
Multilink PPP: One Big Virtual WAN Pipe
Network management is a little like alchemy: take a dash or two of ISDN, add some frame relay, throw in a couple of routers, mix them all together, and somehow, some way, the result is bandwidth gold.
Of course, the formula for creating fully interoperable networks is much more complicated. Fortunately, network managers do have access to some tools that can make bandwidth magic a little easier to perform. Two of the most important elements in the technology bag of tricks are the point-to-point protocol (PPP) and its follow-up, the multilink point-to-point protocol (MLPPP).
PPP, a product of the Internet Engineering Task Force (IETF), is the de facto WAN link protocol for connecting clients and servers and for interconnecting routers to form enterprise networks. PPP's main advantage is that unlike other protocols which operate at the data link layer, PPP achieves interoperability between devices by negotiating different configuration options, including link quality, link authentication and network protocols.
Over the years, the IETF has made some significant changes to PPP. But as its name states, PPP is intended for simple point-to-point connections. Now that the enterprise network infrastructure is moving rapidly to digital switched services such as ISDN, frame relay and ATM, PPP is in need of even more changes.
Enter MLPPP, known in IETF circles as RFC (Request for Comment) 1717. MLPPP takes advantage of the ability of switched WAN services to open multiple virtual connections between devices to give users extra bandwidth as needed. With MLPPP, routers and other access devices can combine multiple PPP links connected to various WAN services into one logical data pipe.
The IETF formally approved the MLPPP specification last November. Makers of ISDN routers and access devices have already started using MLPPP to bundle 64Kbps ISDN B channels to deliver more bandwidth. MLPPP also allows network managers aggregate WAN circuits of different types without requiring major configuration changes to existing router Internet works.
Because MLPPP works over any switched WAN service, it has a wide range of potential uses (see “PPP Plus”). Network managers could deploy MLPPP-equipped devices to create a technology-independent enterprise framework in which the actual WAN services linking two devices would be invisible to end users. Under this model, WAN devices would negotiate bandwidth rules between two directly connected peers, using whatever type of service was available. New digital WAN services such as ATM (asynchronous transfer mode) could be added to the network mix as needed, without making the existing network infrastructure obsolete.
Although it is usually considered a single entity, PPP is actually a group of protocols that together provide an extensive set of network connectivity services. The PPP suite is based on four key design principles: negotiation of configuration options, multi-protocol support, protocol extendibility and WAN service independence.
Negotiation of configuration options: This refers to PPP's ability to establish throughput requirements between two directly connected end systems. In an enterprise network, end systems often differ in terms of buffer requirements, packet-size limits and network protocol-support lists. The physical link that interconnects any two end systems could vary from a low-speed analog line to a high-speed digital connection with varying degrees of line quality.
To cope with all these possibilities, PPP has a suite of standard default settings to handle all common configurations. To establish a link, two communicating devices attempt to use these default settings to find a common ground. Each end of the PPP link describes its capabilities and requirements; the settings are negotiated between the two sides for each option at the link level. These options include data encapsulation formats, packet sizes, link quality and authentication.
The protocol that negotiates all these options is known as the link control protocol (LCP). The protocol that negotiates the network protocols to be multiplexed over a PPP link is called the network control protocol (NCP); there can be many NCP data streams over a single PPP link. Although PPP's configuration negotiation options also allow end systems to set link peer authentication (a security function) and data compression options, PPP does not dictate the actual algorithms used for security or compression. For security, PPP defines PAP (password authentication protocol) and CHAP (challenge handshake authentication protocol) as common standard authentication methods that may be negotiated, but it also lets users add new authentication algorithms. The same holds true for compression.
Multi-protocol support: PPP's ability to handle multiple network-layer protocols was one of the chief reasons it became a de facto standard. Unlike the serial IP protocol (SLIP), the IETF routing protocol that handles only IP datagrams, PPP works with a range of packet formats including IP, Novell IPX, AppleTalk, DECnet, XNS, Banyan Vines and OSI. Each network-layer protocol is separately configured by the appropriate NCP.
Protocol extendibility: Over the years, the IETF extended PPP through a number of additional RFCs that define features like common data authentication services and encryption capabilities for security and compression algorithms. For example, with many WAN technologies, compression algorithms are chosen according to the quality of the link. Different technologies use different compression schemes, introducing multiple layers of compression and decompression into the network. Running PPP compression at the NCP level removes these considerations and uses fewer system resources.
WAN service independence: The initial version of PPP was built expressly to run over HDLC (high-level data link control) networks. Since then, the IETF has added RFCs that enable PPP to work with every major WAN service now in use including ISDN, frame relay, X.25, Sonet and synchronous/asynchronous HDLC framing.
For all its strengths, PPP has one inherent limitation when it comes to network deployment: it is designed to handle only one physical link at a time. MLPPP does away with this restriction. MLPPP is a higher-level data link protocol that sits between PPP and the network protocol layer. It accommodates one or more PPP links, with each PPP link representing either a separate physical WAN connection or a channel in a multichannel switched service, such as ISDN or frame relay.
MLPPP's ability to combine multiple lower-speed links into a single, higher-speed data path is often referred to as WAN-independent or packet-based inverse multiplexing (see “WAN Independence” below). Packet-based inverse muxing isn't new; for instance, ISDN vendors have been offering ways to combine multiple ISDN 64Kbps B channels for some time. But up to now, these solutions have been proprietary: vendor and technology-specific. MLPPP embodies a standard approach that cuts across vendor and WAN technology lines.
MLPPP negotiates configuration options the same way as conventional PPP. However, during the negotiation process, one router or access device indicates to the other communicating device that it is willing to combine multiple connections and treat them as a single physical pipe. It does this by sending along a multilink option message as part of its initial LCP option negotiation.
Once a multilink session is successfully opened, MLPPP at the sending side receives network protocol data units (PDUs) from higher-layer protocols or applications. It then fragments those PDUs into smaller packets, adds an MLPPP header to each fragment and sends them over the available PPP links (see Figure 1). On the receiving end, the MLPPP software takes the fragmented packets from the different links, puts them in their correct order based on their MLPPP headers and reconverts them to their original network-layer PDUs.
Figure 1. The Multiprotocol Link
MLPPP is independent of the actual physical links and the WAN services that run over them. This means MLPPP traffic can traverse a mix of physical and logical connections from multiple WAN services—a frame relay virtual circuit, multiple ISDN channels and an X.25 connection, for example. MLPPP functions as a logical link layer that dynamically adds or removes links between two communicating devices as bandwidth needs change. The MLPPP standard does not dictate how traffic is balanced over these member PPP links, leaving network managers free to determine how to use the available links or channels.
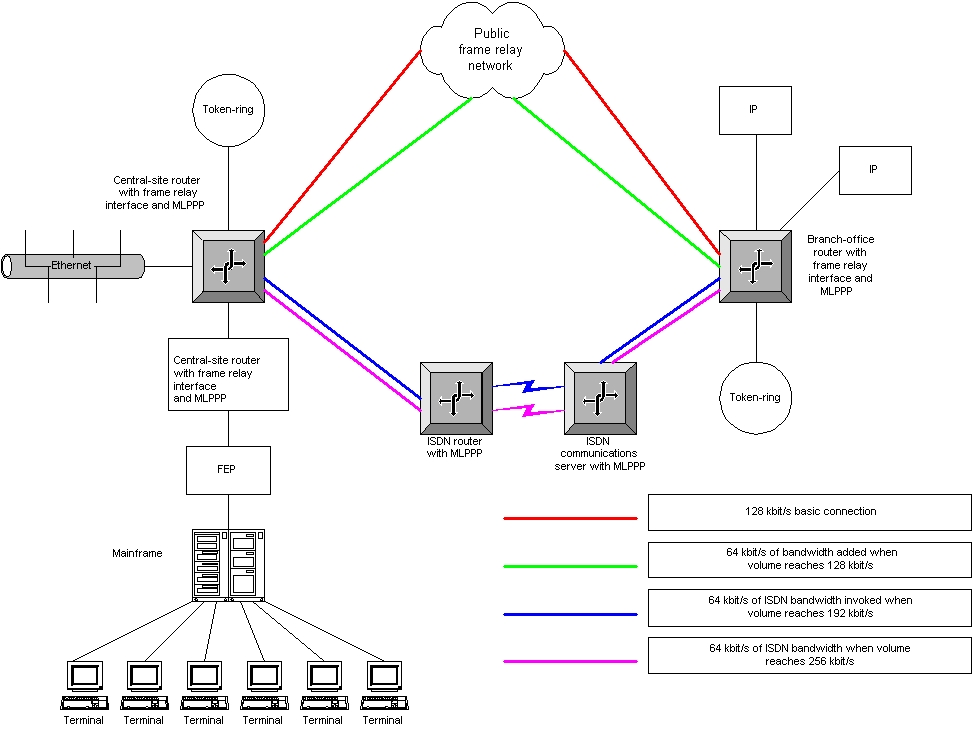
MLPPP's ability to combine separate PPP links into one logical data pipe is one of the most important features of the protocol. It allows additional WAN bandwidth or new WAN services to be added as needed without disrupting the existing WAN infrastructure. With MLPPP, different WAN services such as ISDN, frame relay and ATM can be used together. For instance, a network manager can establish a frame relay connection to serve as the primary link between a central site and a branch office, with ISDN serving as an adjunct when bandwidth demand rises (see Figure 2).
Figure 2. Many Circuits, One Pipe
Through the dynamic addition and deletion of PPP links, MLPPP enables dynamic bandwidth allocation, or “rubber bandwidth”, between two peer systems. During the LCP option negotiation, all PPP links in an MLPPP group identify themselves as belonging to the same group or bundle. To add a new link or WAN service to the bundle, all that's required is attaching the appropriate MLPPP group identifier to the link. Likewise, when a member PPP link is terminated, it is automatically removed from its parent MLPPP bundle by eliminating the identifier.
PPP is WAN service-independent, so the member links of an MLPPP bundle can be associated with either permanent virtual circuits (PVCs), which have fixed end points, or switched virtual circuits (SVCs), which are dialed up on demand.
MLPPP's ability to create different groups of WAN links produces some intriguing possibilities for network managers. For instance, they could use MLPPP to segregate traffic according to the network-layer protocol. This approach would enable network managers to separate expedited control messages from normal data traffic or to queue data into separate MLPPP bundles based on application-specific requirements.
Here's an example of how MLPPP's segregated packet queueing works. Suppose a central site is connected to a remote site via two 64Kbps frame-relay links and two ISDN basic-rate interface (BRI) connections. Two types of traffic traverse these links: IP traffic from UNIX operations and DECnet traffic from a Digital Equipment Corporation VAX network. If the frame relay and ISDN channels are treated as one MLPPP bundle, both traffic types have access to the full bandwidth of the link at any given time.
The single-pipe approach makes for easier network management, but it could create problems if one traffic type starts dominating the pipe. In this example, if the UNIX IP traffic started bursting beyond 60 percent of the overall link rate, it would begin to eat into bandwidth available for DECnet, slowing performance for users on the VAX network.
With MLPPP, this problem can be avoided. The network manager can not only combine various physical interfaces to create one large pipe, but also allocate channels within that virtual pipe. For instance, the network manager can create two 128-kbit/s MLPPP bundles, each consisting of a single ISDN B channel and a 64Kbps frame-relay link. Those bundles could then be dedicated to each type of traffic.
One big problem with using routers for switched WAN services isn't activating a link, but shutting it down when data transfer is done. Most LAN protocols and client-server applications are chatty, carrying on almost incessant messaging to synchronize routing databases and maintain client-server sessions.
Left unchecked, these processes can keep an ISDN link up indefinitely without passing a single byte of application data. Needless to say, all this uptime quickly adds up, especially where charges are based on call duration. Considering that more than 35 percent of WAN costs are related to line costs, the ability to control activation and deactivation of member links in an MLPPP group is crucial.
MLPPP offers two solutions: usage thresholds and spoofing. In the usage threshold scheme, once a circuit becomes idle or the traffic it carries falls below a level predefined by the network manager, MLPPP will automatically remove that circuit from its bundle until demand rises. The problem with the usage threshold approach is that it can be difficult to define threshold levels effectively in bursty environments using chatty protocols. For example, in Novell IPX environments, it can be difficult to gauge the requirements of SAP (service advertising protocol) and RIP (router information protocol) messages.
Spoofing helps address this problem. It is a technique used by routers to filter network traffic. Spoofing keeps unnecessary traffic like session keep-alive messages from traversing the WAN link. Rather than sending these messages over the WAN, the router acts as a proxy and responds to them locally. Once the router takes over the polling and responses for the application, the WAN link can be shut down until it is truly needed.
MLPPP's WAN service independence means users and network managers can be insulated from network service changes. As new WAN services, such as frame relay and ATM become available, MLPPP can be used to incorporate them into logical bundles. To routers, MLPPP looks like a data link protocol; the router doesn't have to deal with the complexity of the various physical connections and switched circuits that MLPPP draws together in its logical pipes. This helps reduce router reconfiguration costs, since a new router interface isn't required when a new WAN service is added.
To network managers, the difference between adding a new circuit or virtual circuit to an MLPPP bundle and adding a router interface is significant. Adding a circuit to a preexisting MLPPP logical pipe is transparent to the network, particularly in switched environments like ISDN, frame relay or ATM. It simply adds bandwidth to the pipe; no additional interfaces or path information is required. In contrast, any change to a physical router interface triggers an update to the routing table of every router involved in the change. In environments where circuits are frequently activated and deactivated, this could generate excessive amounts of network topology changes and much extra work for network managers.
Not only can MLPPP save network managers time and effort, but it also offers an important tactical tool for network designers. It can be used to simplify fault management and build redundancy into the network at low cost.
Along with making use of WAN services already in place, MLPPP is positioned to work with technologies just making it to the real world. The most prominent of these technologies is ATM.
ATM SVCs can be activated and deactivated on demand, much like ISDN circuits. ATM circuits can be included in an MLPPP circuit group as more bandwidth is required. Bundling will become especially useful if lower-speed ATM ports (T1 or T3) become widely deployed.
In the long run, as ATM takes over the enterprise network backbone, things could get more complicated. ISDN, frame relay and ATM will dominate the WAN landscape, with ISDN and frame relay functioning as a feeder technology and ATM serving as the enterprise backbone aggregating ISDN and frame-relay circuits over faster pipes. An ATM pipe at Sonet OC3 speed (155Mbps) can aggregate more than 2,400 64Kbps ISDN B channels.
That is a large amount of bandwidth by today's standards, but thanks to the rise of LAN switching and high-speed LANs, aggregate throughput requirements for the LAN will escalate at an even more rapid rate, reaching tens of gigabits per second in the next few years. To reduce the disparity between the LAN and WAN worlds, network managers will need to aggregate B channels and frame-relay circuits. Inverse multiplexing using MLPPP offers a flexible way to do this.
MLPPP delivers some key functions to help network managers build multi-protocol enterprise networks. Here are some of MLPPP's strongest selling points:
Mix-and-match WANs: With MLPPP, net managers can configure multiple physical links and virtual circuits as one logical pipe, using different WAN service types (ISDN, frame relay, X.25 and ATM) in the process.
Bandwidth on demand: Circuits can be activated and added automatically to a logical pipe when more bandwidth is needed, or if one of the links in the logical pipe fails.
Big protocol tent: MLPPP handles routing for all major network- and transport-layer protocols, including IP, IPX, Netbios, DECnet and SNA.
Network negotiation: MLPPP has inherited PPP's ability to negotiate configuration options between communicating devices. This means two end systems can set the terms of transmission without requiring manual intervention.
No traffic, no link: MLPPP uses LAN protocol spoofing to keep unnecessary network traffic, such as session keep-alive packets, from traversing the WAN.
The two basic types of inverse multiplexing are circuit-based and packet-based. Under the circuit-based scheme, a data stream is sliced into equal portions, regardless of its contents, with each portion transmitted over a different available circuit. With circuit-based inverse muxing, synchronization of traffic streams is generally handled by hardware.
Packet-based inverse multiplexing is a software-based process. In this scheme, packets are distributed among available circuits according to rules or policies that govern allocation of traffic across circuits. These rules can include segregation according to protocol or percentage-based prioritization. The multilink point-to-point protocol (MLPPP) uses packet-based inverse multiplexing.
One key difference between the two approaches is that packet-based inverse multiplexing schemes can handle multiple circuit types, while circuit-based schemes cannot. With MLPPP, for example, a synchronous 56Kbps X.25 link can be bundled together with a 64Kbps ISDN B channel to create a single logical pipe offering 120Kbps of bandwidth. This bundling ability extends to the full range of available WAN services, including dial-up analog lines, switched 56Kbps services, frame-relay connections and T1 or T3 services.
Another difference is that packet-based inverse multiplexing is seamless to the destination router or end system. In the case of MLPPP, the flow of data appears consistent by means of software synchronization of MLPPP fragments. In contrast, circuit-based inverse muxing requires the receiving device to stop data flow until all bonded channels are characterized for latency. This is the only means by which the hardware-based solution can ensure data is received in the correct order.
Except for applications that require constant bit rate transmission or have strict requirements on circuit latency, software-based solutions are generally regarded as superior because they add considerable value and flexibility to the basic inverse muxing function. In the case of MLPPP, users are able to combine different WAN connections while taking advantage of PPP's configuration negotiation and multi-protocol routing support.
This article was originally published by Data Communications and can be found on the web at http://www.data.com/tutorials/multilink_ppp.html.
George E. Conant is a cofounder of Xyplex Inc. (Littleton, Mass.), a maker of internetworking products.


{kind=link}
{kind=link}