
T/TCP: TCP for Transactions
T/TCP is an experimental extension for the TCP protocol. It was designed to address the need for a transaction-based transport protocol in the TCP/IP stack.
TCP and UDP are the current choices available for transaction-based applications. TCP is reliable but inefficient for transactions, whereas UDP is unreliable but highly efficient. T/TCP sits between these two protocols, making it an alternative for certain applications.
Currently, several flavours of UNIX support T/TCP. SunOS 4.1.3 (a Berkeley-derived kernel) was the very first implementation of T/TCP, and made available in September 1994. The next implementation was for FreeBSD 2.0, released in March 1995. For my final-year project, I implemented T/TCP for Linux at the University of Limerick in April 1998. The source code is available at http://www.csn.ul.ie/~heathclf/fyp/.
In this article, I discuss the operation, advantages and flaws of T/TCP. This will allow application developers to decide when T/TCP is appropriate for networking applications. I present my results from a comparative analysis between T/TCP and TCP, based on the number of packets per session for each transaction. I also give my conclusions from a case study I conducted into the possible impact of T/TCP on the World Wide Web.
The TCP/IP reference model is a specification for a networking stack on a computer. It exists to provide a common ground for network developers. This allows easier interconnection of the different vendor-supplied networks.
The most popular implementations of the transport layer in the reference model are Transmission Control Protocol (TCP), a connection-oriented protocol, and User Datagram Protocol (UDP), a connectionless protocol.
Both of these protocols have advantages and disadvantages. The two main aspects of the protocols make them useful in different areas. Being a connectionless protocol, UDP is unreliable but fast and useful for applications, such as DNS (Domain Name System), where speed is preferred over reliability. TCP, on the other hand is a reliable, connection-oriented protocol. As a result, TCP is a slower protocol than UDP.
With the explosion of the Internet in recent years, the need for a new specification arose. The current transport protocols were either too verbose or not reliable enough. A protocol was needed that was faster than TCP but more reliable than UDP. This new protocol could reduce bandwidth and increase the speed of transmission of data, which is very much needed at the moment.
TCP for Transactions (T/TCP) is a possible successor to both TCP and UDP. It is a transaction-oriented protocol based on a minimum transfer of segments, so it does not have the speed problems associated with TCP. By building on TCP, it does not have the unreliability problems associated with UDP. With this in mind, RFC1379 was published in November 1992. It discussed the concepts involved in extending the TCP protocol to allow for a transaction-oriented service. Some of the main points the RFC discussed were bypassing the three-way handshake and shortening the TIME-WAIT state from 240 seconds to 12 seconds. Eighteen months later, RFC1644 was published, with the specification for Transaction TCP. T/TCP cuts out much unnecessary handshaking and error detection done by the current TCP protocol, and as a result, increases the speed of connection and reduces the necessary bandwidth.
T/TCP can be considered a superset of the TCP protocol. The reason for this is that T/TCP is designed to work with current TCP machines seamlessly. What follows is a brief description of T/TCP and how it differs from the current TCP standard in operation.
The term “transaction” refers to the request sent by a client to a server, along with the server's reply. RFC955 lists some of the common characteristics of transaction processing applications:
Asymmetrical Model: the two end points take different roles; this is a typical client-server role where the client requests the data and the server responds.
Short Duration: normally, a transaction runs for a short time span.
Few Data Packets: each transaction is a request for a small piece of information, rather than a large transfer of information both ways.
The growth of the Internet has put a strain on the bandwidth and speed of networks. There are now more users than ever, and a more efficient form of data transfer is needed.
The absolute minimum number of packets required in a transaction is two: one request followed by one response. UDP is the one protocol in the TCP/IP protocol stack that allows this, but the problem is the unreliability of the transmission.
T/TCP has the reliability of TCP and comes very close to realizing the 2-packet exchange (three in fact). T/TCP uses the TCP state model for its timing and retransmission of data, but introduces a new mechanism to allow the reduction in packets.
Even though three packets are sent using T/TCP, the data is carried on the first two, thus allowing the applications to see the data with the same speed as UDP. The third packet is the acknowledgment to the server by the client that it has received the data, which is how the TCP reliability is incorporated.
Consider a DNS system, one where a client sends a request to a server and expects a small amount of data in return. A diagram of the transaction can be seen in Figure 1. This diagram is very similar to a UDP request with a saving of 66% in packets transferred compared to TCP. Obviously, in cases where a large amount of data is being transferred, there will be more packets transmitted and thus a decrease in the percentage saved.
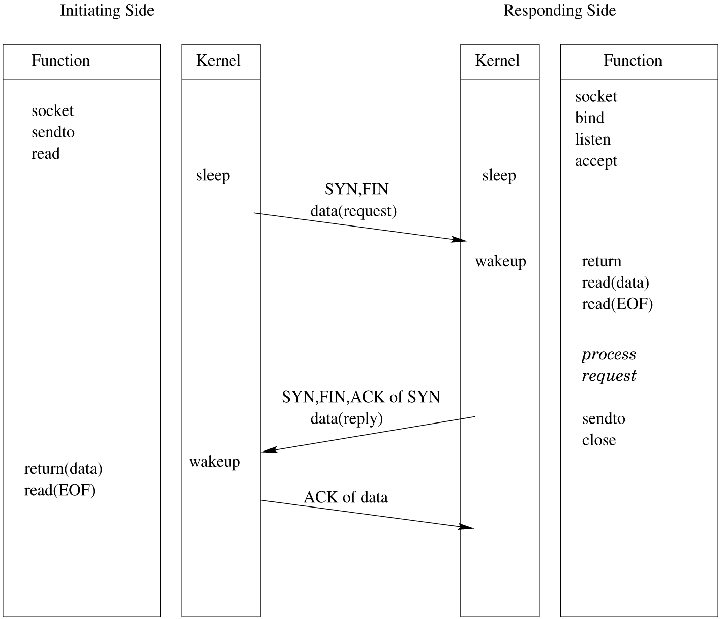
Figure 1. Time line of T/TCP Client-Server Transaction
Timing experiments have shown that there is a slightly longer time required for T/TCP than for UDP, but this is a result of the speed of the computer and not the network. As computers get more powerful, the performance of T/TCP will approach that of UDP.
TCP Accelerated Open (TAO) is a mechanism introduced by T/TCP designed to cut down on the number of packets needed to establish a connection with a host.
There are a number of new options that T/TCP introduces. These options allow the establishment of a connection with a host using the TAO. T/TCP uses a 32-bit incarnation number, called a connection count (CC). This option is carried in the options part of a T/TCP segment (see Figure 2). A distinct CC value is assigned to each direction of an open connection. Incremental CC values are assigned to each connection that a host establishes, either actively or passively.
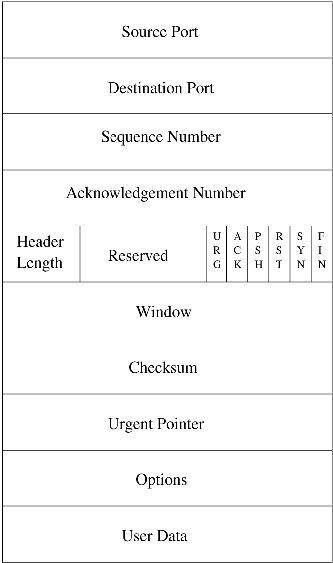
Figure 2. TCP Header
The three-way handshake is bypassed using the CC value. Each server host caches the last valid CC value it received from each different client host. This CC value is sent with the initial SYN segment to the server. If the initial CC value for a particular client host is larger than the corresponding cached value, the property of the CC options (the increasing numbers) ensures that the SYN segment is new and can be accepted immediately.
The TAO test fails if the CC option arriving in the SYN segment is smaller than the last CC value received that was cached by the host, or if a CCnew option is sent. The server then initiates a three-way handshake in the normal TCP/IP fashion.
T/TCP can be beneficial to some of the applications that currently use TCP or UDP. At the moment, many applications are transaction-based rather than connection-based, but still have to rely on TCP, along with the overhead. UDP is the other alternative, but not having time-outs and retransmissions built into the protocol means the application programmers have to supply the time-outs and reliability checking themselves. Since T/TCP is transaction-based, there is no set-up and shutdown time, so the data can be passed to the process with minimal delay.
Hyper Text Transfer Protocol is the method used by the World Wide Web to access web pages. T/TCP can be used to reduce the number of packets required.
With TCP, the transaction is accomplished by connecting to the server (three-way handshake), requesting the file (GET file), then closing the connection (sending a FIN segment). T/TCP would operate by connecting to the server, requesting the document and closing the connection, all in one segment (TAO). It is obvious that bandwidth is saved by this method.
Remote procedure calls (RPCs) also adhere to the transaction style paradigm. A client sends a request to a server for the server to run a function. The results of the function are then returned in the reply to the client. There is only a tiny amount of data transferred with RPCs.
The Domain Name System is used to resolve host names into the IP addresses that locate the host.
To resolve a domain name, the client sends a request with the IP address or a host name to the server. The server responds with the host name or IP address where appropriate. This protocol uses UDP.
As a result of using UDP, the process is fast, but not reliable. Furthermore, if the response by the server exceeds 512 bytes of data, it sends the data back to the client with the first 512 bytes and a truncated flag. The client has to resubmit the request using TCP.
The reason for this is there is no guarantee that the receiving host will be able to reassemble an IP datagram exceeding 576 bytes. For safety, many protocols limit the user data to 512 bytes.
T/TCP is the perfect candidate for the DNS protocol. It can communicate at speeds approaching that of UDP, and it has the reliability of TCP.
In order to investigate the benefits of this implementation of T/TCP, it is important to test its operation, and also to compare its operation to the original TCP/IP operation. I performed these tests using the Linux 2.0.32 kernel with T/TCP modifications and FreeBSD version 2.2.5, which already implements T/TCP.
To investigate the performance of T/TCP in comparison to the original TCP/IP, I compiled a number of executables that returned different-sized data to the client. The two hosts involved were elendil.ul.ie, running Linux, and devilwood.ece.ul.ie, running FreeBSD 2.2.5. The tests were performed for ten different response sizes in order to vary the number of segments required to return the full response. Each request was sent 50 times and the results were averaged. The maximum segment size in each case is 1460 bytes.
The metric used for performance evaluation was the average number of segments per transaction. I used Tcpdump to examine the packets exchanged. Note that Tcpdump is not entirely accurate, since during fast packet exchanges, it tends to drop some packets to keep up. This accounts for some discrepancies in the results.
Figure 3 shows the results from testing for the number of segments for T/TCP versus the number of segments for normal TCP/IP. It is immediately obvious that there is a savings of an average of five packets. These five packets are accounted for in the three-way handshake, and the packets sent to close a connection. Lost packets and retransmissions cause discrepancies in the path of the graph.
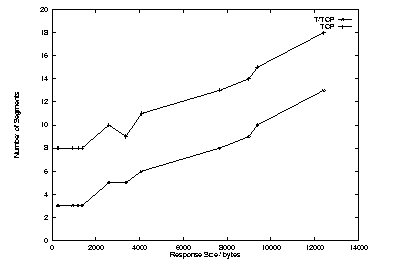
Figure 3. Number of Segments versus Size of Data Transfer
One interesting point about the average number of segments when using a TCP client and a T/TCP server is that there is still a saving of one segment. A normal TCP transaction requires nine segments, but because the server was using T/TCP, the FIN segment was piggybacked on the final data segment, reducing the number of segments by one. This demonstrates a reduction in segments, even if only one side is T/TCP-aware.
Figure 4 shows the percentage savings for the different packet sizes. The number of packets saved remains fairly constant, but because of the increase in the number of packets being exchanged, there is a decrease in the overall savings. This indicates that T/TCP is more beneficial to small data exchanges.
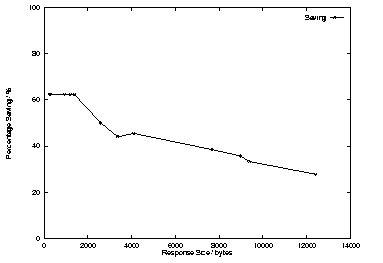
Figure 4. Percentage Savings per Size of Data Transfer
The main memory drain in the implementation is in the routing table. In Linux, for every computer with which the host comes into contact, an entry for the foreign host is made in the routing table. This applies to both a direct connection and to a multi-hop route. This routing table is accessed through the rtable structure. The implementation of T/TCP adds two new fields to this structure, CCrecv and CCsent.
The entire size of this structure is 56 bytes, which isn't a major memory hog on a small stand-alone host. On a busy server, though, where the host communicates with maybe thousands of other hosts an hour, it can be a major strain on memory. Linux has a mechanism where a route no longer in use can be removed from memory. A check is run periodically to clean out unused routes and those that have been idle for a time.
The problem here is the routing table holds the TAO cache. So anytime a route which contains the last CC value from a host is deleted, the local host has to re-initiate the three-way handshake with a CCnew segment.
The benefits of leaving the routing entries up permanently are clear. The most likely use would be in a situation where a host talks to only a certain set of foreign hosts and denies access to unknown hosts. In this case, it is advantageous to keep a permanent record in memory so the three-way handshake can be bypassed more often.
The original protocol specification (RFC1644) labeled T/TCP as an experimental protocol. Since the RFC was published, there hasn't been an update to the protocol to fix some of the problems. From the previous sections, the benefits over the original TCP protocol are obvious, but is it a case of the disadvantages outweighing the advantages?
One of the more serious problems with T/TCP is that it opens up the host to certain Denial of Service attacks. SYN flooding (see www.sun.ch/SunService/technology/bulletin/bulletin963.html for more information) is the term given to a form of denial-of-service attack where the attacker continually sends SYN packets to a host. The host creates a sock structure for each SYN, thus reducing the number of sock structures that can be made available to legitimate users. This may eventually result in the host crashing when enough memory has been used. SYN cookies were implemented in the Linux kernel to combat this attack. SYN cookies cause problems with T/TCP, as there are no TCP options sent in the cookie, and any data arriving in the initial SYN can't be used immediately. The CC option in T/TCP does provide some protection on its own, but it is not secure enough.
Another serious problem discovered during research was that attackers can bypass rlogin authentication. An attacker creates a packet with a false IP address in it, one that is known to the destination host. When the packet is sent, the CC options allow the packet to be accepted immediately and the data passed on. The destination host then sends a SYNACK to the original IP address. When this SYNACK arrives, the original host sends a reset, as it is not in a SYN-SENT state. This happens too late, as the command will already have been executed on the destination host. Any protocol that uses an IP address as authentication is open to this sort of attack. (See geek-girl.com/bugtraq/1998_2/0020.html.)
It should be noted, however, that the use of T/TCP in conjunction with protocols such as HTTP have fewer security problems, due to the inability to run any server commands with HTTP.
RFC1644 also has a duplicate transaction problem. This can be serious for applications that are non-idempotent (repeat transactions are very undesirable). This error can occur in T/TCP if a request is sent to a server and the server processes the transaction, but before it sends back an acknowledgment, the process crashes. The client side times out and retransmits the request; if the server process recovers in time, it can repeat the same transaction. This problem occurs because the data in a SYN can be immediately passed to the process, rather than in TCP where the three-way handshake has to be completed before data can be used. The use of two-phase commits and transaction logging can eliminate this problem.
With the World Wide Web being the prime example of client-server transaction processing today, this section will focus on the benefits of T/TCP to the performance of the Web.
Currently, the HTTP protocol sits in the application layer of the TCP/IP reference model. It uses the TCP protocol to carry out all its operations, UDP being too unreliable. Much latency is involved in the transfer of information, i.e., the three-way handshake and explicit shutdown exchanges.
In a survey of 2.6 million web documents searched by the Inktomi web crawler search engine (see http://inktomi.berkeley.edu/), it was found that the mean document size on the Web was 4.4KB, the median size was 2.0KB and the maximum size encountered was 1.6MB.
Referring to Figure 4, it can be seen that the lower the segment size, the better the performance of T/TCP over normal TCP/IP. With a mean document size of 4.4KB, this results in an average savings of just over 55% in the number of packets. When taking the median size into account, there is a savings of approximately 60%.
At the moment, all web pages are transferred in plaintext form, requiring little work from either the server side or the client side to display the pages.
In their paper “Network Performance Effects of HTTP/1.1, CSSI and PNG” (see Resources), the authors investigated the effect of introducing compression to the HTTP protocol. They found that compression resulted in a 64% savings in the speed of downloading, with a 68% decrease in the number of packets required. Over normal TCP/IP, this brings the packet exchanges and size of data down to the level where T/TCP becomes beneficial. Thus, a strategy involving both compression and T/TCP can result in enormous savings in time and bandwidth.
In this situation, a delta refers to the difference between two files. On UNIX systems, the diff command can be used to generate the delta between two files. Using the changed file and the delta, the original file can be regenerated again and vice versa.
J. C. Mogul, et al. (see Resources) investigated the effect that delta encoding has on the Web. In their testing, they not only used delta encoding, they also compressed the delta generated to further reduce the amount of information transferred. They discovered that by using the vdelta delta generator and compression, they could achieve up to 83% savings in the transmission of data.
If this method was used with T/TCP, there could be as much as a further 66% savings in packets transferred. This is a total of 94% reduction in packet transfer.
It should be noted, however, that this is a best-case scenario. In this situation, the document will already have been cached on both the server and the client side, and the client and server will previously have completed the three-way handshake in order to facilitate the TAO tests.
Programming for T/TCP is slightly different using socket programming. As an example, the chain of system calls to implement a TCP client would be as follows:
socket: create a socket.
connect: connect to the remote host.
write: write data to the remote host.
shutdown: close one side of the connection.
Whereas with T/TCP, the chain of commands would be:
socket: create a socket.
sendto: connect, send data and close connection. The sendto function must be able to use a new flag MSG_EOF to indicate to the kernel that it has no more data to send on this connection.
Analysis of T/TCP shows that it benefits small, transaction-oriented transfers more than large-scale information transfers. Aspects of transactions can be seen in such cases as the World Wide Web, Remote Procedure Calls and DNS. These applications can benefit from the use of T/TCP in efficiency and speed. T/TCP reduces on average both the numbers of segments involved in a transaction and the time taken to complete the transaction.
As T/TCP is still an experimental protocol, there are problems that need to be addressed. Security problems encountered include the vulnerability to SYN flood attacks and rlogin authentication bypassing. Operational problems include the possibility of duplicate transactions occurring. Problems that occur less frequently would be the wrapping of the CC values on high-speed connections, thus opening up a destination host to accepting segments on the wrong connection.
Many people recognize the need for a protocol that favors transaction-style processing and are willing to accept T/TCP as the answer. Security considerations lead to the conclusion that T/TCP would be more useful in a controlled environment, one where there is little danger from a would-be attacker who can exploit the weaknesses of the standard. Examples of enclosed environments would be company intranets and networks protected by firewalls. With many companies seeing the Web as the future of doing business, internal and external, a system employing T/TCP and some of the improvements to HTTP, such as compression and delta encoding, would result in a dramatic improvement in speed within a company intranet.
Where programmers are willing to accept T/TCP as a solution to their applications, only minor modifications are needed for the application to become T/TCP-aware. For client-side programming, it involves the elimination of the connect and shutdown function calls, which can be replaced by adding the MSG_EOF flag to the sendto command. Server-side modifications involve simply adding the MSG_EOF flag to the send function.
Research into T/TCP suggests it is a protocol that is nearly, but not quite, ready to take over transaction processing for general usage. For T/TCP alone, more work needs to be done to develop it further and solve the security and operational problems. Security problems can be solved using other authentication protocols such as Kerberos and the authentication facilities of IPv6. Operational problems can be dealt with by building greater transaction reliability into the applications that will use T/TCP, such as two-phase commits and transaction logs.
Applications can be easily modified to use T/TCP when available. Any applications which involve an open-close connection can use T/TCP efficiently, and the more prominent examples would be web browsers, web servers and DNS client-server applications. To a smaller extent, applications such as time, finger and whois can benefit from T/TCP as well. Many networking utilities are available that can take advantage of the efficiency of the protocol. All that is needed is the incentive to do it.
Perhaps a more immediate task, though, is to port the T/TCP code to the new Linux kernel series, 2.3.x.

Ivan Griffin
John Nelson

