
DECnet Network Protocol

DECnet was designed by Digital as a way to interconnect their range of products. In its Phase IV implementation, released in 1983, it can support 63 areas of 1023 nodes each. The specifications for DECnet Phase IV are freely available (see Resources), which has allowed others to provide DECnet connectivity in products such as Sun's Sunlink DNI and Linux.
In networking terms, DECnet is an old standard. Its limited address space is far less than that of TCP/IP and it does not have the advanced features of more modern networking standards. DECnet is still widely used in legacy systems, and the intention of the Linux DECnet project was to allow integration of those systems with Linux-based solutions.
The Linux DECnet project intends to support only Phase IV DECnet, since previous versions in current use are very limited in number these days. LAT, another network protocol designed by Digital, will not be supported because it is covered by patent protection and its specifications are not freely available. In this article, we will use the term “DECnet” to mean the DECnet Phase IV family of protocols.
DECnet can be carried over a variety of different data link layers. In the beginning, the Linux kernel DECnet layer will support only the Ethernet link layer; support will be added later for other link layers such as PPP, DDCMP and X.25. The PPP link layer is described in RFC1762 and the others are described in the DECnet documents (see Resources).
Like many network protocols, DECnet can be viewed as consisting of a number of software layers. More details are included in the section called “A Tour of the Kernel Sources”.
At the top of the stack is the application layer, which includes all the programs used on a day-to-day basis. These programs use the system libraries and system calls to create connections to other nodes. The kernel socket layer interface and the system libraries encompass what the DECnet standard refers to as the session control layer. It performs largely the same function as the library and system calls for TCP/IP. Further down is the network services protocol (NSP), fairly close to TCP in function. Below these is Routing, which does more than routing; it is a kind of IP and ARP rolled into one. At the bottom of the heap is the actual device over which the data is transmitted.
Each machine, called a node in a DECnet network, is identified by an address consisting of a 6-bit area number and a 10-bit node number. These two numbers are written separated by a dot, so 1.2 is a computer in area 1 with a node number of 2. Unlike TCP/IP, the address refers to the computer, not the interface through which communication is to take place.
Two different sets of patches are available to add DECnet support to the kernel. The currently available code is based upon a patch written by Eduardo Serrat for the 2.0.xx version kernels to function as an endnode. In parallel with this, one of the authors, Steve Whitehouse, was also writing a DECnet layer with an emphasis on creating a router implementation.
The result is you can now get the original patch for 2.0.xx kernels written by Eduardo Serrat (a version of the same code ported to the 2.1.xx kernel series) and also another patch which has modifications by Steve to make use of the newer support functions in the 2.1.xx kernel series. This last patch will be distributed as an add-on for the 2.2.xx kernel series and later integrated into the next development series.
Most of what we say here applies equally to all versions of the kernel patches. We will point out the differences as we go.
First, you need to retrieve the correct patch for your kernel. In general, the best way to do this is to get a copy of the most up-to-date kernel in whichever kernel series you intend to use. You can then download and apply the latest patch to the kernel source as described below. I also strongly suggest that you study the release notes for the kernel version you have, since the configuration procedure may change.
To apply the Linux DECnet patch, unpack the kernel source into /usr/src/linux as normal. Then obtain the correct patch for this kernel version and uncompress it in the directory above the top-level Linux source directory, /usr/src/ in this case. Then type:
$ patch -p0 < patch-file
patch-file is the name of the patch you want to apply. Next you need to compile a kernel in the usual way, being sure to say Y or N to the question about including DECnet support. Depending on which version of the patch you have, some of the options outlined below may be available.
The two main types of DECnet nodes are endnodes and routers; the latter is subdivided into Level 1 and Level 2 varieties. At the time of writing, only endnode support is available.
When DECnet router support is available, you will need to enable the option at compile time. Also, at module load or boot time, you will have to turn it on—a kernel with router support compiled in will be able to function as both an endnode and a router.
The DECnet raw sockets option allows the reading and writing of DECnet packets at a lower level than users normally need. It is very useful for debugging and monitoring activity, and might be required by future user-level routing daemons. The main advantage of using this rather than a PF_PACKET socket is allowing a program to take advantage of the kernels filtering of invalid DECnet packets.
In order to use the DECnet kernel layer, you must also tell the kernel which DECnet address to use. This is the only point at which the instructions are dependent upon the kernel version being used. For 2.0.xx version kernels, you need the startnet program, which would normally be run in the boot scripts for your system. For the 2.1.xx version kernels and upward, the DECnet address can be set either on the command line with an option decnet=1,2 or when the module is loaded. (That is a comma, not a dot, between the 1 and 2 in the previous sentence.)
Those of you familiar with TCP/IP will recall that the ARP protocol is used to allow a machine to discover the Ethernet address of other nodes attached to the network. No equivalent of this protocol exists in DECnet; nodes must have their Ethernet address set according to their DECnet node address.
In order to work out which Ethernet address to use, you take the four byte “hiord” prefix specified by the DECnet protocol and concatenate it with two bytes xx and yy, derived from the DECnet node address of the node you are configuring.
AA:00:04:00:
xx and yy are the least and most significant bytes of the 16-bit DECnet address, respectively. The bytes are ordered this way because the original systems upon which DECnet was implemented had little endian CPUs. Thus, a node with address 1.1 will have an Ethernet address of AA:00:04:00:01:04 and a node with address 1.2 will have an Ethernet address of AA:00:04:00:02:04.
This address needs to be set in your Ethernet card before you start the card. On Red Hat systems, this is easy. You simply add the line
MACADDR=AA:00:04:00:02:04
to the file /etc/sysconfig/network-scripts/ifcfg-eth0 or whichever file corresponds to the Ethernet card you wish to use. If you are not on a Red Hat system, you will probably have to look through the startup scripts to find the ifconfig command for the relevant interface and add the options hw ether AA:00:04:00:02:04 at a suitable place. If you are using Slackware, then /etc/rc.d/rc.inet1 is the correct file to modify.
If this seems too complicated, a utility called dn2ethaddr can be used to print out the Ethernet address of a node given the DECnet address on the command line. It can also be used within scripts; an example is given in the man page.
The front end for the DECnet layer that most users will see is the file utilities, a collection of programs using the kernel socket layer to implement file transfer and other useful applications. Eduardo Serrat's original kernel patch came with a few example applications, which have been taken over by Patrick Caulfield and enhanced during the last few months.
Most of the supplied applications for DECnet use the DAP (Data Access Protocol) that performs a similar function to the FTP protocol in TCP/IP. DAP is one of many high-level protocols implemented on top of DECnet; cterm is another, which provides terminal access in a similar manner to TELNET on TCP/IP.
The applications use the OpenVMS transparent DECnet file name format to refer to files on remote machines. This syntax should be familiar to OpenVMS users, although it may look a little odd to Linux users.
nodename"
For example:
tramp"patrick mypass"::[docs.html]art.htmlThe more eagle-eyed will notice that typing this file name into the bash shell causes it all sorts of problems because the shell has special meanings for quotation marks and square brackets. To get around this, we have to enclose the entire file specification in single quotes:
dncopy 'tramp"patrick mypass"::[docs.html]art.html'\ art.htmlThis command copies the file from the OpenVMS system to our Linux machine. If you're wary about having passwords visible on the command line, read the sidebar on DECnet proxies. Although not every DECnet file name you type in will contain special shell characters, it is a good idea to get into the habit of using the single quotes so that you don't get unexpected effects if you forget them when they are needed.
The syntax of file names on an OpenVMS machine is also a bit different from that in Linux. Directories are enclosed in square brackets and delimited with dots. File names can have 39 characters on either side of the dot and both are case-insensitive. OpenVMS displays them in upper case but they can be referred to in lower case. The Linux file utilities will always convert the file names to lower case for you, since that is more convenient for Linux users.
OpenVMS treats a file as a collection of records rather than a stream of bytes. It likes to know how to delimit the records, whether they are fixed or variable length, and how to display them on the screen (carriage control).
The file utilities available in version 0.10 are:
dncopy: copies files between OpenVMS and Linux systems.
dntype: displays the contents of an OpenVMS file on standard output.
dndir: displays a directory listing.
dndel: deletes OpenVMS files.
dntask: execute commands on an OpenVMS system.
dncopy
dncopy is the most complex of all: it uses what may seem to be a bewildering list of options. A file on Linux is simply a collection of bytes, whereas OpenVMS has a very rich file system. Files can have different organizations, record formats and attributes (see “OpenVMS File Types and Attributes”).
dncopy has to cope with the task of making sensible conversions between the “a file is a file is a file” attitude of Linux and the more sophisticated OpenVMS system. When copying files from OpenVMS to Linux, OpenVMS makes all the information about the file available as part of the network protocol, so this operation rarely requires a user to understand the nature of the remote file.
When copying a file to OpenVMS, the situation is more complex. dncopy has to tell OpenVMS what type of file it wants to create, what the record format will be and any other optional attributes that may be required. We have tried to make the default as useful as possible, so that if you copy a Linux file to OpenVMS, you get a useful file. OpenVMS has a file type that is analogous to Linux files in the SEQUENTIAL STREAMLF file. This is a sequential file you can seek with records delimited by line-feed characters: when you use dncopy to send a file to OpenVMS, this is what you will normally get. In fact, dncopy goes further than that and actually looks for records in your file when it sends it in order to make it meaningful to OpenVMS.
STREAMLF files are fine, but often you want to send block-structured data files or OpenVMS savesets that have been backed up or downloaded from the Internet, or perhaps you want your text files to be in the more normal OpenVMS text file format. This is what all the complicated options in dncopy are designed to help you with.
A few examples may help illustrate. Normal OpenVMS text files have variable length records with implied carriage control. To send a file from Linux like this, we would type:
dncopy -rvar -acr myfile.txt \ 'tramp"patrick mypassword"::'
The option -rvar instructs dncopy to tell OpenVMS that the resulting file is to have variable-length records. -acr indicates that the records have implied (carriage-return) carriage control. Also notice the resulting file name has been left off. dncopy will use the base name of the source file (myfile.txt) in this case.
Alternatively, if you were sending a file to be used in a FORTRAN program, OpenVMS has a FORTRAN carriage control attribute, where the first byte of each record says whether to start a new line, new page, etc.
dncopy -rvar -aftn fortfile.txt \ 'tramp"patrick mypassword"::'
If you wanted to send an OpenVMS saveset (a bit like a Linux tar file), you would send a file with fixed-length records. The normal mode of dncopy is to send records, since records are what OpenVMS expects. Binary files have no real record structure so we must tell dncopy to send blocks of bytes and the size of those blocks. A common size for saveset files is 8192 blocks, so we could send a saveset file from Linux to OpenVMS with the command:
dncopy -mblock -b8192 saveset.bck\ 'tramp"patrick mypassword"::'dncopy takes wild-card characters for both Linux and OpenVMS file names. (OpenVMS wild cards must be used for OpenVMS files: % for a single character and * for multiple characters.) As a result, you can copy whole directories at a time. It can also redirect by using standard input and standard output as destination files, with the hyphen as a file name. In this way, you can embed OpenVMS files in Linux shell scripts and pipelines.
One “feature” of dncopy you may never need but which grew out of its object-oriented design is that it will also copy Linux to Linux and OpenVMS to OpenVMS. Note that if you do an OpenVMS to OpenVMS copy, all the data will pass through your Linux box on its way.
dntype
dntype is really just a symbolic link to dncopy that forces it to send the file to standard output; it is really there just to provide consistency and save typing.
dndir
dndir is a directory command (quite like ls in Linux). It displays the OpenVMS directory in a format similar to the ls command. It takes a few switches to customise the format, though -l is probably the most used, as it displays most of the useful information.
Two fields that look different from ls are the file size and protection information. The file size is shown in 512 byte blocks and the file protection information is shown in OpenVMS format rather than Linux format. I chose to leave the protection display this way, because OpenVMS has more file protection bits than Linux and it is often helpful to be able to see all the information.
dndel
dndel deletes OpenVMS files. Like dncopy and dndir, it can take an OpenVMS wild card file name to delete multiple files. With the -i option, you will be prompted whether you really want a file to be deleted.
dntask
dntask is the only one of these programs that does not use the DAP protocol; instead, it communicates with an arbitrary DECnet object. One little-used feature of DECnet on OpenVMS is that by using the syntax TASK=filename, the command filename.COM will be run as a command procedure (the OpenVMS equivalent of a shell script) and the output can be redirected back to the calling task. Three example tasks are provided with the distribution. One simply issues a SHOW SYSTEM command which sends its output to the Linux machine (using the command dntask tramp::show_system). The output from this is analogous to the Linux ps command. Another sends the -i (interactive) flag to dntask to allow the user to interact with a shell on the OpenVMS machine. However, the following example is the main reason dntask exists.
Eduardo Serrat, who wrote the kernel layer for DECnet, made sure it was compatible with X11R6. This means that if you have DECnet support compiled into your X server (see http://linux.dreamtime.org/decnet/Xservers.html for pre-built X servers with DECnet support), you can start X Window System applications on an OpenVMS machine and have them display on a Linux machine. This is a cheap and efficient way to provide X terminal support for OpenVMS systems. The dntask program can issue a command to start any X program to display on the Linux machine, provided you write a suitable remote command procedure. The example below shows a DECterm being started (something I personally use quite a lot), but it could also be used for more sophisticated things, such as starting a complete CDE session when a user logs in to Linux and starts X.
dntask 'tramp::decterm'
Eduardo also provides the following useful DECnet utilities:
sethost provides terminal access to OpenVMS machines, similar to TELNET.
ctermd is a daemon that provides the opposite service, allowing OpenVMS users to SET HOST (or TELNET if you prefer) to a Linux machine.
dnmirror and dnping are test utilities for checking that the software is installed correctly and verifying connections to particular OpenVMS nodes.
All the above utilities and the X servers depend on libdnet which is available from our web site (see Resources).
For the kernel hackers, here is a quick spin around the relevant source files. This section applies only to the newer kernel patches (i.e., for the 2.1.xx series and up), as those are the ones we expect you'll find most interesting and useful.

Figure 1. DECnet Software Layer Diagram
A diagram showing the overall layout of the Linux DECnet layer is shown in Figure 1. Where we describe the DECnet protocol, we go into just enough detail to give an idea of the main features of each part of the kernel code. If you want to know more about the way the kernel code works, you will need to read a copy of the DECnet specifications (see Resources) and then look at the source directly.
The main source file is af_decnet.c. This file contains the socket layer interface and parts of the DECnet NSP and session control layer code. Since the DECnet layering model does not map exactly onto the socket code, session control is provided partly by the kernel and partly by a user space library called libdnet.so.
dn_raw.c contains the code which implements the raw socket layer. It was one of the first things written, since it is very useful when debugging to see what is going on “under the hood”. It is also a good example of how to write the simplest socket layer interface possible. The file is compiled only when the raw sockets option is configured.
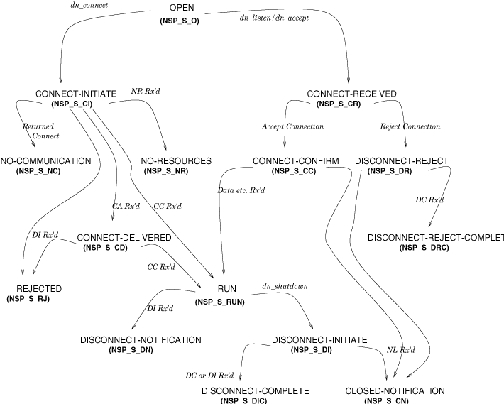
Figure 2. State Diagram of the NSP Layer
The rest of the NSP layer is divided into two parts: one for dealing with outbound packets, dn_nsp_out.c, and one for incoming packets, dn_nsp_in.c. The state table for the NSP layer is shown in Figure 2. We won't say much about the diagram here, but it should be a useful aid when used in conjunction with the kernel code.
The Routing layer is rather problematical. It has been divided into several files, due to the fact that the Routing layer actually does much more than just routing. dn_route.c is the main file which deals with incoming and outgoing packets, and dn_dev.c provides support for device-specific functions.
dn_neigh.c has a split personality. When a node is running as an endnode, it provides the On-Ethernet Cache described in the DECnet specifications; for routers, it provides the adjacency database. Since they are so similar, the decision was made to merge the two functions in order to keep the code small.
The actual routing functions (compiled only when the node is configured as a router) are in dn_fib.c. The code in this file is very experimental at this time, as decisions are still being made regarding how much of the routing should be done in user space and how much in kernel space.
One of the more obscure and important parts of the code is the main path for outgoing data packets. The DECnet layer uses the protocol-independent destination cache written by Alexey Kuznetsov, and neighbor table code written by Alexey Kuznetsov and Pedro Roque. These were originally designed to do some common processing required by the IPv4 and IPv6 network protocols, with the intention that other protocols would begin to use them at a later date.
What exactly do these two bits of code do? We will start by describing the neighbor table. The idea behind this is simply to keep a list of known nodes which are directly connected, along with certain information used by the protocol in question to communicate with them. In the case of TCP/IP, this means the ARP subsystem; for DECnet, it is used to hold one of two things. For endnodes, it holds the list of known nodes on the directly connected networks with which communication can be established, known as the On-Ethernet Cache. For routing nodes, it holds what the specifications describe as the adjacency database. In both cases, the function is the same but the actual method of operation is slightly different.
In the endnode case, hello messages are sent by routers every ten seconds to all endnodes that are directly connected. They are used by the endnode to create entries in the On-Ethernet Cache. Should a hello message not be received for a certain length of time, normally one minute, the entry is removed from the list. A default router is a directly connected node to which packets should be sent if the endnode is not connected directly to the destination. The default router is determined by information in the received hello messages.
For routing nodes, hello messages are received from both endnodes and other routers and are used to update the adjacency table. In this case, the entries are removed if no hello messages are received for a length of time—a specified multiple of a time length noted in the hello messages. Currently, the neighbor table does not support different timeouts for each different neighbor. This problem is being worked on and may be solved by the time you read this.
One other piece of information held in the neighbor table is the format of header to be used by the routing layer in transmitting NSP data. There are two formats, one for use over broadcast links (long format) including Ethernet, and one for use over point-to-point links (short format). This is done by setting a pointer to a function to the correct routine dn_long_outout or dn_short_output when the table entry is created.
The destination cache is based on principles similar to the neighbor table. However, the object is to hold information required for each destination. When a packet is to be sent to a certain destination, it is looked up in the destination cache to see if it exists. If so, then that entry is used; if not, a routing algorithm must be called to discover the correct destination.
The routing algorithm also depends upon the routing or non-routing type of the node. The algorithm for routers has not been properly implemented yet, but will reside in the file dn_fib.c when that time comes. For endnodes, the algorithm is simply to send directly to any node in the On-Ethernet Cache, to send to the default router if it is not in the cache, or to send directly if there is no default router.
Again, a function pointer is available in each destination entry for a routine that will add destination-specific information to outgoing packets, then call the output routine of the neighbor.
That about wraps up the main features of the kernel code. There is, of course, a lot more to it than what is mentioned here, but we hope our overview will be useful if you're planning to add features or help with debugging. If you have specific questions, we'd be happy to try to answer them; however, please read the documentation first and also remember that we may not always be able to send an answer right away.
Hopefully, we have given you a good overview of the Linux/DECnet connectivity available at the time of writing. However, we are still hard at work on new features and programs (see below), some of which may be ready by the time this is printed.
dapfs is a file system layer for Linux which will let you mount an OpenVMS file system onto your Linux machine.
fal is a file listener for Linux, which will allow users on OpenVMS machines to access files on network Linux machines without having to log in.
Router support is also being worked upon. This is expected to take the form of a small amount of kernel code and a user-level daemon. It will allow you to connect multiple DECnet networks to your Linux machine.



