
Parallel Algorithms for Calculating Underground Water Quality
In scientific calculations, we often process a large amount of data, requiring much computer time. Thus, the studying of parallel and distributed algorithms is a serious requirement in the developmental computer age. In this paper, I discuss the implementation of algorithms solving engineering mechanics problems in the form of parabolic differential equations, in particular the problem for transfer and diffusion of pollution in underground water. The problem's algorithms are implemented in a heterogeneous network of computers running Linux. Thus, we will obtain a distributed network including many processors in the form of a multi-computer. This multi-computer has formed a Parallel Virtual Machine (PVM). Developing applications for the PVM system follows the traditional paradigm for programming distributed-memory multiprocessors such as the nCUBE or the Intel family of multiprocessors. This paradigm can be subdivided into two categories:
The master-slave (host-node) model in which a separate control program termed the master is responsible for process spawning, initialization, collection and display of results, and timing of functions. The slave programs perform the actual computations; they are either allocated their workloads by the master (statically or dynamically) or they perform the allocations themselves.
The node-only model where multiple instances of a single program execute, with one process (typically the one initiated manually) taking over the non-computational responsibilities in addition to contributing to the computation.
In this paper, we apply the parallel algorithm to calculate the diffusion S(t,x,y) of polluted matter resource of underground water by using the following equation. This is the evolution problem in the form of a quasilinear equation:

Figure 1
where the variables are defined as follows:
- s: spongy coefficient of environment
- K : coefficient of penetration
- L: dispersion
- z = z(t,x,y): free surface of underground water
- zd = zd(x,y): director surface
- Q = Q(t,x,y): resource of polluted matter
We discrete the problem by using the difference method. Therefore, we will obtain two tridiagonal systems of linear equations. Using these equations, we can calculate to find the concertrantion of pollution Sn+0.25, Sn+0.50 at the point in time equal to (n+0.25)Dt and (n+0.50)Dt. The flow-chart of the parallel algorithm is shown in Figure 1.
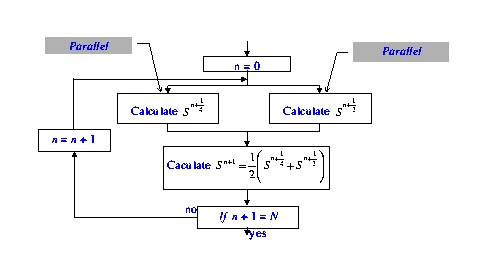
Figure 1. Flow-chart
The values Sn+0.25 and Sn+0.50 are calculated concurrently on two processors of our virtual machine that form a shared or local-memory multiprocessor.
PVM is a portable message-passing programming system designed to link separate host machines to form a “virtual machine” that is a single, manageable computing resource. The virtual machine can be composed of hosts of varying type in physically remote locations. PVM applications can be composed of any number of separate processes, or components, written in a mixture of C/C++ and FORTRAN. The system is portable to a wide variety of architectures, including workstations, multiprocessors, supercomputers and PCs. The most common PVM platform is UNIX, and it currently runs on more than 30 different platforms.
In the master-slave model, the master program spawns and directs a number of slave programs which perform computations. PVM is not restricted to this model. For example, any PVM task can initiate processes on the machines; however, a master-slave model is a useful programming paradigm and simple to illustrate. The master calls pvm_mytid, which, as the first PVM call, enrolls this task in the PVM system. It then calls pvm_spawn to execute a given number of slave programs on other machines in PVM. The master program contains an example of broadcasting messages in PVM. The master broadcasts to the slave the number of slaves started and a list of all the slave tids (task IDs). Each slave program calls pvm-tid to determine its task ID in the virtual machine, then uses the data broadcast from the master to create a unique ordering from 0 to nproc minus 1 (nproc-1), where nproc is the number of slave processes. Subsequently, pvm_send and pvm_recv are used to pass messages between processes. When finished, all PVM programs call pvm_exit to allow PVM to disconnect any sockets to the process, flush I/O buffers and keep track of which processes are currently running.
The SPMD (single-program, multiple-data) model contains only a single program, and no master program directs the computation. Such programs are sometimes called hostless programs. However, all processes still need to get started initially. The user starts the first copy of the program; by checking pvm_parent, this first copy can determine it was not spawned by PVM and can thereby know itself to be the first copy. It then spawns multiple copies of itself and passes them the array of tids. At this point, each copy is equal and can work on its partition of the data in collaboration with the other processes. Using pvm_parent precludes starting the SPMD program from the PVM console because pvm_parent will return the tid of the console. This type of SPMD program must be started from a UNIX prompt.
For our program, we used a master-slave programming model. The master program spawns a copy of the slave program to the other processor to calculate Sn+0.25, and calculates Sn+0.50 itself. When both processors have completed the calculation, the master program will calculate the sum Sn+1 = 0.5(Sn+0.25 + Sn+0.50). The program will finish when the final step time is completed. The progress of parallel computing in calculating Sn+0.25 and Sn+0.25 is shown in Figure 2.
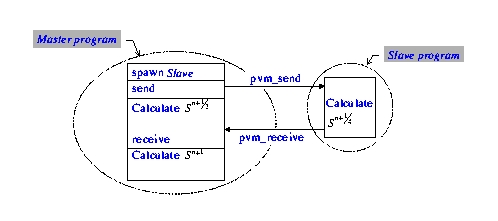
Figure 2. Progress of Parallel Computing
Linear system equations are also in the master and slave programs, so we also use the master-slave programming model to solve the tridiagonal systems by Linear Recurrence of order two. Horner's algorithm can be implemented to evaluate a polynomial of degree n at a single point to run in O(log2n). If we use sequential algorithms of the LDU factorization of a tridiagonal matrix, we will run it in O(n).
We designed and built the X Window System program Xndd under Linux. This program can be used for simulating the surface of underground water and the transfer and diffusion of pollution. The interface of the program and some calculation results are shown in Figure 3.


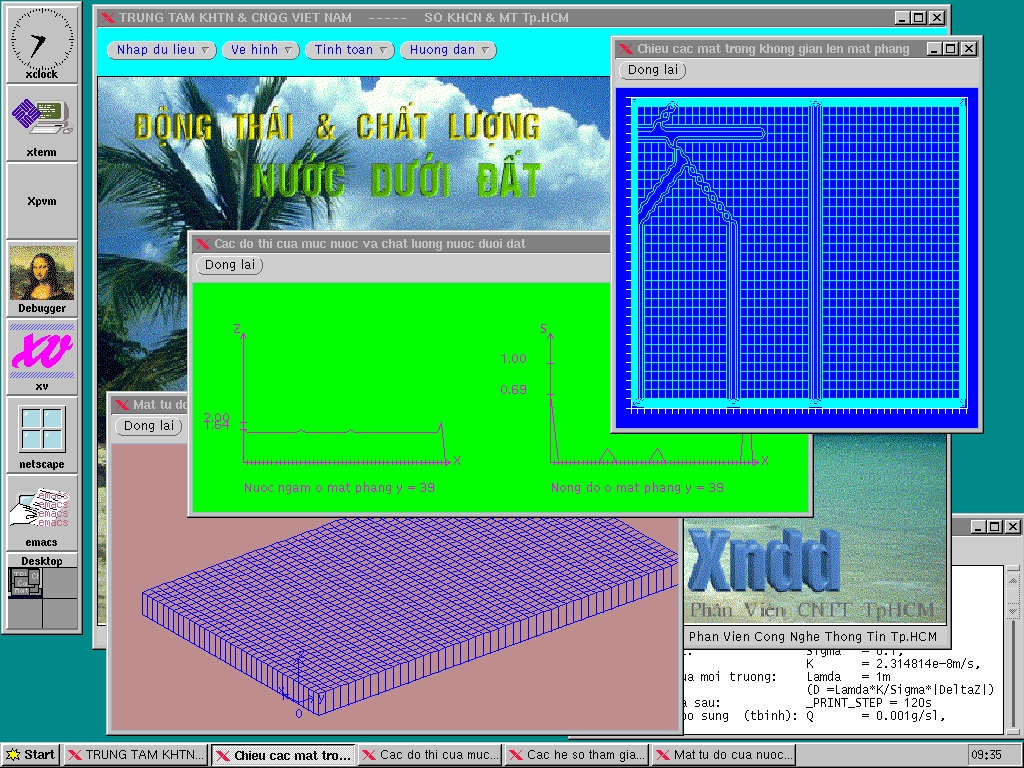{kind=link}