
Linux Network Programming, Part 3
In the last few articles in this series, we dealt with basic low-level network programming in Linux, and with the issues involved in developing network servers (daemons). However, coding at this low level is extremely tedious and prone to error as a result.
Nevertheless, distributing an application over the network provides significant benefits over a monolithic, stand-alone structure—and these benefits make the additional development investment (in terms of time and money) worthwhile.
In this article, we will introduce an approach intended to reduce the added complexity in writing a network application by applying object-oriented techniques to the development and coding—namely, the use of the Common Object Request Broker Architecture (CORBA).
In the next article, we will present different software packages, available for Linux, which implement the CORBA standards. In addition, a basic introduction to developing applications with CORBA will be given.
Note that this article assumes a basic familiarity with C, C++, object-oriented development, the BSD socket API and RPCs. It presents the key concepts of CORBA which need to be understood before developing applications. These concepts, and the associated terminology, comprise much of the learning curve of CORBA. This article is necessarily theoretical in order to develop a vocabulary to be used when developing with CORBA.
The motivations for structuring a system as a set of distributed components include:
An increased ability to collaborate through better connectivity and networking
The potential to increase performance and efficiency through the use of parallel processing
Increased reliability, scalability and availability through replication
A greater cost-effectiveness through the sharing of computing resources (for example, printers, disk and processing power) and the implementation of heterogeneous, open systems
Along with these impressive advantages comes additional complexity to the development process. The programmer now has to handle situations like the following:
Network delay and latency
Load balancing between the different processing elements in the system
Ensuring the correct ordering of events
Partial failure of communications links, in particular with regard to immutable transactions (i.e., transactions which must yield the same result if repeated—for example, the accidental processing of a bank transaction twice should not erroneously affect the account balance)
One of the earlier techniques in reducing the programmer's work (to develop these distributed applications) was the remote procedure call (RPC).
RPCs have already been introduced in Linux Journal in an excellent article by Ed Petron, “Portable Database Management with /rdb”, October 1997. The motivation behind RPCs is to make network programming as easy as making a traditional function call. Linux provides the Open Network Computing flavor of remote procedure calls (ONC-RPC), which was originally developed by Sun Microsystems (Mountain View, CA) for use in its Network File System (NFS) implementation.
RPCs do nothing more than hide the implementation details of creating sockets (network endpoints), sending data and closing the sockets as required. They are also responsible for converting the (remote) procedure's (local data) parameters into a format suitable for network transportation and again into a format that can be used on the remote host. This network-transparent transmission of data ensures both end machines can interpret the information content correctly.
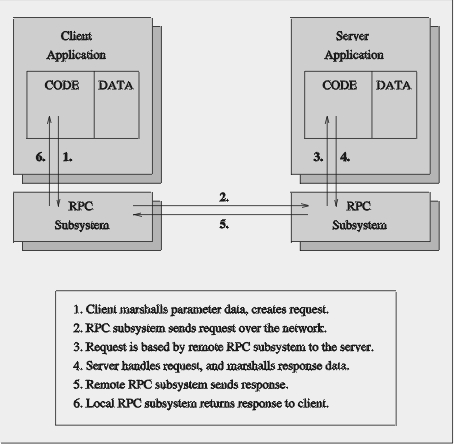
Quite often, different representation issues are involved in this process (for example, byte ordering, ASCII to EBCDIC, etc.). Additionally, pointers (references to address locations in a virtual memory space) cannot be passed directly from one process/machine to another. Instead, a “deep copy” needs to be performed, copying the data pointed to by the pointer which is then sent “across the wire”. The entire procedure of transferring the data from the native format of a machine into a network-transparent format is called “marshalling”. The reverse procedure is called “de-marshaling”. The ONC-RPC uses a special type of marshaling called external data representation (XDR). Figure 1 shows the sequence of events involved in a remote procedure call. The mechanisms and semantics of ONC-RPCs are discussed in much greater detail in RFC 1831, RFC 1832 and RFC 1833.
As mentioned, RPCs follow the traditional functional model. State information may need to be maintained independently at both client and server (depending on the type of application). This data is often repeatedly re-transferred across the network on each remote function call.
An alternative architecture is to use techniques from object-oriented development and to partition the system into a set of independent objects. Each object is responsible for maintaining its own internal state information.
By using an object-oriented approach to your network software development, you can promote certain beneficial traits in your code:
Encapsulation: ensuring a clear separation between the interfaces (through which the objects in your system interact with one another) and their implementations
Modularity, scalability and extensibility
Re-usability (of code and, perhaps more importantly, of design)
Inheritance and specialization of functionality and polymorphism
The act of sending a message from one entity on a network to another is remarkably similar to one object invoking a method on another object. The integration of distributed network technology and object-orientation unites the features of a basic communications infrastructure with a high-level abstraction of these interfaces and a framework for encapsulation and modularity—through this, developing applications which inter-work is significantly more intuitive.
In 1991, a group of interested parties joined to form the Object Management Group (OMG)--a consortium dedicated to the standardization of distributed object computing. The OMG supports heterogeneity in its architectures, providing the mechanisms for applications written in any language (running on any operating system, any hardware platform) to communicate and collaborate with each other—in essence, the development of a “software bus” to allow for implementation diversity, as a hardware bus does for expansion cards.
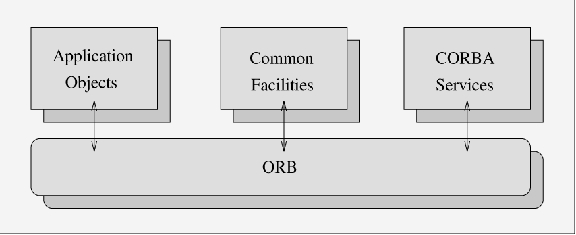
The OMG architecture which permits this distributed collaboration of objects is called the Object Management Architecture (OMA). Figure 2 shows the object management architecture.
Figure 2. Object Management Architecture (OMA)
CORBAservices provide the basic functionality for the management of objects during their lifetime—for example, this includes:
Naming (uniquely specifying a particular object instance)
Security (providing auditing, authentication, etc.)
Persistence (allowing object instances to be “flattened” to or created from a sequence of bytes)
Trading (providing objects and ORBs a mechanism to “advertise” particular functionality)
Events (allows an object to dynamically register or unregister an interest in a particular type of event, essentially decoupling the communication from the object)
Life-cycle (allows objects to be created, copied, moved, deleted)
Common Facilities provide the frameworks necessary for application development using distributed objects. These frameworks are classified into two distinct groups: horizontal facilities (commonly used in all applications, such as user-interface management, information management, task management and system management), and vertical facilities (related more to a particular industry, for example telecommunications or health care).
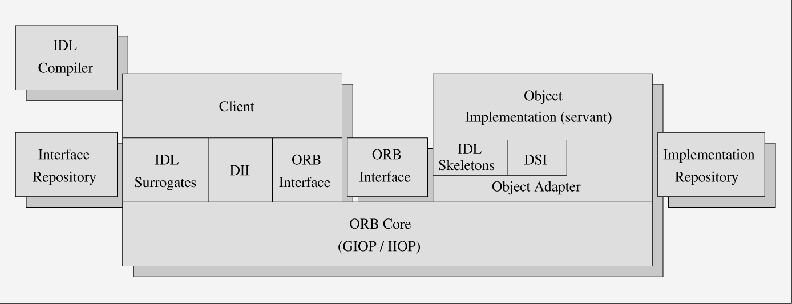
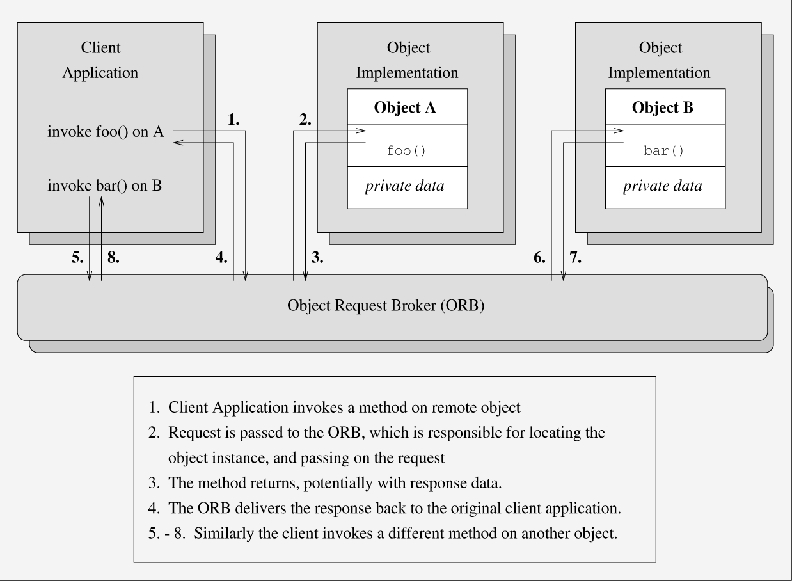
The CORBA standard specifies an entity called the Object Request Broker (ORB), which is the “glue” that binds objects together to enable higher-level distributed collaboration. It enables the exchange of CORBA requests between local and remote objects. Figure 3 shows the architecture of CORBA. Figure 4 shows the invocation of methods on different remote objects via the ORB.
Figure 3. Common Object Request Broker Architecture (CORBA)
Figure 4. Calling a method within a specific object instance
In the OMA, objects provide services. Clients issue requests to different objects for these services to be performed on their (the client) behalf. The repetitive transmission of state information that is common with RPC applications is avoided since each object is responsible for maintaining its own state. In addition, the objects interact through well-defined interfaces and are unaware of each others' implementation details. As such, it is much easier to replace or upgrade an object implementation, as long as the interface is maintained. The objects in an OMA/CORBA system may take on many different roles in relation to one another: peer-to-peer, client/server or publish/subscribe, etc.
Before an object can issue a request to invoke a method on an object, it must have a valid reference for that object. The ORB uses this reference to identify and locate the object—thus providing location transparency. As an application writer, you need not be concerned with how your application finds an object, the ORB performs this function for you transparently. In a similar fashion to how RPCs use XDR, CORBA specifies the common data representation (CDR) format to transfer data across the network.
An object reference does not describe the interface of an object. Before an application can make use of an object (reference), it must somehow determine/know what services an object provides.
Interfaces to objects are defined via the Interface Description Language (IDL). The OMG IDL defines the interface of an object by means of the various methods they support and the parameters these methods accept. Various language mappings exist for the IDL (for example, C, C++, Java, COBOL, etc.). The generated language stubs provide the application with compile-time knowledge which allows these interfaces to be accessed.
The interfaces, alternatively, can be added to a special database, called the interface repository. The interface repository contains a dynamic copy of the interface information of an object, which is generated statically via the IDL. The Dynamic Invocation Interface (DII) is the facility by which an object client can probe an object for the methods it supports and, upon discovering a particular method, can invoke it at runtime. This involves looking up the object interface, generating the method parameters, invoking the method on the remote object and returning the results.
On the “server” side, the Dynamic Skeleton Interface (DSI) allows the ORB to invoke object implementations that do not have static (i.e., compile time) knowledge of the type of object it is implementing. All requests to a particular object are handled by having the ORB invoke the same single call-up routine, called the Dynamic Interface Routine (DIR). The Implementation Repository (as opposed to Interface Repository) is a runtime database of information about the classes the ORB knows of, its instantiated objects and additional implementation information (logging, security auditing, etc.).
The Object Adapter sits above the core ORB network functionality. It acts as a mediator between the ORB and the object, accepting method requests on the object's behalf. It helps alleviate “bloated” objects or ORBs.
The Object Adapter enables the instantiation of new objects, requests passing between the ORB and an object, the assignment of object references to an object (uniquely naming the object), and the registering of classes of objects with the Implementation Repository.
Currently, all ORB implementations must support one object adapter, the Basic Object Adapter (BOA).
All of this talk about interoperability is not useful unless ORBs from different developers/vendors can communicate with one another. The General InterORB Protocol (GIOP) is a bridge specifying a standard transfer syntax and a set of message formats for the networking of ORBs. The GIOP is independent of any network transport.
The Internet InterORB Protocol (IIOP) specifies a mapping between GIOP and TCP/IP. That is, it details how GIOP information is exchanged using TCP/IP connections. In this way, it enables “out-of-the-box” interoperability with IIOP-compatible ORBs based on the world's most popular product and vendor neutral network transport—TCP/IP.
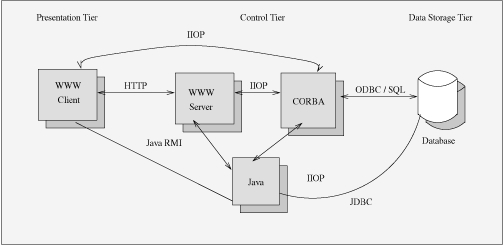
CORBA is an example of what is termed “middleware”--a technology that enables the separation of applications into three distinct sections (see Figure 5):
The presentation, or user interface, tier
The business logic, or control, tier
The data storage tier
Figure 5. Three-Tier Network Computing
The presentation layer could be an HTML form or a Java applet (as in Figure 5). Extracting the control logic from the presentation allows you to network-enable the presentation of your application.
It also allows the end user to use less expensive hardware to interact with the application, since their equipment is now responsible only for rendering the information supplied to it by the control logic. In addition, the presentation system does not need to have any knowledge of where the data originally came from or in what format it is stored in the database—all it needs is the interface to the middle layer.
The control logic can perform access management, alter the view of the information as required to enable different users to view different subsets of the same data—perhaps for security reasons. For example, a doctor in a hospital may want to see the patient's medical history, whereas someone from the finance department should only be able to see billing information. In Figure 5, either Java or CORBA performs the role of the business logic.
By separating the control logic from the data store, you gain the benefits of distributed computing. Your logic can encapsulate database access, providing you with scalability and fault-tolerance for mission-critical data. All sources of corporate information can be integrated via the control logic to achieve what is termed a “data warehouse”--allowing all the information to be accessed via a single interface (depending, of course, on security clearance).
Legacy systems can be encapsulated, thereby protecting your existing investments. By standardizing the interface between the business logic and the data, you can more easily replace or upgrade database systems. The desktop machines (responsible for presentation) do not need to be modified. The task of replacing a database becomes solely concerned with that action—moving data from one database to another, without affecting the other components of the system.
The control logic can also augment the capabilities of the data storage system, performing additional features, such as searching the information for non-obvious trends (a process called “data-mining”).
The separation of application systems into a number of distinct tiers, and standardizing the interfaces between these tiers, ensures that when you make a modification to one layer, the effect of this change on your entire architecture is localized.
In this article, we introduced the Common Object Request Broker Architecture, a developer's tool in implementing applications based on distributed object technology. We also discussed the benefits of an object-oriented approach to network programming over traditional functional approaches, such as the use of RPCs. Finally, we introduced one of the main interests in CORBA technology—enabling the deployment of business applications on a network using a multi-tiered approach.
The next article will discuss the various ORBs available for Linux and how to begin programming with CORBA.

Mark Donnelly is also a postgraduate student in the ECE department at the University of Limerick, Ireland. Mark is interested in Aikido, Linux, CORBA, Distributed Agents and Alpha World. His e-mail address is mark.donnelly@ul.ie.
Dr. John Nelson is a senior lecturer in Computer Engineering at the University of Limerick, Ireland. His research interests include telecommunications (mobile/broadband), VLSI design, and software engineering. His e-mail address is john.nelson@ul.ie.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}