
Polyglot Emacs 20.4
Ken'ichi Handa's Mule (multilingual Emacs) first appeared at the end of 1992. After almost five years, the Mule enhancements were included with GNU Emacs 20.x. For those of us who have yearned for multi-script capability since our first encounter with a computer (more than twenty years ago), it has been a long and often frustrating wait. We are now at GNU Emacs version 20.4 and things are finally beginning to look interesting to people who wish to work with multiple scripts on Linux. I am using Emacs for translation, exegesis and preparing reference material in multiple scripts.
Who wants to install a special Japanese Linux just to be able to read a Japanese source file for a translation job or read and write Japanese e-mail? I want to be able to include Chinese bibliographies, text and notes in the papers I write. I would also like to be able to include Tibetan or Greek scripts for philosophical or technical terms, along with their transliteration into Latin script. When I am discussing the structure of Chinese characters, I want to be able to make comparisons with Egyptian hieroglyphs. I want my quotations of French and German to look like French and German. I want to be able to publish all this on web pages as well as my PostScript printer. Some high-priced programs are coming out that address these issues, but Emacs 20.4 is here now. It runs on the best generally available operating system in the world, GNU/Linux, and it is free.
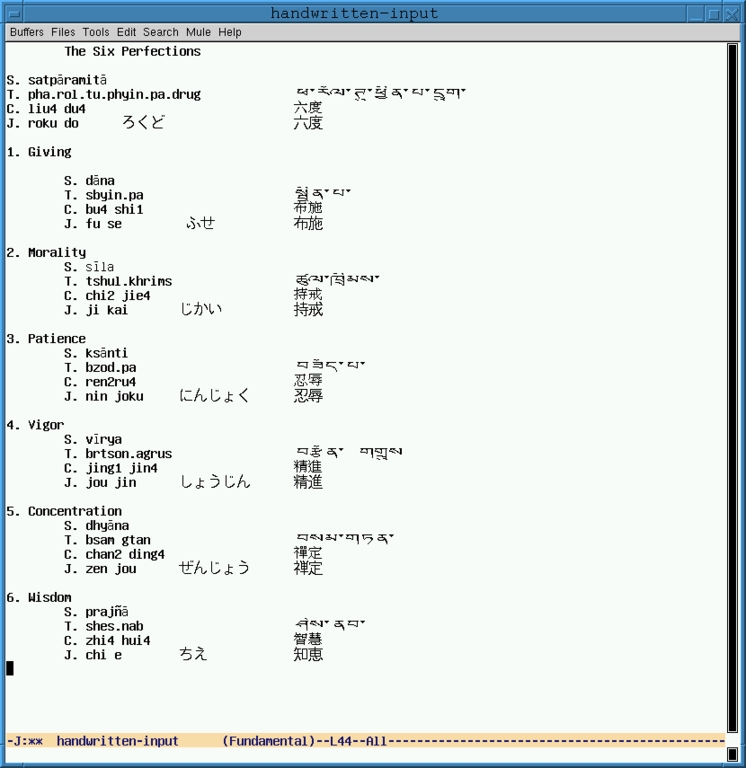
As an example of using Emacs to prepare multi-script reference material, let's look at the Buddhist numerical lists I am currently working on. Without much difficulty, I can write this list with a pen on a piece of paper. See Figure 1 for a bitmap of a page from my handwritten list. (Apologies for my poor calligraphy.) To get these scripts into a computer text file requires an input method specific to each script. Fortunately, Emacs comes with Quail, which has a method to input each script in this example and many more.
To invoke Quail for Devanagari, use the Mule menu or type:
ctrl-x return ctrl-\ devanagar-transliteration
Three other choices are available. For Tibetan, you will want tibetan-wylie. For Chinese, more than twenty methods are available. I use chinese-py-b5 for traditional characters and chinese-tonepy for the simplified characters. The Quail Japanese input method is adequate for short strings, but not extensive input. This is one place where I feel a free input method editor for Linux is needed that equals or surpasses Microsoft's free Japanese IME for Windows. Wnn 4.2, the last free version of Wnn, worked well. I have used it in the past with Mule, but so far I have not be able to get it to work with Emacs.
Soon, I hope to add the Korean, Thai, Lao and Vietnamese equivalents of each term in each list. All these are supported by Emacs. Finally, I hope to add the Mongolian script, which is not yet available in Emacs.
As you start to use several different input methods, you may soon find the command to invoke them, ctrl-x return ctrl-\ cumbersome. I rebind it with:
meta-x global-set-key f3 return set-input-method
While you're at it, you might as well bind the command universal-coding-system-argument to something handy—I use f2.
universal-coding-system-argument is the command that lets you specify which coding system you want Emacs to use when you execute your next command. If you do much multi-script work, this will probably be ctrl-x ctrl-v return, which revisits the file you just visited. On the revisit, Emacs uses the coding system you specified as the universal-coding-system-argument. From the main Emacs menu, you can select Mule/Set Coding System/Next Command to do the same thing. (See Emacs Manual 31.4.5 for details on rebinding keys.)
For information on each input method and sometimes a list of the characters you can use with it, type ctrl-h I. As usual in Emacs, tab will give you a list of choices if you don't know the exact name of the input method you are after. ctrl-g escapes from whatever you are doing in the mini-buffer. I said “sometimes” because some lists are missing. For example, in response to ctrl-h I ipa, Emacs returns “Input method: ipa (IPA in mode line) for IPA International Phonetic Alphabet for English, French, German and Italian” but provides no list of the actual symbols. For Devanagari, on the other hand, a full list of the letters of the script is presented. Not given are the details on how to evoke several operations essential for being able to input the script properly. If you are familiar with the script, you can probably hack your way through. If, like me, you are a beginner and merely attempting to input it from a transcription in Latin script, even assuming your transcription is precise, you will not be pleased. Detailed descriptions of the various input methods are needed.
Start with Tibetan. Type the Wylie transliteration and the script appears—very smooth. For beginners, it is easier than writing Tibetan by hand. For the time being, I had to give up trying to input Devanagari. You may have better luck.
All these input methods come in a package called Leim. As of this writing, Leim is bundled with the Emacs-20.3.92 from ftp://ftp.etl.go.jp/pub/mule/.notready/, but it must be downloaded as a separate package for the Emacs pre-release from ftp://alpha.gnu.org/. Anyway, if Emacs cannot find all files included with Leim when it compiles on your system, you won't have any input methods. Let's hope the distributions will include Leim by default and give you an option to exclude it.
To evoke the multi-script capabilities of the new Emacs, another essential ingredient is Intlfonts 1.x. At present, it is version 1.2. This package provides all the fonts you need to display all the scripts. It, too, must be installed before you will find any joy in multi-script work.
The latest version of ps-print.el that comes with Emacs allows you to at least dump your multiple-script files to the laser printer. Currently, you must be content with “not scalable” bit-mapped fonts where one size fits all, but this is an essential first step. Perhaps CJK-TeX by Werner Lemberg (xlwy01@uxp1.hrz.uni-dortmund.de) or Omega, the new, purportedly internationalized TeX, will generously give us the ability to produce high-class, camera-ready, multi-script output for printing and a description of how to do it.
In Figure 2, we see the same text as in Figure 1 entered into an Emacs buffer, or as much of it as I could enter without a better understanding of the Devanagari input method.
It could be argued that we should not look to Emacs for help in printing, aside from the minimum requirement of being able to dump multi-script texts to the printer. Maybe the same holds for Web publishing—I don't know. However, it is frustrating to create a document in five or more scripts perfectly well in Emacs and then not be able to print it at a camera-ready level of quality, or publish it on the Web where the only character set that would allow the inclusion of all five scripts, with some on-going support, is Unicode, particularly in its UTF-8 encoding.
If there were an option to map the multi-script file in Emacs to the Unicode character set and then save it in UTF-8 encoding, ithe file would be directly available as content for an XML or HTML document. True, some browsers cannot understand Unicode yet, and the browser user may not have all the fonts installed, but this is bound to change for the better soon. One thing for sure: few will be able to read it in Mule internal format or even in a mix of ISO-2022 character sets/encodings.
Regarding a Unicode converter for Emacs, Miyashita Hisashi took a first shot at a Mule internal-encoding-to-Unicode converter with his MULE-UCS converter, but as of this writing I have not been able to install it. I noticed on the Unicode mailing list that Mark Leisher (mleisher@crl.nmsu.edu) also has one under construction. Hopefully, by the time this article is printed, we will be able to produce a Unicode/UTF-8-encoded file from Emacs.
Once you have entered the multiple scripts into your Emacs buffer, you can marshal all the considerable forces of Emacs to work on your text. This is the big difference between Emacs and a program like Gasper Sinai's Yudit, for example. From a user's perspective, Yudit deals nicely with the encoding problems and it includes support for Unicode from the ground up, but most other features of a well-rounded editor have not yet been implemented.
Since Emacs is multilingual, it is also bilingual. Pick any two-language combination. I translate from Chinese to English (CE), mostly classical texts, and from Japanese to English, mostly commercial work for pay. Emacs has much to offer a JE or CE translator.
Emacs offers such helpful services as saving your cursor position in a buffer between sessions, saving the buffer arrangement of your Emacs session, splitting frames into Emacs windows and placing new frames in strategic locations on your big translator's virtual desktop, la FVWM2. It is also easily customized.
The five items of Emacs arcana that can be especially useful to a translator are saving and backup, outline minor mode, narrowing, abbrevs and bookmarks. See http://www.kanji.com/ for a more detailed version of the following.
Saving and Backup Using autosave
autosave is continuously taking care of the job of saving the latest version of your file. Use ctrl-h v auto-save-interval to check your current value for autosave. In the directory listing, an autosave version of your file is marked by pound signs (#), prefixed and suffixed to the filename.
I use make-backup-file to automatically produce sequentially numbered versions or drafts of my work. In this view, the file is complete right from the beginning, as soon as I save it with a name for the first time. Once my file has a name, it automatically becomes the “first version”.
It took a while to break my old habit of manually saving my file as often as possible, indeed each time I leaned back in my chair. Now I save only when I am ready to take a long break (like several hours or overnight), or when I feel I have reached the logical end of a certain draft version. The result is that I have only one autosave file at any given time, and a new draft (backup) file is produced at meaningful intervals. Use ctrl-h v make-backup-files to check or set. Use ctrl-h v version-control to check your current setting and the “customize” button found therein to turn on numbered backups.
By default, automatic deletion of backups will occur, thereby ruining the use of backups as a translator's simple version control system. Check the variables kept-old-versions and kept-new-versions. The default is 2, i.e., the first two and last two backups are kept; other backups are removed. To keep all backups, I set these variables to 500 each so a thousand backups will be kept before the ones in the middle are removed. After a translation job is finished, I usually delete them all.
Not only will you want to save your files, but also your constellation of visited buffers. This is done through the use of the Emacs desktop. Add these three lines to your .emacs file:
(load "desktop") (desktop-load-default) (desktop-read)
You must use meta-x desktop-save to initiate this process and then start Emacs from the same current directory each time you need to recover this state.
You can also save state within an Emacs session by using a register.
Outline Minor Mode
Until a full-scale major mode for translation is written, outline-mode or outline-minor-mode must take on the responsibility of managing the source text, the target text and related notes, comments and references.
In outline mode, there are two kinds of lines: header lines and body lines. Header lines start with a star in the leftmost column. The more stars, the deeper the level into the outline. One star means the line is at the top level. For short jobs, I have only one top-level heading line with the words TOP LEVEL or the title of the job. In longer jobs, I use it for Part One, Part Two, etc. I put contact information that applies to the whole job and notes about the deadline, size, charges and any special provisions as body lines below this top-level heading.
Within my translation environment, body text means notes and commentary. I find it extremely convenient to embed these directly in the working file rather than keep them as separate files. Such inter-linear notes are thus permanently welded to the text to which they relate.
Outline level 2 is always the Japanese or Chinese source text and level 3 is always my target text, the English translation. If I suspect there is a typo in the Japanese source text, my proposed correction can appear in the body lines connected to those level 2 heading lines, i.e., to those particular lines of the Japanese source text. Likewise, definitions, questions, reference sources, comments and notes on words, URLs and anything else that throws light on the translation are set down in body lines that are directly connected to the level 3 heading lines, which are always the English target text I am writing.
When I am finished translating, a keyboard macro strips out the level 3 lines (my translation) and produces the file that will go either directly to the client or through some unavoidable conversion, and even formatting, in a word processor running on Linux, such as ApplixWords.
It would be nice to see outline-mode generalized into a “show and hide” mode so that you could show body lines alone at whatever level you choose.
Narrowing
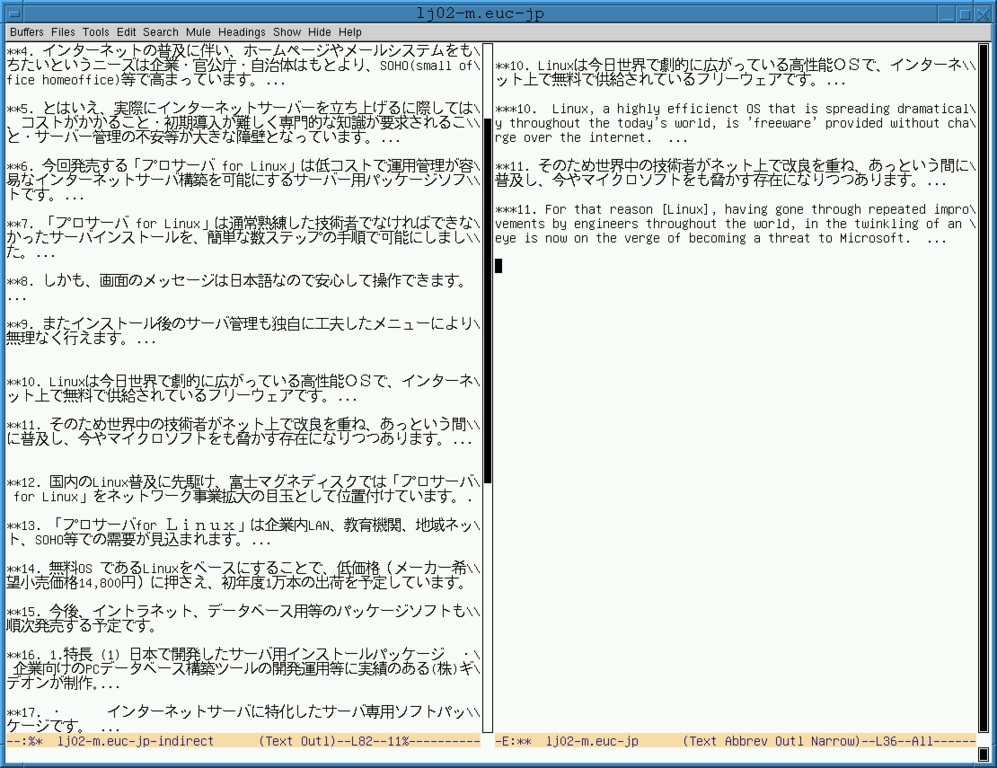
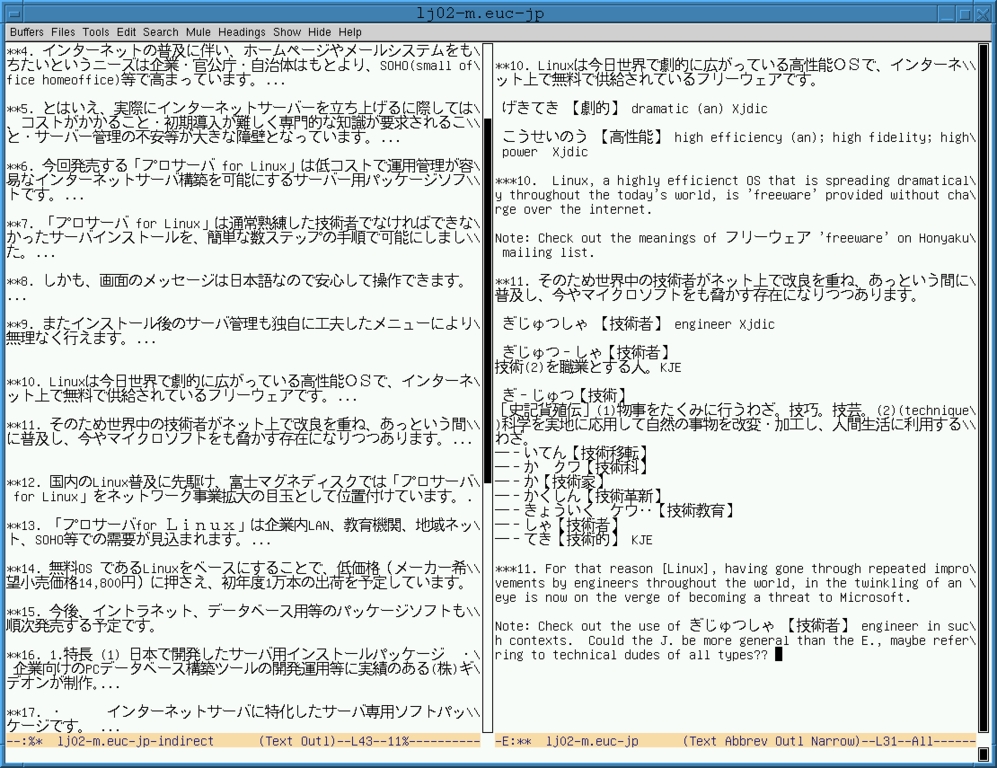
In effect, outline-mode or outline-minor-mode gives us a pre-structured kind of narrowing. Narrowing is more general in the sense that it can be arbitrarily applied to any portion of text in the buffer. Furthermore, with outline-mode or outline-minor-mode, it is quite possible to edit large chunks of the buffer that are not currently displayed. For example, if you delete or move the heading line, the entire entry under it including its body lines is deleted or moved. Narrowing, on the other hand, restricts editing to the narrowed portion alone. Place a mark at one end and point at the other. Then type ctrl-x n n and the accessible portion of the buffer will be reduced to precisely that region only. See the right-hand buffer in Figures 3 and 4 for examples. In both, the right-hand buffer is narrowed. Only the accessible portion is available for editing. ctrl-x n w widens, to make the entire buffer accessible again.
In Figure 3, what you see is reduced to just the Japanese source text and the English target text, i.e., level 2 and level 3 outline “heading lines”. In Figure 4, what you see is expanded to include snips from on-line dictionaries, notes and comments, i.e., outline “body lines”. But the accessible portion produced by narrowing is the same in both cases. For Figures 3 and 4, I used outline mode to keep source text, translation, abbrevs, glossary entries, notes and commentary all in one file. The left buffer shows only level 2 outline header lines, i.e., the Japanese source text, whereas the right buffer in Figure 3 shows this plus the target text and Figure 4 shows all three: source, target and notes.
Abbrevs
I use abbrevs primarily to help enforce consistency on my English target texts but also to avoid some typing.
Let me take an example from my non-commercial work but which applies to all types of CE/JE translation as well. Buddhism has a large vocabulary of “technical terms” that constantly reappear. In the Buddhist texts I work on, five of the most frequent are:
prajnaparamita -> pp
mahaprajnaparamita-sutra -> mpps
utmost, right and perfect enlightenment -> urpe
bodhisattva -> bs
the buddha said -> tbs
With abbrev mode turned on (meta-x abbrev-mode), typing bs followed by a space instantly inserts bodhisattva, pp inserts prajnaparamita, etc. With abbrev mode turned off, I can still force an insert before point (the position of the cursor) with ctrl-x a e (expand-abbrev).
When I am working on a commercial, technical JE translation job related to Linux, for example, I want to forget about Buddhist-related abbrevs, so I save and load files of abbrevs as appropriate.
Bookmarks and Registers
Bookmarks have arbitrary (long) names and remain from one Emacs session to another. Registers have one-letter names and disappear as soon as a session is ended. A bookmark tells Emacs where to go in a buffer, whereas a register stores data to insert into a buffer, such as a filename, a window configuration, a piece of text or a rectangle. Yes, a register can also store a location and thereby pretend it is a temporary bookmark.
You would think the proper function of a bookmark is simply to mark your place in a file so that whenever you revisit it, you will go to that location; however, I don't need bookmarks for this. I usually leave off at the location I want to return to, so that simply switching buffers via command, menu or ctrl-mouse_button_1 takes me back to where I was. Revisiting a file takes me there too, because I have place-saving turned on. (Use toggle-save-place to turn it on for a specific file and setq-default save-place t to turn it on globally for all files. [Added in Emacs version 19.19.]) Therefore, I feel free to use bookmarks for something less ordinary. ctrl-x r m bookmark_name sets the bookmark; the bookmark name is a string of Japanese or Chinese text, i.e., my glossary entry.
In Japanese, Emacs automatically sorts the kana bookmark names. (Kana are the graphic forms used to write the Japanese syllabary.) When I click on a bookmark, I am propelled directly to the work file where that word or phrase resides in an actual job. Beginning with Emacs 19.29, bookmarks could carry annotations. (Type ctrl-h m after meta-x list-bookmarks for more information on annotations.) I have co-opted this feature to carry the English glossary or meanings of the glossary entries (i.e., the bookmark names). If the annotation is sufficient, I don't need to visit the glossary entry in its location within a working file. If I want to see the context in which I have translated the word, phrase or sentence, one click lets me take a look, regardless of whether that file is currently being visited by an Emacs buffer or not. I can display the location in the file in a buffer that replaces my current bookmark editing buffer or have Emacs put it in a separate window adjacent to the buffer holding the bookmark list. I can also just ask Emacs to tell me the name of the file where the bookmark can be found without actually displaying it.
The one drawback to this neat, but nonetheless makeshift device, is that I can assign only one location to each glossary entry. If I want to add more, I must put them in the annotation.
Finally, for JE work, Emacs is not alone. As planets circle the sun, I surround Emacs with several programs that help me figure out the Japanese or Chinese source text or that aid in delivering it in a form demanded by a client. My assistants include the following:
Sumomo: a parser of Japanese syntax (no mean feat in a script where there are no spaces between words)
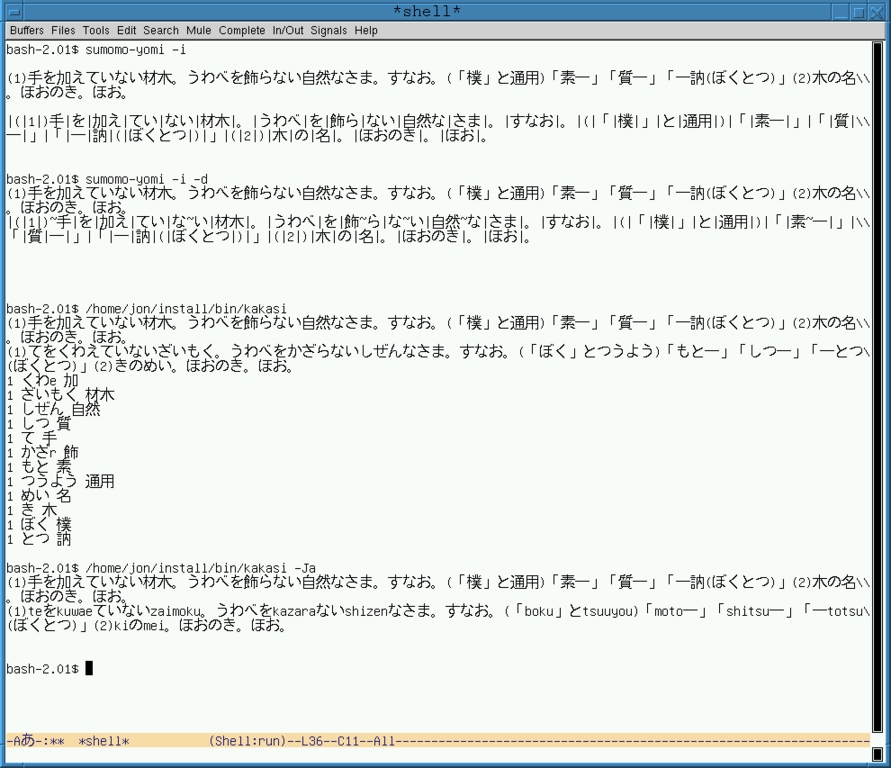
Kakasi: a converter of kanji into kana or Romaji (see Figure 5)
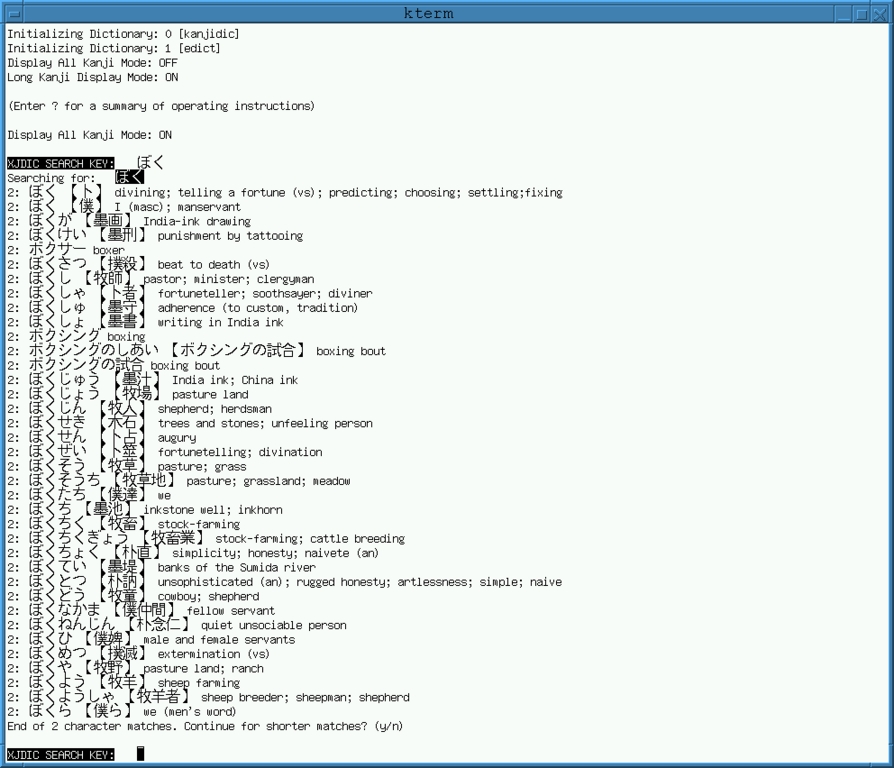
Xjdic: Jim Breen's JE Dictionary which, beside being extremely useful as a dictionary, is a splendid example of a collaborative, Net-based project (see Figure 6)
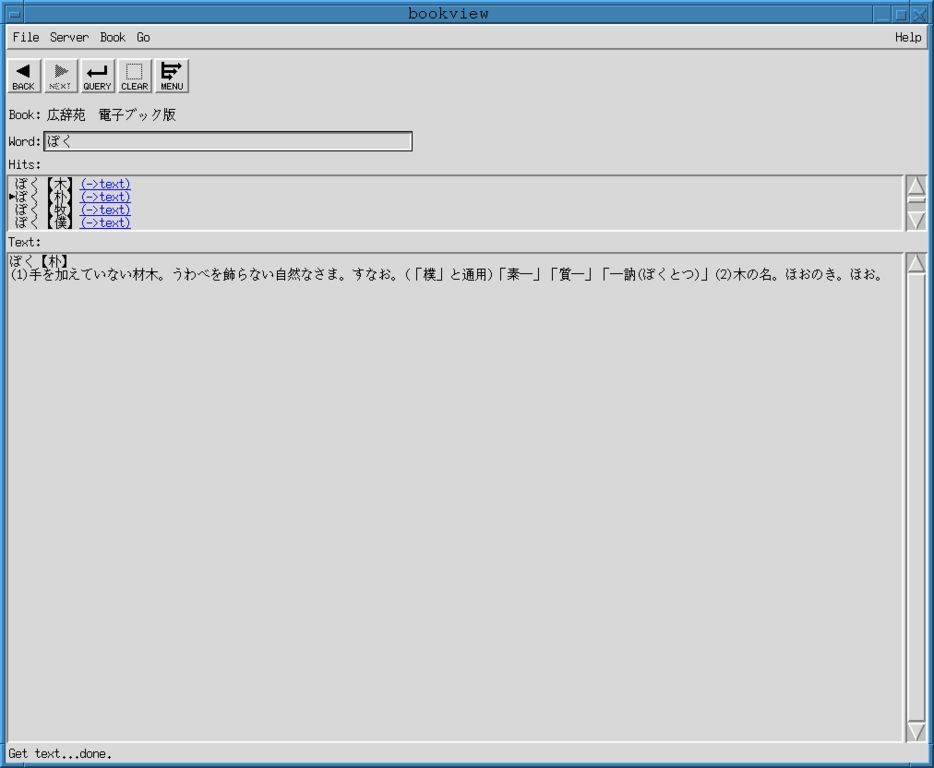
Bookview: a front end to ndtp, a server of Japanese electronic reference books (see Figure 7)
Also available are many nifty GNU or GPL-licensed programs that circumambulate the Linux kernel and can be called into service at a moment's notice, such as ls, wc, grep, xdiff, telnet, ftp, wget and fvwm2. Finally, there is Mozilla, Star and Corel Office, ApplixWare, the American Heritage Dictionary and the Oxford English Dictionary.
Whatever your arrangement, to be productive it must be consistent and persistent, i.e., for a certain task (like CE or JE translation) you must be able to recreate the same arrangement quickly. I have an init.hook file configured so that these applications all start up when I start fvwm2. By renaming it, I can immediately set up a different desktop for a different task. (See Figure 8 for one possible layout of a translator's desktop.)
With Emacs 20.4, we have the first version of GNU Emacs that is equipped to function as the main tool in a multi-script text worker's workshop.
Jon Babcock lives on the old family homestead in Montana, far from the maddening crowd, studies karma and dharma and kanji culture and, when necessary, translates Japanese for pay. He started using GNU programs and Linux in 1992. He can be reached via e-mail at jon@lotus.kanji.com.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}