses a lock file to disallow any mirroring to another node when a node failure is sensed. The lock file is checked for existence by sync-app before any files are mirrored. This prevents node A mirroring to node B, while node B is mirroring the same files to node A.
If preferred, clusterd could be used with a shared and/or distributed storage device by removing the resynchronization function and by not using sync-app, although I have not tried this.
To test server failure, I had to simulate the failure of every interface on the cluster. In each case, the cluster took the expected action and shut down the correct server. In the case of the inter-node/heartbeat network failing, the nodes simply carried on normal operation and notified the administrator of the failure. On a point-to-point network of this nature, it is almost impossible to determine which NIC is at fault. I simulated various network switch failures and power supply failures. The results were all as expected. After a node was put into standby (single-user) mode, I had to manually remove a standby lock file in order to fully bring up the node again. If a node recovered and entered a network runlevel while the standby lock file still existed, the remote node immediately put the node back into standby mode to prevent an IP and MAC address clash on the LAN.
Mirroring was tested over a period of several months, and I found that the nodes could typically compare 6GB of unchanged data in approximately 50,000 files in under 45 seconds.
After catastrophic node failure (I pulled the power plug from the UPS), recovery time for the node was around 10 to 15 minutes for fsck disk checking, and a disk resynchronization time of around three minutes (9GB of data). This represented a cluster services downtime of around three minutes to the LAN clients.
Failover delay from when a node failed until the remote node fully took over was typically 60 to 80 seconds. The effect on users depended on the service: Sendmail, IMAP4, http and FTP simply refused connection for users for the duration, whereas Samba sometimes momentarily locked up a Windows PC application when files were open at the point of failure. radius and dhcpd caused no client lock-outs, probably because of their UDP implementation.
On the whole, the cluster provides us with much better system availability. It is a vast improvement over the single server, as we can now afford to do server maintenance and upgrades during working hours. We have not yet had any catastrophic failures with the new Dell servers, but the test results show a minimal downtime of less than two minutes while a node takes over. We have saved large amounts of capital by implementing a simple high-availability cluster without the need for expensive specialist hardware such as dual ported RAID.
This clustering solution is certainly not as advanced as some of the commercial clusters or as thorough as some of the upcoming open source Linux-HA project proposals; however, it does sufficiently meet our needs.
The system has been in full-time production operation since September 1998. We have over 30 LAN clients using the cluster as their primary “server”. The system has proven to be reliable. The company sees the server as a business-critical system, and we have achieved the objectives of high availability.



{kind=link}
{kind=link}