
Securing Networked Applications with SESAME
Security is becoming increasingly important for Intranet and Internet applications. We hear almost daily of new security incidents on the Internet, sites being penetrated or sensitive data being captured by attackers. There are a number of solutions that together can secure your network.
The first is a firewall with the aim being to control access between networks. Typically they are used at a site's Internet connection to control who can get in and out between the site's internal network and the Internet. In some intranets, firewalls are also used to control access within the network.
However, firewalls are not the end of the solution. Firewalls do not protect applications behind the firewall from internal attack or secure applications that need to communicate through the firewall. We require a method to secure applications; the client and server portions of an application need to verify each other's identity (authentication), and data being transferred across networks must be protected from unauthorised viewing (confidentiality protected) or modification (integrity protected).
We have recently ported SESAME to Linux, and it provides a wonderful tool for anyone who needs to secure their applications on Linux. SESAME is also available on a range of other Unix platforms, so your Linux systems will be able to work with these, too.
The SESAME Security Architecture is an extension of Kerberos, arguably the most famous and most successful architecture to date for securing networks (http://web.mit.edu/kerberos/www/index.html). Kerberos was developed at MIT, starting around 1985 as part of project Athena. Kerberos was designed to be a network authentication service. It also provides confidentiality and integrity services to data during transit.
Kerberos works using a trusted third-party model. That is, somewhere on the network a Kerberos Authentication Server exists which can verify the identity of the client and server and provide proof to the other party of that authentication. Authentication is actually achieved by the client (acting on behalf of a user) and the server providing proof to the Kerberos Authentication Server that they know a DES cryptographic key (the user and server share their DES cryptographic key with the Kerberos Authentication Server).
Kerberos is very successful if industry acceptance is any guide. It is now being used widely for securing networks, although in many cases you may not realize you are actually using it. For example, Kerberos is built into a number of operating systems providing security to the rtools and NFS on Linux and Solaris, and it is being used as the basis of the cryptographic library on Windows NT. It is also part of a number of firewall implementations.
Kerberos was designed for a closed Intranet environment, where the users and applications are managed by one administration. Although Kerberos is a good security architecture for such an isolated network, it has problems scaling to a large inter-networked environment (e.g., the Internet). Kerberos has two main problems that limit its scalability: the use of DES cryptographic keys for authentication and the lack of a user privileges (authorization) service.
The lack of scalability through the use of DES cryptographic keys for authentication is known as a key management problem. For authentication to be possible between client or server and the Kerberos Authentication Server in such an arrangement, the system administrator needs to generate a DES cryptographic key and share it securely with the two parties involved. In a small network with a single group of system administrators it is a feasible solution, but in a large inter-network, securely sharing keys is difficult.
Kerberos also lacks an authorization service. When a client application working on behalf of a user connects to the server, the server needs to know the privileges of the user. Kerberos depends on the fact that the user's privileges are already stored on the server computer. For example, the user has an account on the server, or the user's privileges are known to the server application. This arrangement is not scalable, because in a large inter-network it is certainly not possible for every server computer to be configured with every possible user's privileges. We require another method for the server to gather the user's privileges.
SESAME is the Secure European System For Applications in a Multi-Vendor Environment (http://www.esat.kuleuven.ac.be/cosic/sesame.html). Some people call it the European equivalent of Kerberos, but in reality it is a much improved security architecture. SESAME provides the complete authentication service of Kerberos, including confidentiality and integrity during transit, and adds to it an authorization service and public key cryptography. Both additions allow SESAME to be much more scalable to a large networked environment than Kerberos. It also adds an excellent auditing system and provides a privilege delegation scheme.
SESAME was also designed to be completely platform independent. It uses a role-based, access-control model that allows SESAME to easily interoperate with many operating systems.
SESAME development began around 1990 by ICL, Bull and Siemens Nixdorf, with the current release SESAME Version 4 (which is the version we have made available for Linux).
SESAME has an Authentication Server similar to Kerberos, but adds to it a Privilege Attribute Server. The idea here is that a user can not only be authenticated, but also provided with privileges, which can be presented to the server when required. This allows a user to access a server that has no knowledge of a user but is able to verify the privileges provided. SESAME also allows authentication based on public key technologies (as well as the standard Kerberos DES cryptographic key method).
SESAME is also gaining industry acceptance. The ICL Access Manager (http://www.icl.co.uk/access/) and ISM Access Master (http://www.ism.bull.net/) are commercial products based on SESAME. These products are being used to secure large Internet wide networks.
SESAME provides the Generic Security Services Application Programmer Interface (GSSAPI), which is a library of security routines. The aim of the library is to provide a standard method to secure client/server networked applications, and the GSSAPI is now an Internet Standard (RFC1508). Our experience with the GSSAPI is that it is small enough to be easily understood (only about 20 routines), although it takes some time to understand all of the possibilities of each routine. The GSSAPI is becoming increasingly popular for securing applications, and the SESAME version of the GSSAPI provides the full implementation.
Figure 1 shows some segments of GSSAPI code. In the code segment, the client is authenticated to the server and data is protected during transit. The segment highlights the fact that it only takes a dozen or so extra lines of code in your client and server application to secure them (other than variable declarations). In the code segment only the client is authenticated, although with a few extra lines of code the server could also be authenticated to the client.
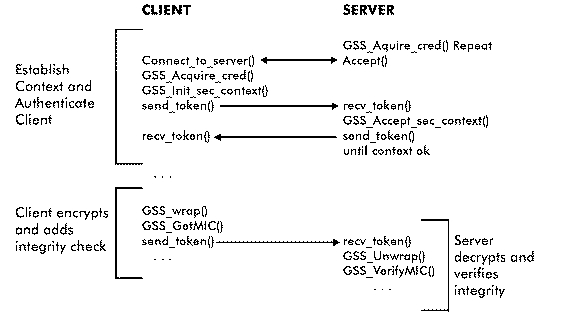
Figure 1. GSSAPI Code Representation
To secure your client/server applications, you insert the GSSAPI library calls at the appropriate points in your code and then rebuild the application. In a very short time it may be possible to convert an insecure application into a secure one, depending on how well structured your application is.
SESAME is already available on a range of platforms: AIX 3.2 on Bull DPX 20, SINIX (Unix SVR4) on SNI MX300i, Unix SVR4 on ICL DRS6000 and AIX 3.2 on IBM RS6000. We have spent around 12 months porting SESAME to Linux. The main problems were:
The SESAME source made numerous assumptions about the Unix environment on which it was being built. These include absolute paths in scripts for Unix programs, assuming that the root home directory was / (in our case it was /root) and so on.
The documentation was quite extensive but still did not make it easy to build and configure the system. The order of information was not always logical, and in some sections was far too brief.
The code had a number of memory bugs. These include over-running array bounds and memory leakages.
After securing a number of applications, we are happy with the stability of our Linux version of SESAME. It is already being used here in Australia, in Europe and in North America. We have written comprehensive building, installation and configuration guides and have a number of reports available to help you get SESAME working on your networks (http://www.fit.qut.edu.au/~ashley/sesame.html).
To get SESAME working, you first download the source from the European web site (listed in the beginning of the SESAME section) and then download our Linux patches to modify the source and build SESAME for you (we have automated it down to a one line execution). After this you follow our installation and configuration guides, which describe how to start the SESAME Security Servers, how to setup accounts for users and how to create the cryptographic keys that will be used for your security. New administrators of SESAME will probably take about two days to get SESAME working and understand what they are doing.
We are also working on building a library of SESAMIZED applications for Linux. In cooperation with other SESAME developers, we have concentrated on producing a SESAMIZED TELNET, FTP, rtools and NFS. This development is ongoing with the aim of providing a comprehensive suite of applications for Linux networks.
We have concentrated on Red Hat Linux for our port. There was no particular reason for using this version of Linux other than we are using it for related work. The first version of the port was completed on Red Hat Version 3.0.3, although lately we have it working on Red Hat Version 4.1. We have also tried SESAME on Slackware Linux and it worked without any modification.
SESAME is an advanced, scalable network security architecture. SESAME's GSSAPI allows you to quickly secure your client/server applications. It provides all of the services of Kerberos, with the added advantage of being scalable as your network grows. SESAME is now available for Linux, together with comprehensive documentation, and a comprehensive suite of SESAMIZED applications for Linux is under development.


