
Sculptor: A Real Time Phase Vocoder
Computer music in some respects places extreme demands on operating systems, especially now that inexpensive desktop platforms have enough raw processing power to perform relatively complex signal processing tasks in real time. Shared memory and System V IPC are powerful allies in realising audio manipulation tools under real-time control. Sculptor is a set of tools for Linux which uses these techniques to produce impressive throughput, even on modest platforms. It was initially conceived as a research tool, but may end up being a musical instrument.
This is the story of how a program, which ran in batch mode on PDP-11s taking many hours to produce a few seconds of audio output, can now be run in real time on an inexpensive desktop Linux machine. Changing a program from batch mode to real time presents an enormous challenge to the programmer: the user interface becomes an issue, imposing a completely new structure on the software, as user-interface-originated events need to be processed asynchronously with the real-time audio synthesis.
Timbre means sound colour, a perceptual correlate of harmonic content, in the same way that pitch is related perceptually to frequency. A violin and a flute can be played at the same pitch and loudness, but always have different timbre. One process which computer-musicians like to use is morphing, where sound can be altered smoothly from an initial timbre to a finishing one. Many readers will be familiar with the process of video morphing and will appreciate how it is an entirely different process from simply cross-fading. One method of achieving the audio equivalent is to manipulate the audio signal not as a series of time samples, but as a series of evolving spectra. By changing the attributes of the sound's spectrum as it evolves, this and many other interesting effects can be made.
In this article, a method for manipulating spectra in real time and providing continuous audio output will be examined. An example xview application has been written, so anybody with those libraries and an appropriate sound card can experiment for themselves.
The phase vocoder is one of the more powerful methods of manipulating sounds in the frequency domain. It is not a new technology; MIT's CSound application (see Resources), which was ported to the C language and UNIX from the original MUSIC11 program written in assembler for the PDP-11 minicomputer by Barry Vercoe, contains phase vocoder software. However, the algorithm was of such complexity and computers at the time were so short of processing power it would often require many hours of processing to realise each second of audio output. Only recently has sufficient processing power reached the desktop to make real-time phase vocoding a viable proposition.
A vocoder is an electronic signal processor consisting of a bank of filters spaced across the frequency band of interest. Originally, it was hoped such a device would be able to reduce the bandwidth necessary for the transmission of voice telephony, but it rapidly found other applications in popular music. A voice signal could be analysed by the filter bank in real time, and the output applied to a voltage-controlled filter bank or an oscillator bank to produce a distorted reproduction of the original. The effect can be heard in some Electric Light Orchestra tracks, and in the theme music to the film Educating Rita.
After Michael Portnoff (see Resources) demonstrated an efficient method of building the required filter banks digitally, the door was open for a computer-based implementation of a digital phase vocoder, bringing with it a vast number of possibilities for the analysis, manipulation and synthesis of audio. Wishing to use this technology to improve my understanding of the relationship between a sound's timbre and its spectrum, I set about writing Sculptor, a real-time and interactive phase vocoder for Linux.
The Phase Vocoder in Sculptor comes in two parts: a batch-mode analyser called analyse, and a real-time synthesiser called, perhaps more imaginatively, prism. analyse reads an input file in Sun/NeXT audio format. The sample rate we use most often is 22,050 samples per second, as my P120 machine at home can comfortably keep up with this resynthesis rate using floating-point arithmetic with enough power left over to see to the work of running the X Window System interface. Samples can be acquired in the usual way using a command-line recording tool, but finding that rather tedious, we wrote Studio (see Resources) in Tcl/Tk to make the process of acquiring short samples more accessible.
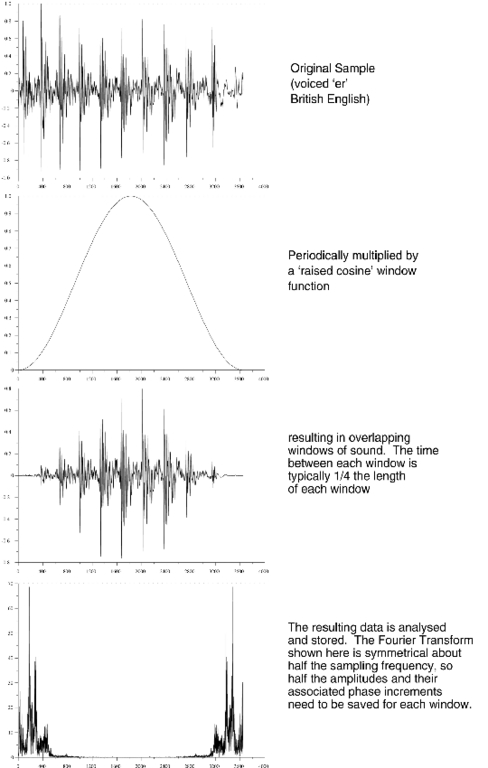
Figure 1. Analysing the Audio Samples
analyse reads the sample file and breaks it up into overlapping windows of about 10ms in length. This window length was chosen because evidence suggests the ear is insensitive to spectral changes on a shorter time scale. Each window is Fourier-transformed, producing an array of spectral samples (see Figure 1), but instead of simply storing the amplitude and phase of each Fourier result (bin), the amplitude and phase change per window are recorded.
To understand why the phase change per window is important rather than the absolute phase, let's consider a simple example. Suppose we are using a sample rate of 8192Hz and have a 128-point FFT. Each window will last approximately 15ms, and the spacing between Fourier bins will be 64Hz. Now present this program with a sine wave at 1KHz. The Fourier transform cannot represent this signal exactly; recall that it is behaving like a bank of filters 64Hz apart, so the nearest filter frequencies will be bins 15 and 16 at 960 and 1024Hz, respectively.
When this same signal is analysed a quarter of a window later, it will still be represented as a 1024Hz sine wave. Since its frequency is actually lower, it will appear to have lagged in phase. By storing the phase change per window, sufficient information is retained to at least approximate the original 1000Hz sinusoid by overlapping the inverse Fourier transformation results and adding them together at resynthesis time.
There is a big difference between a sound-synthesis program which runs in real time and one which simply produces output samples at a greater rate than the sound device chooses to swallow them. For a program to be a real-time synthesiser, it must respond apparently instantaneously to a change in an input parameter. For example, the CSound application mentioned previously is not real time, because it reads the specification of a score and orchestra at initialization, then produces audio output. It isn't possible to influence the sound the program produces as it produces it. (Actually, some real-time extensions have become available, but I am choosing to ignore them for the sake of this example.) Running CSound on a powerful workstation usually causes it to produce samples faster than actual speed, but this does not qualify it as real time.
To design a real-time program, one of the most important design considerations is the user interface, which in turn is strongly influenced by the desired effects. The next stage in the design process is considering the kind of manipulations required for such an application.
When a synthesis program becomes real-time, it becomes a musical instrument, and when a computer program becomes a musical instrument, the operator becomes a performer. The ergonomics of a musical instrument are highly complex, but from the context of previous uses of this algorithm in computer music, clearly some core areas must be covered: pitch transposition, a change in a sample's pitch with no change in its duration; rate of playback, a stretching or compression of a sample in time with no change in its pitch; and timbral morphing, where one sound changes smoothly into another as pictures do in video morphing.
Sculptor permits independent control over pitch and rate of playback in real time even on very modest computing platforms, and acts as a test bed for more advanced algorithms on faster platforms. It was initially developed on a 386DX40 without a floating-point coprocessor and could make a fair attempt at real-time synthesis at 8000 samples per second (voice telephone quality).
Having decided there are essentially two parts of the application, a real-time synthesiser and a GUI, it seems to make sense to divide the processing between the two. One process will be responsible for the audio synthesis, the other for mouse- and window-related processing.
Linux, like most UNIX systems, provides two different methods for inter-process communication (IPC). The first is channel-based: sockets, pipes and so on. This kind of IPC has many advantages; one can easily map the processes onto different machines connected by a network, and synchronization is easily arranged, as a channel can be set up to block in an efficient, non-polling manner until data arrives.
The prism application has two processes which basically operate asynchronously. Essentially, the resynthesiser has to keep running and producing audio samples regardless of what the user is doing with the mouse. For this reason, the second method of IPC, shared-memory or System-V IPC, has been used. System-V IPC also provides methods for process synchronisation: the semaphore. One can raise or wait on a semaphore. Think of it as a special kind of variable which behaves in the following manner. If one or more processes are waiting on a semaphore, raising it enables exactly one of those processes to proceed. If no processes are waiting, then the value of the variable is incremented. Waiting on a non-zero semaphore decrements its value but allows the process to continue immediately. Waiting on a zero-value semaphore adds the current process to a (possibly empty) list of waiting processes, pending the semaphore being raised by another agent.
Semaphores are used in shared-memory situations to implement mutual exclusion locks and prevent update anomalies where several processes simultaneously attempt to modify a shared data structure. However, prism uses only two processes accessing the shared-memory block: the GUI is a producer because it is supplying control parameters, and the synthesiser is a consumer because it uses them to generate audio samples. Since there is only one producer and one consumer, there is no need to use semaphores as access arbiters. In fact, advantage is taken of the shared-memory IPC to allow the producer to provide a set of “magic” parameters which change according to the user's gestures.
Upon startup, prism has to allocate and set up a shared-memory block, then fork off the process to generate the audio output. The routines it uses are documented in the shmop manual pages. Enough memory is allocated to hold a control structure and all of the spectral data produced by the analysis program (see Listing 1).
prism calls shmget to allocate the required amount of memory; it returns a handle to the memory block for subsequent use. The other parameters specify the access permissions in the normal chmod format, and the block will be created if it does not exist yet. The process then forks with the child being responsible for synthesis, and the parent for control functions.
After the fork call, both the parent and the child processes must attach the shared-memory block and cause it to appear in their respective memory spaces. The appropriate system call is shmat. The parameters indicate the handle of the shared memory block and the desired target address. Passing NULL as the latter tells the system to make the choice of address. In Linux running on an i386 architecture, the blocks are allocated downwards in memory starting at an address of 1.5GB. This call can be made once before the fork system call, as the shared block will then appear in both the child's and parent's memory space.
One trap waits to catch the unwary programmer using shared memory blocks: they are persistent. If your application crashes without properly tidying up shared-memory blocks, memory will leak like a sieve. The user can check for any undeleted memory blocks using the ipcs command and remove them with ipcrm. prism does its best to cope with any unexpected events by catching the SEGV signal and shutting down any shared-memory activity before exiting. However, the best safeguard against memory leaks is to mark the shared-memory block for deletion as soon as it is created. Counterintuitively, the way to do this is to mark the block as transient using the shmctl call, and then detach the process from the shared-memory block. The shared-memory block will persist until all the processes using it detach using the shmdt call, so the block will disappear automatically when the parent and child processes exit.
Writing Sculptor was supposed to be an exercise in efficient signal processing rather than sophisticated GUI design. The GUI library eventually selected was xview, which is a rather aged library, although dynamic and static versions are still available for Red Hat's 5.0 release based on glibc2, so it is not quite dead yet. The reason for this choice was primarily because I was familiar with it. The principal requirements of the application, a few simple menus, sliders and the detection of mouse events over a performance canvas are satisfied by practically any widget set from the oldest Athena to the latest GTK+, so the wide availability of the library in an open form is of more concern than its technical sophistication. Linux Journal has already published an article (see Resources) demonstrating the use of xview and the ease with which simple applications can be constructed using variable-argument-list calls.
When the prism application is invoked by the name xprism, the xview GUI is enabled. Most of the data flow in xprism is mono-directional: the GUI process produces control data, and the synthesiser consumes it producing audio samples. However, when the specification for xprism was conceived, it became evident that asynchronous flow in the opposite direction was needed.
When xprism runs, the following sequence of events takes place:
The analysis file is opened and the size of memory required to contain the spectra is calculated. An additional allowance is made for spectral workspace. As in interactive mode, a mouse action might be responsible for setting the synthesiser parameters rather than relying on simply incrementing through the spectrograph automatically.
The shared control block (see Listing 2) is set up with appropriate initial values.
The whole spectral file is read into the shared-memory block.
The process forks a child responsible for audio resynthesis.
The parent xview widget hierarchy is intialised and the spectrograph drawn.
The parent informs the child it may generate audio samples by setting the xv_ready field in the shared control block.
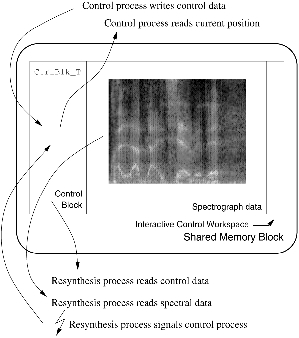
The parent and the child run concurrently, using the shared memory area for data transfer (see Figure 2).
Figure 2. Data Flow in the Shared Memory Block.
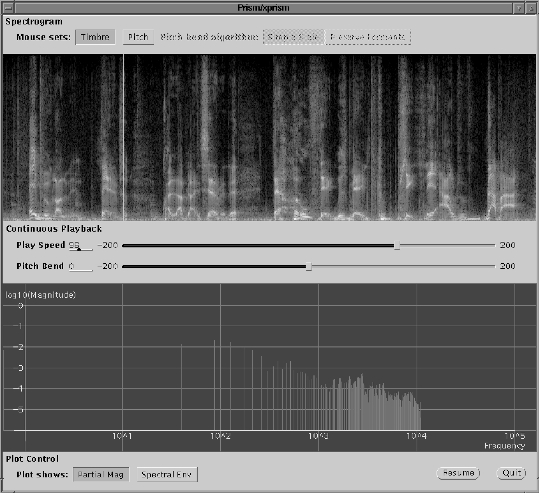
This process is fine for simple gestural control, but as it stands, there is no feedback from the synthesiser process about whence in the spectrogram the resynthesiser is taking its data. Refer to the screenshot of the application running in Figure 3, and it is obvious that two fundamentally different ways of getting sound out of the program are present.
The user can select a playback speed from the speed slider, in which case the rate of advance through the spectrogram is under control of the resynthesis process. It is necessary to update the green line when the resynthesis source is moved automatically by the resynthesiser, and of course this happens asynchronously with the GUI events. The solution is to arrange for the resynthesiser to signal the parent when an update is required.
The user can click or drag on the spectrogram, in which case the spectrum to be resynthesised is under control of the parent controlling process. There is no problem in positioning the green line on the spectrogram canvas: it is simply dictated by the position parameter from the serviced mouse-motion event.
Sending a signal from the child process is easily achieved, but there may be unfortunate consequences. The application is continually sending commands to the X-server, and in principle, a signal might occur during the process of client-server communication. This is dangerous only in that the signal initiates X-server commands (in order to draw the green line), so some method of making X protocol requests atomic has to be employed.
Fortunately, the necessary methods are provided by the xview package. An xview client is not supposed to perform certain operations. One of these is servicing interrupts received directly by the signal method, and another is using sleep to suspend itself. Both potentially interfere with the proper operation of client-server communication. If the client wants to use interrupts, it must register itself as a signal acceptor as follows:
notify_set_signal_func(frame, update_frame_posn,
SIGUSR1, NOTIFY_SYNC);
This call appears at the end of the initialiser for the xview data structures and associates the service routine for the signal SIGUSR1 with the servicing function update_frame_posn. The frame argument is the parent frame of the application, and NOTIFY_SYNC indicates that servicing of the interrupt should be delayed until pending X-protocol exchanges are complete.
Sculptor is a package that can manipulate sound samples in potentially exciting ways. It has a front end which permits the user to perform these manipulations in real time. System-V IPC has been used to split the process into two halves which can be efficiently load-balanced on a multi-processor machine. The source code is freely available (see Resources).
Sculptor is not intended as a guide to good programming practice; in fact, some of the code is just plain ugly. Early in its development, the whole application was required to work in real time on a 386 machine without a co-processor, so some sacrifice of clarity for speed had to be made. Nonetheless, it is hoped the code might stimulate other projects in real-time audio manipulation, now that one based on a processor-intensive algorithm has been demonstrated to operate fully interactively in real time. The application is also being used to support research into computer music at the University of Leeds, and so by definition will never be “finished”.



{kind=link}
{kind=link}
{kind=link}