
The DF Command
The df command is used to show the amount of disk space that is free on file systems. In the examples, df is first called with no arguments. This default action is to display used and free file space in blocks. In this particular case, th block size is 1024 bytes as is indicated in the output.
The first column show the name of the disk partition as it appears in the /dev directory. Subsequent columns show total space, blocks allocated and blocks available. The capacity column indicates the amount used as a percentage of total file system capacity.
The final column show the mount point of the file system. This is the directory where the file system is mounted within the file system tree. Note that the root partition will always show a mount point of /. Other file systems can be mounted in any directory of a previously mounted file system. In the example, there are two other file systems, the first in mounted as /home and the second is mounted as /p4.
In the second example, df is invoked with the -i option. This option instructs df to display information about inodes rather that file blocks. Even though you think of directory entries as pointers to files, they are just a convenience for humans. An inode is what the Linux file system uses to identify each file. When a file system is created (using the mkfs command), the file system is created with a fixed number of inodes. If all these inodes become used, a file system cannot store any more files even though there may be free disk space. The df -i command can be used to check for such a problem.
The df command allows you to select which file systems to display. See the man page for details on this capability.
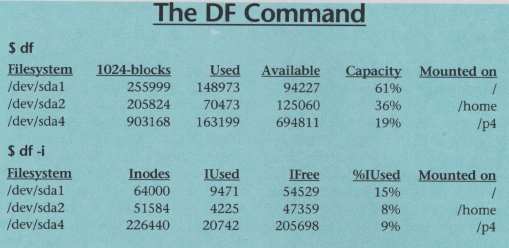
Figure 1. The DF Command
email: phil@ssc.com
