
Raima Database Manager++, Velocis Database Server

Manufacturer: Raima Corporation
E-Mail: sales@raima.com
URL: http://www.raima.com/
RDM++ Price: $995 US (royalty free)
Velocis Price: $495 US (2 users)
Reviewer: Nick Xidis
Raima Corp. offers three products: the Raima Database Manager++ (RDM++, formerly db_Vista), a database management library for C, Raima Object Manager(ROM), a persistent class library for C++, and the Velocis database server, which supports both the RDM++ API and ANSI SQL. All three support transaction logging and recovery, compound keys and time stamping. The most unique feature of the Raima line-up is the combination of pointer and relational data navigation. I tested all three using Caldera's OpenLinux Standard 1.1 on a DEC P-90 with 40MB RAM. I'll cover the RDM++ and Velocis server in this review.
The installation is a snap. Just unpack the two floppies using tar and run the makeall shell script. RDM++ compiles with no significant errors. I had one minor gripe, the makeall shell script should ask for extra compile flags; I would have liked to add a -O3 flag.
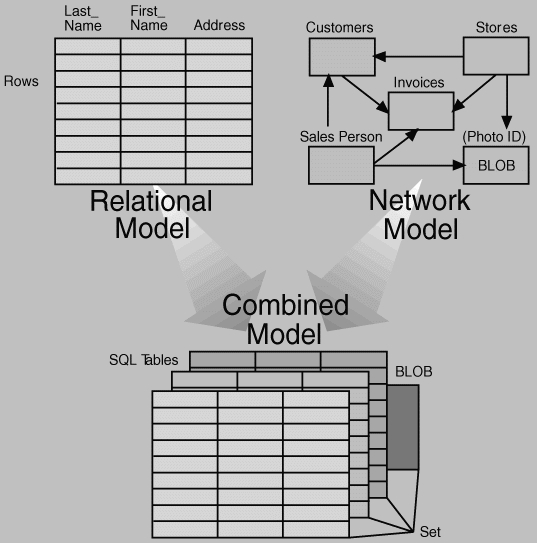
To create databases, begin with a .ddl file that defines the schema for the database. Tables are defined in a format that is very similar to STRUCT in C. Also, defined in the .dll file are sets. Sets define pointers to other records in the database. So, one record in a table can point directly to another without joining. This combination of tables (relational data model) and sets (network-pointer data model) is where RDM++ really shines. Using sets to point to other records is like having a permanent predefined join between tables and can speed up your application compared to the process of iterating over tables to create joins at runtime. In practice, I found that having joins built into the database produced shorter and cleaner code than similar applications using ISAM libraries. Once the .ddl files are built, the ddlp utility compiles a database dictionary and header files that supply constants needed by your application from the database.
The C API for RDM++ is a snap to learn, as all the function calls start with d_ and are very intuitive. To open a database, just call d_open; to read a record, d_recread. Don't think that because the API is intuitive that it's not rich—there are over 200 functions. The learning curve is very short; I was able to produce simple C applications within a couple of hours. One of the biggest aids in learning the API was the dal utility that allows d_ calls to be entered at the command line, just as they are written in sources. Almost any of the d_ function calls can be run interactively, and the results can be seen right away.
Another great time saver is the db_QUERY utility. This allows reports to be produced from RDM++ databases using SQL. Both tables and sets can be accessed from db_QUERY—sets appear as SQL views. You can use it either interactively or with canned query files. The neatest capability is that you can embed db_QUERY inside C applications. I used it at the command line to work out my queries. Then with a few function calls the same report is generated inside of my C application. For simplicity, the functions all start with q_ and there are only twelve of them.
I found this whole system of creating a database easy to understand and a joy to use. The only piece missing is a GUI report writer. Raima makes a fairly good one for MS Windows, but not for X.
Single-user applications can just be executed; however, to use the RDM++ multi-user mode, a lock manager is required. The lock manager runs in a separate process and manages the file locks for all the users of your application. The multi-user mode worked well. Record-level locking is not enforced by the lock manager, so you'll have to limit the number of users to 20 or less.
This is the one area in which the RDM++ falls short. If serious multi-user applications are going to be built with RDM++, you need record locks. I realize that there is some overhead with this option, but it seems well worth the cost.
Velocis is a back office power house. It supports all of the standard stuff that you'd expect in the best commercial database servers: transaction processing, ACID transactions, record and table locks, stored procedures, triggers and hot backups. It also supports a wide set of APIs: RDM++ C API, ROM C++ API (for storing C++ objects), ANSI 89 and most of the 92 SQL API and SQL Access Group's Call Level Interface (SAG-CLI, which is the same as Microsoft's ODBC level 1 API). In addition, the server is easily extended with C or C++.
Installing Velocis was fairly easy. Once the disks are unpacked using tar, run the install script which creates two files: rdshome.sh and rdshome.csh. These shell scripts export all the environment variables that Velocis needs to run. I copied the contents of rdshome.sh to /etc/profile so that it's available system wide. Each Velocis server (you can run multiple servers) must have a host alias and a port of the same name defined in the /etc/services file. Just fire up the server and you are ready to get started.
Velocis is administered from the rdsadm command-line utility. Velocis is fairly easy to use and understand, but the rdsadm utility is cumbersome and doesn't do justice to the quality of the server. Raima should supply an X windows GUI administration tool with Velocis.
Velocis is a dream for C programmers because the server extension modules (EM) and user-defined functions (UDF) are all implemented in C.
UDF are C shared libraries that contain scalar or aggregate functions that can be called from SQL. UDF use the standard SAG-CLI and are registered by using the SQL create function call. Once registered, UDF can be used like any other SQL function.
UDF can be used in conjunction with the SQL check clause to create triggers. Triggers run on the server whenever a table is changed. Thus, by using the check clause when tables are created, UDF and built-in functions can be executed automatically on the server. This is a great way to ensure that custom business logic is enforced on your database.
The Velocis server can also be customized outside the SQL system with extension modules. EM are essentially the same as user-defined functions but are invoked by clients directly using RPC calls. They are independent of the SQL system. As a matter of fact the whole SQL interface is an extension module. This modular design makes Velocis an excellent choice for vertical market applications where heavy customization is required.
Velocis also supports stored SQL procedures with the create procedure call, allowing a group of SQL statements to be executed with a single function call.
Conclusion
Raima's products are all winners. I especially like the RDM++ API. The .dll set up and the d_ functions are very easy to learn and are rich enough in features to be taken seriously. Even with Velocis I'd be tempted to use the low level d_ functions in place of SQL. SQL is still nice to have for reporting and system administration. It is, after all, almost the universal database language. Raima only misses on a couple of counts. First, the lack of GUI tools for Velocis, an administration tool and report writer for X Windows as a minimum are required for serious back office use. Second, Raima needs to beef up its Internet tools. Currently, there is only a Perl interface for Velocis. Raima should consider doing a JDBC type 4 driver and an HTML scripting tool like PHP/FI or Scriptease for ADABAS D. All in all Raima is a winner and worth a look for your next project.
Nick Xidis is a Telecommunications Specialist with the Federal Aviation Administration in Auburn, WA. When he's not at work with the FAA, Nick does private consulting for Linux/Unix systems. He also enjoys playing with his wife and five (soon to be six) children. He can be reach via e-mail at nickx@xsc.wa.com.
