
Linux and the Euro Currency: Toward a Global Solution
Starting in 1999, each European be using this new currency in his everyday life. Even if cash is not yet available, most prices, wages, invoices, etc. will be labelled in euro as well as in national currencies.
In 2002, each local currency except for the British pound (£), Danish krøner (kr), Swedish Kroner and Greek drachma will be replaced by the Euro. This is a major move for a real European union, which will create a market of 300 million people, from Finland to Portugal and Ireland to Greece.
Figure 2. Various currency symbols
Euro and year 2000 support are currently the biggest problems for computer scientists. On UNIX systems where a kind of Y2K bug will not occur until 2038, the euro is the major problem. On Windows machines, Y2K is the major problem since Microsoft has already integrated support for the Euro in Windows 98 and NT. A new proprietary norm was created, called cp1252, which makes these systems the first to properly support the Euro.
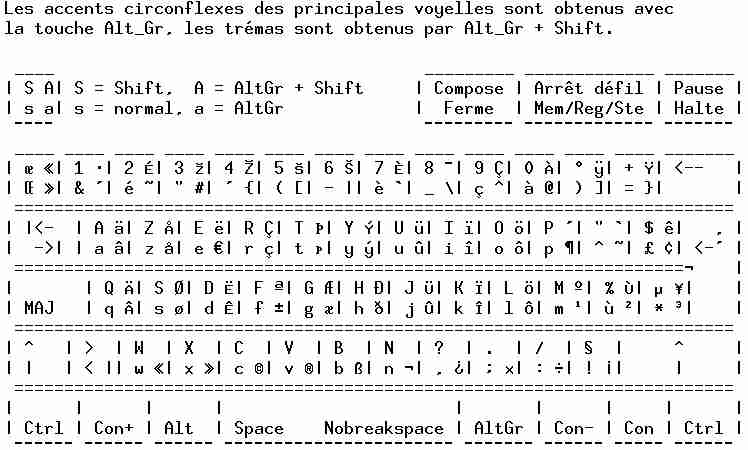
Figure 3. Key table with the Euro symbol
The transition from local currencies to the euro also implies mathematical conversions in financial programs: one euro equals 6.55957 French francs, for example. One euro is approximately one dollar U.S. The European Community created a “Euro Workshop” and “Euro Project Team” to find any possible solution for all types of platforms, even cellular phones. Most of the documents can be found at http://www.stri.is/TC304/Euro/. I used some of their euro symbol pictures to illustrate this article.
UNICODE was a good candidate for supporting national characters, but X Window System font management would have made it a pain to implement. For example, see plan9 difficulties at http://www.gh.cs.usyd.edu.au/~matty/9term/. Moreover, the numeral console-mode applications could not take advantage of UNICODE: even today, video-card memory is too tight to hold this wide range of characters. Clearly, a solution was needed for UNIX and other 8-bit systems.
A possible solution was creating yet another encoding format for 8-bit systems, which even today do not support the whole range of national characters. For example, it is impossible to create an “oe ligature” or an “s caron” in iso-8859-1, even though they are widely used in several European languages:
“oe ligature”: the French words boeuf, coeur, oeil, the German poet Goethe
“s caron”:
koda cars
I can hardly imagine a computer where not all 26 alphabetic letters were available, or where u had to be used in place of v because it had not been implemented in its character set. Yet many non-English speaking people face this problem each day when using keyboards without characters such as the “oe ligature” (

Taking advantage of this situation and lack of the euro symbol in iso-8859-1 latin1 (ISO 8859-1 latin1 is the UNIX encoding format, i.e., a correspondence between letters and codes, also used for email encoding), a new encoding format project was started, which would support:
the euro
“oe ligature” in both upper case and lower case
“s and z caron” in both upper case and lower case
“y diaeresis” in upper case only since (ÿ) already exists in latin1
To avoid breaking compatibility with the widely used iso-8859-1 latin1, it was decided that this new encoding would be based on it. However, there was still a big problem—each of the 255 possible characters existing in an 8-bit encoding had already been assigned in iso-8859-1. Therefore, it was decided that less frequently used characters should be removed to allow integration of the missing ones. In addition, the following changes were made:
The euro replaced the “international currency sign” (¤): the symbol the former Soviet Union had wanted to replace the dollar sign in 7-bit ASCII encoding format.
“oe” and “oe ligature” replaced the one-half fraction mark (½) and one-quarter fraction mark (¼), respectively.
“s caron” and “S caron” replaced “broken bar” (¦) and “floating diaeresis” (¨), respectively.
“z caron” and “Z caron” replaced “floating acute” (') and “floating cedilla” (¸), respectively.
“Y diaeresis” replaced “three quarter” (¾).
Since the cedilla (¸) looks like a comma (,), the diaeresis looks like a double quote (“) and the acute looks like a single quote ('), they could easily be replaced; compose tables would need a minor update. For example, on French and Dutch keyboards, the (”) key is used to get äëïöüÄËÏÖÜ but not “Y diaeresis”, which is missing. One must simply press it, release it (nothing happens) then press a vowel key to get a “vowel diaeresis”.
If there is any other character but a vowel, (“) shows up. Here, adapting to the new encoding would simply mean replacing the latter case by a (”) and adding composing possibilities for (sSzZ). This new encoding is called iso-8859-15 latin9 (nicknamed latin9) to show it is 97% compatible with iso-8859-1 latin1. By the time this article is published, it should already have been approved by ISO.
Implementation for the Linux console was quite simple. I asked Ricardas Cepas (rch@pub.osf.lt) which tool he implemented his fonts with. He provided me with a custom version of the chedit font editor for linux-console. I simply took latin1 fonts and replaced the old unused characters by latin9 new characters, for each latin1 font size (from 16x16 to 08x08), but then I was able to display only iso-8859-15 latin9 characters.
Among the recommendations of the European Commission is “AltGr-e should be used to get the euro symbol”. (The Alt key to the right of the keyboard must be remapped to AltGr.) AltGr is used as a modifier like Shift on German keyboards, @ can be obtained with AltGr-q, on French keyboards # is AltGr-3, etc. AltGr is used in the Linux version of many European keyboards to output 8-bit characters, as a remembrance of things past: there was a time when making dead keys work was impossible. On French and Dutch keyboards, (“) and (^) are such dead keys: they act like compose plus this key on the following character. Since many words use (^) or (”) (ètre, aigü...), AltGr-v, where v is the appropriate vowel, and Shift-AltGr vowel were used to get, respectively, vowel-circumflex and vowel-diaeresis. Nowadays, dead keys work with most of the programs except for Netscape or Applixware so these shortcuts are still very much appreciated.
If AltGr-e already outputs è, where could the euro be placed?
This hard problem is yet to be solved by any keyboard maintainer; for the French one I am in charge of, I decided to rearrange the “dollar” ($)/ “British pound” (£)/ “international currency symbol” (¤) keys. Since none of these symbols is an official French money, I changed it to “euro”/“eurocent”/“dollar”/“British pound” respectively normal, Shift, AltGr and AltGr-Shift state. However, French keyboard official standard will use AltGr>-e for euro, so I had to change back this key, remove unavailable international currency symbol and find a new home for “e circumflex”, which was in AltGr-e under Linux. I decided to put dollar/British pound/eurocent/e circumflex on this key, only ¤ and ê had to be moved. This was the best possible solution I could imagine, but I am still looking for another solution to ease euro accessibility and keep 8-bit characters shortcuts.
I also added the other latin9 characters, in AltGr-Shift state for the unused ones which can also be obtained by ^-sSzZ or “-Y, and in unshifted plus shifted state for the very common
On the screenshot, you can see a representation of the French keyboard with all shortcuts shown: “MAJ” means “Caps Lock”, “Ferme” means “Close”, “Arrèt défil” means “Scroll Lock” and “Con” keys are the extended PC 105 keys (also called “Windows key”) mapped to previous console, next console and last console. This ASCII art is included in fr-latin9.map key map to remind users where all the Linux-specific shortcuts are.
Now, with a font and a key table, it was getting more interesting. I started a beta-release program to get feedback, which was mostly positive. The only drawback was ê; some people wanted it to stay where it was so I showed them how to edit the key table to do this.
X fonts are not covered by GPL, while the rest of the package was going to be released under GPL. Since I could not find any iso-8859-1 latin1 X font with a GPL, I had to use an XFree copyrighted basis. With Mark Leisher's xmbdfed (mleisher@crl.nmsu.edu), I could very easily change some fonts. X window fonts are not scalable; you have to choose Adobe or True-Type fonts (with xfdtt for the latter). Also, I didn't feel like editing all the fonts included with X. No real solution exists at present, except switching XFree to True-Type fonts, which would be a good idea since True-Type fonts are scalable, of good quality, many are released under GPL, BSD or public domain licenses and they already support the whole range of latin1 plus latin9 thanks to the cp1252 proprietary format.


{kind=link}
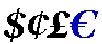{kind=link}
{kind=link}
{kind=link}