
A Look at the Buffer-Overflow Hack
The best system administrator is not always enough to take care of site security. Sometimes a nice program such as mount can be exploited by a user to gain a higher system permission or remote access to an unauthorized location on the World Wide Web.
This article explains the logic behind a popular hack to exploit a program's code so it executes different code then was intended. This hack is known as the buffer-overflow hack and can be used to exploit a program with suid set to gain better permissions on a Linux machine—sometimes even root or remote access. (The examples are taken from “aleph-one” with his permission and have been somewhat modified by me.)
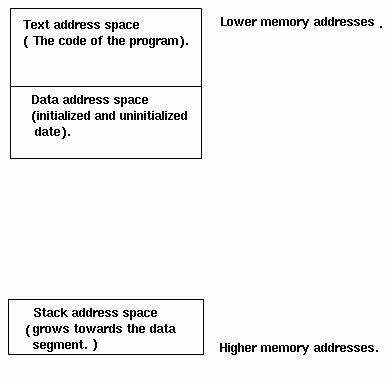
Figure 1. Virtual Memory Layout
First, let's have a look at Figure 1 and see how a process organizes its virtual memory. The TEXT area is where the actual code of the program resides. The DATA area is where the initialized and uninitialized data of the program resides.
The STACK area is a dynamic area which becomes bigger as data is pushed into it and smaller as data is popped from it. It is called a stack because it works in the LIFO way (last in, first out). The stack is used to hold temporary data for the process and helps the processor in its implementation of high-level functional programming. To understand exactly how the processor makes use of the stack, look at the following example:
void func(int a, int b)
{
/* This function does nothing */
}
main()
{
int num1;
int num2;
func(num1,num2);
printf("This is the next instruction after " .
"the function ...");
}
The instructions of the main function are executed until the processor needs to “break” the normal flow of the program and go to the func instructions. When this step of “jumping” to func is executed, the parameters to func, num1 and num2 are transferred with the help of the stack. That is, they are pushed to the stack, and func can pop them from the stack and use them. Immediately after pushing these values on the stack, main should push the address to which func will return on completion. (In our example, this is the address of the printf instruction.) When func is finished, it knows to read this return address from the stack and go back to the “normal” flow of the program.
One other value on the stack is called a frame-pointer, since the processor refers to values on the stack by their offset from the stack pointer (SP). Whenever the SP value changes, the processor saves the current value on the stack. (The Intel does not have a dedicated frame pointer (FP), so it does it with the help of the ebp register.) The frame pointer is pushed to the stack following the return address.
To clarify this, let's look at another example:
void func(int a, int b)
{
int *p;
}
main()
{
int num;
num = 0;
func(num);
num = 1;
printf("num is now %d \n",num);
}
Let's compile it with the -S option to get assembly output using this gcc command:
gcc -S -o ex2.S ex2.cWe see that main's code is actually:
main:
pushl %ebp
movl %esp,%ebp /* Save the SP before changing
* its value */
subl $4,%esp /* SP should subtract 4 so it
* points to num on the stack */
movl $0,-4(%ebp) /* Push num on the stack with
* value 0*/
pushl $2 /* Push 2 on the stack*/
pushl $1 /* Push 1 on the stack*/
call func /* Push return address on the
* stack and jump to the first
* instruction of func*/
...
The main code pushes the arguments for func, then calls it. The
call instruction puts the return address on the stack, then moves
on to the func code. func puts the
four-byte frame pointer immediately following the return address,
then pushes the p pointer onto the stack. Thus,
if we dump the stack's status now, we get the structure shown in
Figure 2.

Figure 2. Stack Structure
We can use func to print the addresses of a and b in a hexadecimal format; to do this, we simply add printf instructions:
void func(int a, int b)
{
int *p;
printf("The address of a on the stack is %x\n",
&a);
printf("The address of b on the stack is %x\n",
&b);
}
When we run the modified program, we get the following output:
The address of a on the stack is bffff7ac The address of b on the stack is bffff7b0Integer b is four bytes from integer a. Looking at Figure 2, we see that integer b is followed by the four-byte frame pointer, then the four-byte return address.
We can look at the return address using the disassemble option of gdb. (See Listing 1.) The call instruction in <main+17> is at address 0x80484b1, which means the next instruction in 0x80484b6 is the return address. As we just calculated, when this address is pushed on the stack, it is offset eight bytes from b and 12 bytes from a.
Since the stack is writable, we can use the pointer to the return address, then change its value. By doing so, we manipulate the normal flow of the program so we can, for example, skip some instructions. In Listing 2, we have changed the return address so our program skips an instruction. Compile and execute:
gcc -o ex4 ex4.c ex4
This output is returned:
The return address is 80484d2 The new return address is 80484dc Num is now 0In the Listing 2 code, we point to the address of integer b with the help of a pointer p, then subtract eight bytes down from p so it points at the return address printed in the first output line. Next, we add ten bytes to the return address, so it skips the num=1; assembly code. (disassemble main shows the exact offset of the instructions, so I used it to know how many bytes to skip.)
In this way, a programmer can regulate the normal flow of his program from within. The big question is, can someone change this return address from the outside? The answer is sometimes. Not only can this address be changed, but it can also be changed to point to code not within the program.
Listing 3 is a very simple program that can be exploited from the outside. On first execution, the output looks like this:
bash# ex5 Please enter your input string: short This is the next instruction
On second execution, the output is:
bash# ex5 Please enter your input string: long string This is the next instruction Segmentation fault (core dumped)Since strcpy does not check the length of the string it copies, we inserted the 12-byte string long string\n to a buffer which is eight bytes long. The first eight characters from my input completely filled the buffer, then the remaining four characters overflowed the buffer. That is, these four characters overwrote the adjacent address in the buffer --the return address. Thus, when func tried to go back to main, a segmentation fault occurred, since the return address contained the four-character string ing\n, most likely an illegal memory address.
The strcpy function is the classical example for buffer overflow since it does not check the copied string size to ensure it is within the buffer limits. Note strcpy is not the only way to exploit a program with a buffer-overflow hack.
The actual buffer-overflow hack works like this:
Find code with overflow potential.
Put the code to be executed in the buffer, i.e., on the stack.
Point the return address to the same code you have just put on the stack.
Since this is not the Linux “hack.HOWTO”, I will not go into details on these three stages.
The first stage is very easy, especially in a Linux system, since a huge amount of open-source code applications are available for Linux. Some of these applications are in use on almost every Linux system. Good examples of such programs were mount and some early versions of innd. mount did not check the length of the command-line arguments the user entered and its permissions set to 4555. innd did not check all of the news message headers, so by sending a specific header, a user could get a remote shell on the server.
The second stage has two parts. The first one is to find how to represent the code to be executed; this can be done using a simple disassembler. The second part depends on where the program reads the buffer: in some cases, a mail header; in others, an environment variable whose length goes unchecked; in still others, some alternate means.
The third stage is not so simple, as one cannot know the exact address of the code to be executed. Basically, it is done by guessing the address until the correct address is found. Several ways can be used to make this guessing more efficient; thus, after only a few guesses, we can specify the right address and the code gets executed.
The fact that an application is used all over the Web does not mean it is secure, so take care when installing a new application on your machine. In fact, WWW applications are more likely to be searched deeply for security holes by crackers with bad intent. System administrators should read the security newsgroup and related web pages in order to keep applications known to have security holes off the system and to upgrade them when patches become available. Application programmers should take care to write tight code containing proper checks for array and variable lengths in order to foil this type of hack.
Finally, I would like to briefly mention three other things. One, a kernel patch is available that makes the stack memory area a non-executable one. I have never tested it, since applications do exist which count on the fact that the stack is executable, and these applications will most likely have problems with this patched kernel. Two, a special mode to the Intel processor is available that has the stack grow from the lower memory addresses to the higher memory addresses, thus making a buffer overflow almost impossible. Three, a set of libraries available on some systems helps the programmer write code with no such errors. All the programmer has to do is tell the library functions the assumptions about a variable and these functions will verify that the variable meets the specified criteria.


