
Who Is at the Door: The SYN Denial of Service
Over the past few months, a denial of service attack, known as the “SYN Attack”, has become notorious. This attack can prevent access to your mail, WWW and other critical servers. The attack was first described in a paper by Robert Morris in 1985 and received little attention. It wasn't until 2600 magazine published source code to exploit this weakness in popular implementations of the TCP/IP protocol stack that this weakness grabbed the attention of Internet Service Providers. One provider, Public Access Networks Corporation of New York City, was attacked repeatedly last September, causing its mail and web servers to be unavailable to its users for extended periods of time. In this article we explain what SYN really is, why it's needed in TCP/IP, why the attack works and how to prevent it.
The Internet works as well as it does because its data communication protocols (IP, TCP and UDP) evolved over a decade through major revisions and trial-and-error “adjustments”. As a result, the protocols have developed a legendary robustness that makes them difficult to defeat; however, these protocols were designed with the basic assumption that all network administrators can be trusted. Unfortunately, this is not true in today's Internet environment. Given the right kind of knowledge, virtually any PC can be configured so that a malicious individual, acting as a system or network administrator, can bring down any number of servers on the Internet.
One of these vulnerabilities is called the “SYN” (synchronous) attack, and it can affect anyone who places a server on the Internet. The SYN attack is a denial of service attack, blocking others from connecting to your server.
The Internet protocol stack utilizes three primary layers of the OSI model. The lowest layer is the physical layer, and it contains the physical wires, network host adapter(s) and adapter device driver(s). The next layer is the data link layer, whose job is to read a stream of bits off the network and assemble them into frames for the next higher layer.
The Internet Protocol (IP) or network layer is the next layer. It examines the incoming frames to determine if they are IP packets and, if not, it passes the frame onto another protocol stack (e.g., Novell) or discards the frame as nonsense. If it is an IP packet, the packet contents are further evaluated by the IP layer for a number of IP related activities such as Address Resolution Protocol (ARP) or Internet Control and Message Protocol (ICMP), which the connectionless ping and traceroute applications employ.
If the packet is not one of the above formats, its content continues to be evaluated as a Transmission Control Protocol (TCP) or User Datagram Protocol (UDP) packet. If the packet contains a TCP header, it is posted to the next higher TCP layer. The verb “posted” is significant in that the packet is moved to another place for processing, and that processing will occur sometime in the future. In other words, it is at the IP-TCP boundary where information, driven by interrupts, “bubbles up” from the environment; it is at the IP-TCP boundary where information waits for processing based upon requests from programs that wish to communicate with the network. Therefore, the IP-TCP boundary contains a fixed amount of memory buffers allocated to network “activity” without the system really knowing what that activity is. It is at this boundary that the SYN attack works.
Before discussing the third Internet layer and how TCP establishes a connection, perhaps it is better to begin with an analogy that illustrates a typical network problem and how TCP overcomes the problem in its daily routine.
Our analogy begins on a college campus with a studious student (SS) who has the misfortune of being placed in a “party” dorm. On a typical evening, SS is studying at his desk trying to master some dry material on data link protocols for his computer networks class. Someone knocks at his door. Upon opening the door, he gets hit with a water balloon from his rowdy neighbors. Using the material from his network class, SS comes up with a solution to stop his pesky neighbors, yet still greet his invited visitors.
He decides on a “secret knock”—his friends announce themselves with a one to five knock code. SS hears the knock and goes to the door; however, he does not open it. Instead, he repeats the original knock and adds his own one to five knock code. Now the visitor knocks the next “sequence” of his code and repeats SS's knocks.
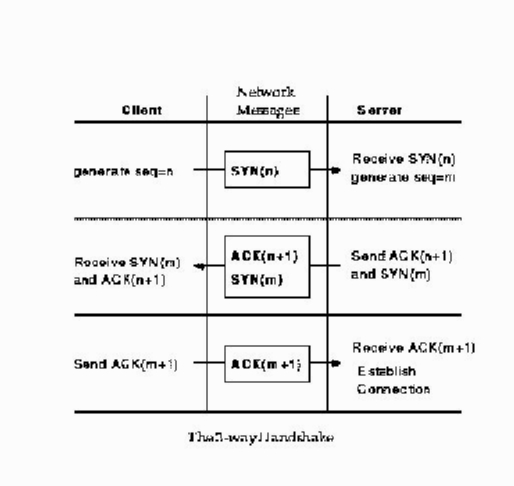
These knocking gymnastics are referred to as a three-way handshake (see Figure 1) in data communications lingo, and solve three common network problems. First, they allow two hosts to establish starting “sequence” numbers which are used by the receiver to re-order packets or reassemble datagrams. Second, they enable the host to identify duplicate packets that occur from re-transmissions which, in turn, are a result of delayed responses. Finally, if either computer were to initiate a connection with a third computer at the same time, then two orderly connections could result, without confusion.
Network traffic arrives at a given host and accumulates at the IP-TCP boundary, but nothing happens until a user-level process performs a request for network service through the transport station (TCP or UDP).
Most user-level Internet applications use a “virtual circuit” model for communication with web browsers such as Netscape or Lynx, FTP clients and Telnet clients. Steps in creating a connection or virtual circuit require the remote computer to request a “connect” which puts an IP packet in the local computer's IP-TCP boundary buffers. The local computer program requests a “listen”, then an “accept”. It is during these listen-connect-accept phases that TCP employs the three-way handshake to establish a virtual circuit.
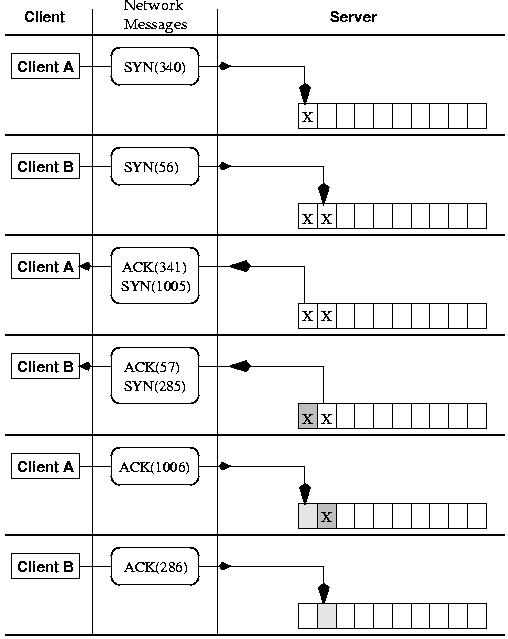
Let's say there are two hosts, A and B, which exist on a network. A wishes to connect to B and issues a connect request. There are six bits defined in the TCP datagram header, two of which are the “SYN” (synchronize) and “ACK” (acknowledge) bits. The connect request datagram has the SYN bit set and the ACK bit cleared. When the process on host B receives the datagram, it accepts the sequence number, builds a reply datagram with B's separate sequence number plus host A's sequence number incremented by one, and the datagram is sent to A with the SYN and ACK bits on. Host A now has confirmation that B has provisionally accepted the connection, and it sends out the first data using the incremented sequence from its first datagram and returning B's incremented sequence number as an acknowledgment. The datagram now has just the ACK bit set and when it is received by host B, the connection is established. (See Figure 2.)
Returning to the above analogy for a moment, we can see that the knock code is able to defeat SS's rambunctious neighbors, but what if they decide to knock once an hour or once every five minutes? What is our studious student to do? The knocks distract him from his homework, but if he ignores the knocks he misses any friends who come by. In other words, frequent knocks deny service to SS's friends.
The same is true at the IP-TCP boundary buffers. Once the host receives a SYN datagram and replies with an ACK datagram, how long does the host wait for the third part of the handshake? Unfortunately, current implementations wait forever.
Under normal circumstances, connections are established quickly, and so developers assumed that only a few buffers would be needed for all possible connections in the host. Under the 1.2.x Linux kernels, only 10 buffers are allocated.
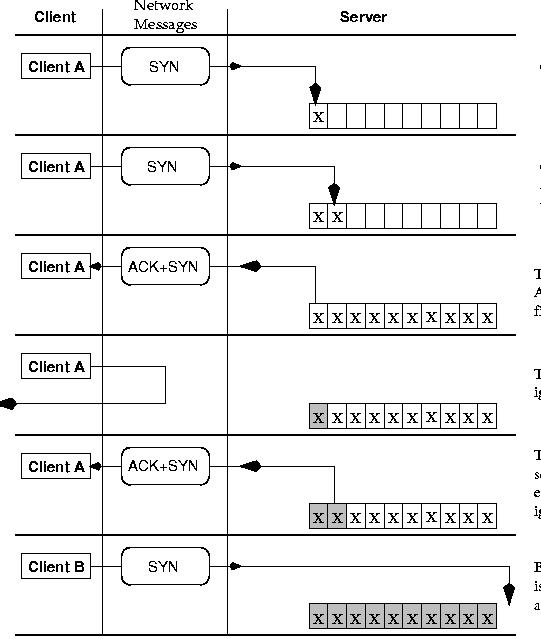
To create a SYN attack, a program does not simply use the connect request; instead it opens a raw network connection directly and sends a burst of TCP SYN datagrams, ignoring any replies from the target host. The few buffers are now full and the target host is unable to establish any subsequent connections. Service has been denied to the target host. (See Figure 3.)
What makes this attack so insidious is that the attacker also inserts random IP source addresses in each datagram, thereby making it almost impossible for the remote host to trace the datagrams back to the real source.
An Internet Service Provider (ISP) closed a user's account because the user violated their acceptable use policy. This user now gets an account at a competing ISP and, armed with the latest issue of 2600, dials up the new ISP using his PC running Linux. The user compiles the sample program given in 2600, and runs it repeatedly against his old ISP's mail server and web server, filling up the connection queue on the ISP's servers. No one can receive mail or reach the ISP's web pages.
After restarting his web server several times, an administrator at the ISP runs netstat and notices a lot of the entries are flagged SYN_RECV. All of these entries are from random IP addresses. The administrator tries to ping several of the addresses, but they all fail to return any pings. The administrator then calls his network provider, a prominent National Service Provider (NSP), and requests help in tracking the attacks to the source. Unfortunately, the NSP is very busy maintaining its network, and doesn't have the resources to assist in such a search.
The ISP goes out of business.
To lessen the severity of this attack, all providers should install the proper filters to prevent packages from leaving their network with forged source addresses, known as IP spoofing. This can be done by preventing packets that have a source address from outside your network from leaving your network.
Because the Linux kernel source code is under the GNU Public License (GPL), anyone with a copy of Linux is entitled to the source code. Having the source code, a user can apply a fix to his kernel and recompile it. If you were using a proprietary operating system, you would be at the mercy of your operating system vendor.
One of the easiest ways around this problem is to increase the size of the queue. This has been done in the 2.0.x kernels. If the queue is made large enough, it becomes more difficult for hosts with slow connections to the Internet (dial up, dynamic IP connections) to flood enough packets to prevent normal connections.
For your network servers to take advantage of the larger queue, they must be recompiled with a larger value as the backlog argument for the listen() function. Sendmail and inetd (found in NetKit-B) are two important programs that must be recompiled to “SYN-proof” your system.
A patch from Alan Cox implements random dropping of uncompleted connections, which prevents the buffers from filling, although the number of partially completed connections in the listen queue can increase. This same patch, which has yet to be integrated into the 2.0.x kernels as of patch level 27, also disallows a single class C from using up more than 30% of the queue. This last method prevents attacks from providers who have installed the source filters discussed above and from exploiters who do not use random source addresses.
The patch for the current kernel (2.0.29) can be obtained from http://www.dna.lth.se/~erics/linux.html. To apply it, download and unzip the patch into the /usr/src subdirectory and type
patch < tcp-syncookies-patch-1. When you run make config (or menuconfig or xconfig), you will see two additions under “Networking Options”. Just compile them into the kernel.
Other methods of protection have been suggested on various Internet forums, including creative firewalls that establish the TCP connection and then pass it on. Several companies are marketing commercial products based on these ideas. These solutions are not necessary for Linux users. Network solutions such as those are for users who don't have the option of compiling a fixed kernel.
The Internet is undergoing a massive scaling, and as a result, it is no longer possible to identify a given network administrator. While the Internet protocols were designed for unreliable networks, they were not designed for untrusted networks.
Although the SYN attack has proven very effective in denying service to important servers, the problem is well under control in the Linux world. The combination of a larger queue and the random drop technique makes your Linux-based system relatively immune to this attack.
Douglas L. Stewart works for Pencom Systems Administration and graduated from the University of Mississippi in December. Douglas can be reached via e-mail at douglas@pobox.com.
P. Tobin Maginnis is an Associate Professor of Computer Science at the University of Mississippi.
Thomas Simpson is a graduate student in Computer Science at the University of Mississippi.


{kind=link}
{kind=link}
{kind=link}