
Security Research Laboratory and Education Center
Keeping the bandits out is not the only reason you will need educated security experts to maintain your system in the future. What will happen when the demand for security administrators is so high your firm cannot afford them? Or if the total development cost for secure software is more than the debt in the U.S. alone? Your answer to my last question may be, “We will use open-source code”--good point! However, you will still need experienced security personnel to maintain your system.
As most of the industry is struggling to prepare their systems for the year 2000, academia is facing the problem of educating enough computer scientists. Government reports predict that in the year 2000, on-line commerce in the U.S. alone will exceed 15 billion dollars per year, and the sales of security software will exceed two billion dollars per year. The need for increased training and research in information security will only expand in the coming years as the use of wide-area computer networks spreads.
As computer crime is increasing, Purdue University in Indiana is addressing the issue. For the last seven years, the Purdue Computer Science Department has been the home of the Computer Operations, Audit and Security Technology (COAST) laboratory. COAST is one of the largest academic research groups and graduate studies laboratories in practical computer and network security in the world. The laboratory is expanding into a newly established center.
Purdue's University Center for Education and Research in Information Assurance and Security (CERIAS as in “serious”) is a pioneer in the area of information security. This new university center was designed to educate the next generation of computer and network security specialists. With projects encompassing Linux, Solaris, Windows 95/NT, smart cards, iButtons, biometrics, ATM networks and firewalls, their research will work toward the goal of reducing the threat of so-called information warfare.
The director of the laboratory and of the newly founded center, Professor Gene Spafford, is a computer scientist who has been a major contributor to the discipline of information security. Spafford is an ACM (Association for Computing Machinery) fellow and has written several books on information security. He also helped to analyze and contain the Internet worm in 1998. Together with 15 faculty members and 40 graduate and undergraduate students (see Figure 1), he is steering the center toward a common goal: to provide world-class research and education in information security.

Figure 1. Professors, staff and students in the COAST/CERIAS facility at Purdue University
Currently, the faculty and students are drawn heavily from the computer science area. However, the center is opening its doors to a diversity of disciplines (e.g., philosophy, linguistics, political science, industrial engineering, management, sociology and electrical and computer engineering).

Figure 2. The Graduate Student COAST Laboratory
The laboratory (see Figure 2) and the new center have attracted professors and students from 13 countries. One reason is that there are few highly competent academic security laboratories with industry support. The diversity does not end with nationality—almost 40 percent of the students are female. Security has drawn the interest of women since the early days, and the number of female students has been increasing steadily in the last few years.
The research includes audit trails format and reduction, network protection, firewall and software evaluation, creation of a vulnerabilities database and testing. Additionally, several undergraduate projects dealing with authentication and security archive are in progress. The main COAST projects are described briefly below.
Intrusion Detection (ID) is a field within computer security that has grown rapidly over the last few years. The AAFID (autonomous agents for intrusion detection) project in the COAST laboratory is about intrusion detection.
Traditional intrusion detection systems (IDS) collect data from one or more hosts and process the data in a central machine to detect anomalous behavior. This approach has a problem in that it prevents scaling of the IDS to a large number of machines, due to the storage and processing limitations of the host that performs the analysis.
The AAFID architecture uses many independent entities, called “autonomous agents”, working simultaneously to perform distributed intrusion detection. Each agent monitors certain aspects of a system and reports strange behavior or occurrences of specific events. For example, one agent may look for bad permissions on system files, another agent may look for bad configurations of an FTP server, and yet another may look for attempts to perform attacks by corrupting the ARP (address resolution protocol) cache of the machine.
The results produced by the agents are collected on a per-machine level, permitting the correlation of events reported by different agents that may be caused by the same attack. Furthermore, reports produced by each machine are aggregated at a higher (per-network) level, allowing the system to detect attacks involving multiple machines.
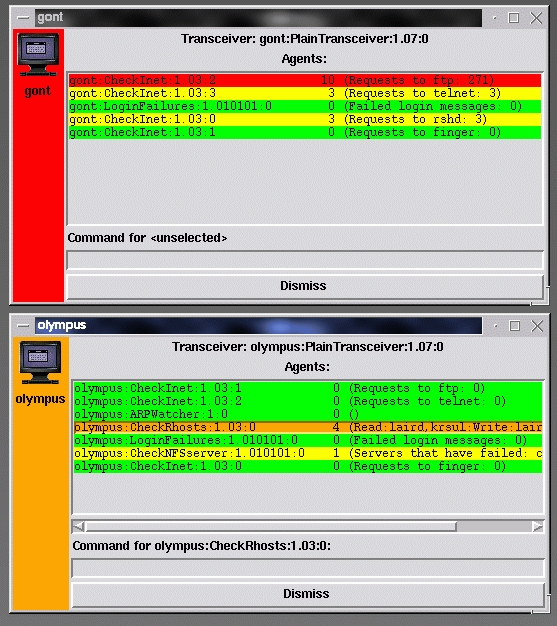
Figure 3. The Agent Window of the AAFID Prototype
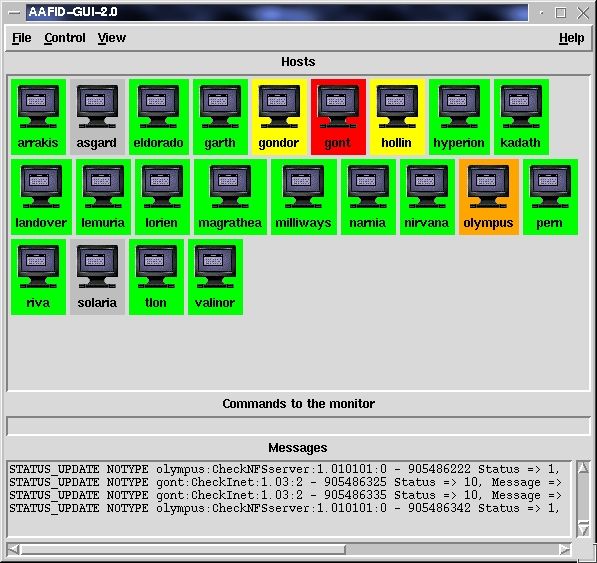
Figure 4. The Main Window of the AAFID Prototype
The AAFID group consists of ten graduate and undergraduate students within the COAST laboratory. A prototype implementation (see Figures 3 and 4) can be found on the AAFID project web page at http://www.cs.purdue.edu/coast/projects/autonomous-agents.html.
During the past several years, students at Purdue have been maintaining the Internet's largest on-line archive of security-related tools, papers, standards, advisories and other materials. The main problem they face is the efficient management of such highly dynamic information. The group will mirror constantly changing sites and will maintain the most recent copies of those sites. Additionally, new sites are continually starting up—new papers, new tools and more information that must be added to the archive.
The other major concern is being able to find what they are looking for in the archive. With so much information, it is difficult to navigate through all the data. The Archive group has used a combination of Red Hat Linux 5.2 and the open source ROADS (see Resources) document ordering system to build the prototype. This will transform the FTP-based archive to an HTTP-based information system, allowing users to search based on different criteria or enter a Yahoo-like browsing mode. The group always welcomes contributions and suggestions (security-archives@cs.purdue.edu).
One of COAST's better-known projects is Tripwire. It was primarily a project of Gene Kim and Professor Gene Spafford. The product is now used worldwide and is the most widely deployed intrusion detection security tool. Tripwire is an integrity monitoring tool for Linux and other UNIX systems. It uses message digest algorithms to detect tampering with file contents that might have been caused by an intruder or virus. In December 1997, Visual Computing Corporation obtained an exclusive license from Purdue University to develop and market new versions of the product. Tripwire IDS 1.3 has been released for Linux. For more information, see the web site http://www.tripwiresecurity.com/.
The Underfire team consists of seven graduate and undergraduate students. Their goals are to gain direct experience in the installation, evaluation, configuration and usage of different firewall systems; to investigate new technologies for network perimeter defenses, including next-generation networks such as ATM; and to investigate the integration of host- and network-based security mechanisms with network perimeter defenses. Underfire is an ongoing project which began in 1997.
The Underfire team's main goal is to create an architecture for automated firewall testing. The final product will be an engine that will test a firewall without human interaction. This will be achieved with a modular system: the engine, a packet sniffer and scripted attacks. The engine executes the attacks and uses the packet sniffer, or other networking protocols, to test the success or failure of the attack. Finally, a report can be automatically generated that explains the weak points of the firewall based on the attack data.
Having finished the design and initial implementation of the engine, the Underfire team is currently scripting known attacks. The automatic report generator is something that will also need to be completed in the future. Until now, Underfire has taken only protocol level attacks into account; a future step will be to extend the tests to the application level such as RPC and X11.
The need to change the old-fashioned login name and password procedure of authentication is an obvious place to base research for the laboratory. By using biometrics devices and tokens such as smart cards and iButtons, several research and application development projects can be conducted in this area. Security tokens under Linux will provide a wide array of security features for the multiuser operating system.
One of the COAST students heads the MUSCLE project (Movement for the Use of Smart Cards in a Linux Environment), one way to integrate security tokens into the Linux environment. MUSCLE focuses on smart card and biometrics security under Linux and consists of several projects. The first is standardizing on a PC/SC-compliant smart card resource manager written in C++, along with cryptographic libraries based on the Public-Key Cryptography Standards (PKCS-11 and PKCS-15). The resource manager also allows secure remote authentication by using secure channels to communicate between multiple resource managers. The resource manager will be used to develop many applications, including secure login, ssh, xlock, FTP, TELNET, et al., via pluggable authentication modules (PAM) along with smart card security.
MUSCLE supports a wide array of smart card readers along with ISO-7816-4-compliant smart cards. On the web site, you can find many different smart card specifications, source code for different projects, on-line tutorials and a mailing list. MUSCLE can be found at http://www.linuxnet.com/.
COAST graduate students have been studying ways of enhancing audit trails on Linux systems. Additionally, penetration and vulnerability analysis efforts have benefited from the use of Linux machines with the enhanced auditing systems.

Figure 5. Network Auditing Trail
Generally, operating systems' audit trails or logs are inadequate for a variety of applications such as intrusion detection. The students have developed two different approaches to enhancing the data collected by Linux. One approach was to use the technique of interposing shared objects to collect new application-level audit data. Using this technique, a program can be instructed to record and act upon certain library calls and their arguments without modifying the binary or source code of the program. (See Figure 6.)
Figure 6. Snapshot of the Kernel Code
Another part of the project involves using a Linux 2.0.34 kernel (see Figure 7.) to audit low-level network data. This involves adding a mechanism to the kernel to report network packet headers to user processes. By correlating these data and intrusion detection systems, host-based intrusion detection systems can detect low-level network attacks such as “Land”, “Teardrop” and “Syn floods”. This mechanism uses a version of the existing kernel log code, modified to accommodate arbitrary binary data.
The vulnerability database and analysis group at COAST is collecting and analyzing computer vulnerabilities for a variety of purposes. The project includes the application of knowledge discovery and data mining tools to find non-obvious relationships in vulnerability data, to develop vulnerability classifications and to develop tools that will generate intrusion detection signatures from vulnerability information. One goal of the group is to develop methods of testing software in order to discover security flaws before the software is deployed.
In the words of Professor Spafford:
With the increasing use of computers and networks, the importance of information security and assurance is also going to increase. Concerns for privacy, safety and integrity may soon become more important to people than speed of computation. This represents a tremendous challenge, but also a tremendous opportunity for those who seek to understand—and provide—workable security.

