
Parallel Computing Using Linux
Parallel computing involves the design of a computing system that uses more than one processor to solve a single problem. For example, if two arrays with ten elements each must be added, two processors can be used to compute the results. One processor computes the sum of the first five elements and the second processor computes the sum of the second five elements. After the computation, the results from one processor must be communicated to the other processor. Before starting the computation, both processors agree to work on independent sub-problems. Each processor works on a sub-problem and communicates when the solution is available. Theoretically, a two-processor computer should add the array of numbers twice as fast as a single-processor computer. In practice, there is overhead and the benefits of using more processors decrease for larger processor configurations.
Obtaining a Unix workstation for the cost of a PC has been one of the benefits of using Linux. This idea has been carried a step further by linking together a number of Linux PCs. Several research projects are underway to link PCs using high performance networks. High speed networking is a hot topic and there are a number of projects using Linux to develop a low latency and high bandwidth parallel machine. (One URL is http://yara.ecn.purdue.edu/~pplinux.)
Currently, there is not much high level support for shared memory programming under SMP Linux. The basic Linux mechanisms for sharing memory across processors are available. They include the System V Inter-Processor Communication system calls and a thread library. But, it will be some time before a parallel C or C++ compiler will be available for Linux. Parallel programming can still be done on an SMP Linux machine or on a cluster of Linux PCs using message passing.
Parallel computing is advantageous in that it makes it possible to obtain the solution to a problem faster. Scientific applications are already using parallel computation as a method for solving problems. Parallel computers are routinely used in computationally intensive applications such as climate modeling, finite element analysis and digital signal processing. New commercial applications which process large amounts of data in sophisticated ways are driving the development of faster computers. These applications include video conferencing, data mining and advanced graphics. The integration of parallel computation, multimedia technology and high performance networking has led to the development of video servers. A video server must be capable of rapidly encoding and decoding megabytes of data while simultaneously handling hundreds of requests. While commercial parallel applications are gaining popularity, scientific applications will remain important users of parallel computers. Both application types are merging as scientific and engineering applications use large amounts of data and commercial applications perform more sophisticated operations.
Parallel computing is a broad topic and this article will focus on how Linux can be used to implement a parallel application. We will look at two models of parallel programming: message passing and shared memory constructs.
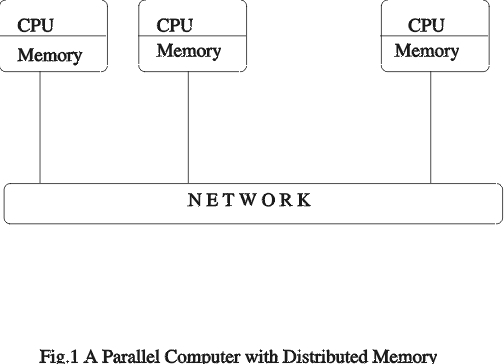
Conceptually, the idea behind message passing is simple—multiple processors of a parallel computer run the same or different programs, each with private data. Data is exchanged between processors when needed. A message is transmitted by a sender processor to a receiver processor. One processor can be either a sender or a receiver processor at any time. The sender processor can either wait for an acknowledgement after sending or it can continue execution. The receiver processor checks a message buffer to retrieve a message. If no message is present, the processor can continue execution and try again later or wait until a message is received. Multiple sends and receives can occur simultaneously in a parallel computer. All processors within the parallel computer must be inter-connected by a network (Figure 1).
Figure 1. A Parallel Computer with Distributed Memory
All processors can exchange data with all other processors. The routing of messages is handled by the operating system. The message-passing model can be used on a network of workstations or within a tightly coupled group of processors with a distributed memory. The number of hops between processors can vary depending on the type of inter-connection network.
Message passing between processors is achieved by using a communication protocol. Depending on the communication protocol used, the send routine usually accepts a destination processor ID, a message type, the start address for the message buffer and the number of bytes to be transmitted. The receive routine can receive a message from any processor or from a particular processor. The message can be of any particular type.
Most communication protocols maintain the order in which messages are sent between a pair of processors. For example, if processor 0, sends a message of type a followed by a message of type b to processor 1, then when processor 1 issues a receive from processor 0 for a generic message type, the message of type a will be received first. However, in a multi-processor system, if a processor issues a receive from any processor, there is no guarantee of the order of messages received from the sending processors. The order in which messages are transported depends on the router and the traffic on the network. To maintain the order of messages sent, the safest way is to use the source processor number and message type.
Message passing has been used successfully to implement many parallel applications. But a disadvantage of message-passing is the added programming required. Adding message-passing code to a large program requires considerable time. A domain decomposition technique must be chosen. Data for the program must be divided such that there is minimal overlap between processors, the load across all processors is balanced and each processor can independently solve a sub-problem. For regular data structures, the domain decomposition is fairly straightforward, but for irregular grids, dividing the problem so that the load is balanced across all processors is not trivial.
Another disadvantage of message passing is the possibility of deadlock. It is very easy to hang a parallel computer by misplacing a call to the send or receive routines. So, while message passing is conceptually simple, it has not been adopted fully by the scientific or commercial communities.
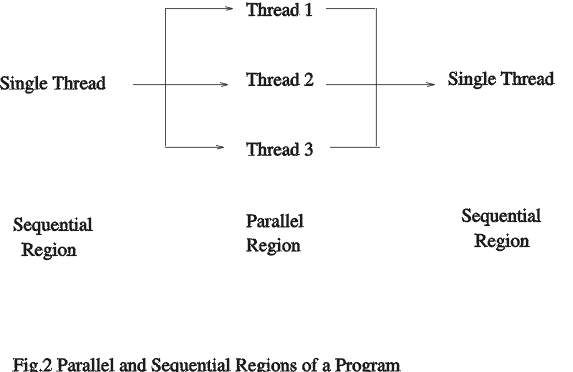
Another approach to parallel programming is the use of shared memory parallel language constructs. The idea behind this scheme is to identify the parallel and sequential regions of a program (Figure 2). The sequential region of a program is run on a single processor while the parallel region is executed on multiple processors. A parallel region consists of multiple threads which can run concurrently.
Figure 2. Parallel and Sequential Regions of a Program
For some programs, identifying parallel and sequential regions may be a trivial task, but for other programs it may involve modifying the sequential program to create parallel regions. The easiest approach is to rely on the compiler to determine parallel regions. This is the automatic parallelization approach which usually gives poor results. Most compilers are conservative when introducing parallelism and will not parallelize code if there is any ambiguity. For example, if elements of an array x are accessed through an index array, e.g., x(index(i)), in a loop, the loop will not be parallelized since the compiler cannot know if the elements of array x will be accessed independently in the loop.
The time-consuming part of any program is usually spent in executing loops. Parallel regions are created for a loop to speed up the execution of a loop. For the compiler to build a parallel region from a loop, the private and shared data variables of the loop must be identified. The example below is for the Silicon Graphics Challenge machine, but the concepts are similar for other shared-memory machines such as the Digital Alpha, IBM PC or Cray J90. Shared-memory constructs are placed before and after the loop.
#pragma parallel
#pragma shared (a,b,c)
#pragma local (i)
#pragma pfor iterate (i=0;100;1)
for (i = 0; i < 100; i++) {
a(i) = b(i) * c(i)
}
#pragma one processor
The code before the first pragma statement and after the last pragma statement is executed on a single processor. The code in the loop is executed in parallel using multiple threads. The number of threads used is based on an environment variable. Identifying shared and private variables is easy for simple loops, but for a complex loop with function calls and dependencies it can be a tedious job.
Programming using shared-memory constructs can be simpler than message passing. A parallel version of a program using shared-memory constructs can be developed more rapidly than a message-passing version. While the gain in productivity may be appealing, the increase in performance depends on the sophistication of the compiler. A shared-memory compiler for parallel programs must generate code for thread creation, thread synchronization and access to shared data. In comparison, the compiler for message-passing is simpler. It consists of the base compiler with a communication library. While no one can predict better performance using shared-memory constructs or message-passing, the message-passing model offers more scope for optimization. Data collection and distribution algorithms can be optimized for a particular application. Domain decomposition can be performed based on communication patterns in the code.
Another advantage of message passing is portability. A message-passing program written using a standard communication protocol can be ported from a network of PCs to a massively parallel supercomputer without major changes. Message passing can also be used on a network of heterogenous machines.
Each vendor of a shared memory compiler has chosen a different syntax for compiler directives. Therefore, code parallelized using directives is usually restricted to a particular compiler.
Parallel Virtual Machine (PVM) is currently the most popular communication protocol for implementing distributed and parallel applications. It was initially released in 1991 by the Oak Ridge National Laboratory and the University of Tennessee and is being used in computational applications around the world. PVM is an on-going project and is freely distributed. The PVM software provides a framework to develop parallel programs on a network of heterogenous machines. PVM handles message routing, data conversion and task scheduling. An application is written as a collection of co-operating tasks. Each task accesses PVM resources through a collection of library routines. These routines are used to initiate tasks, terminate tasks, send and receive messages and synchronize between tasks. The library of PVM interface routines is one part of the PVM system. The second part of the system is the PVM daemon, which runs on every machine participating in the network for an application and which handles communication between tasks.
PVM can use streams or datagram protocols (TCP or UDP) to transmit messages. Normally, TCP is used for communication within a single machine, and UDP is used for communication between daemons on separate machines. UDP is a connectionless protocol which does not perform error handling. Therefore, when UDP is used for communication, PVM uses a stop-and-wait approach for every packet. Packets are sent one at a time with an acknowledgement for each packet. This scheme gives poor bandwidth on a system with a high latency. An alternative approach is to use TCP directly between tasks bypassing the daemon (Figure 3).
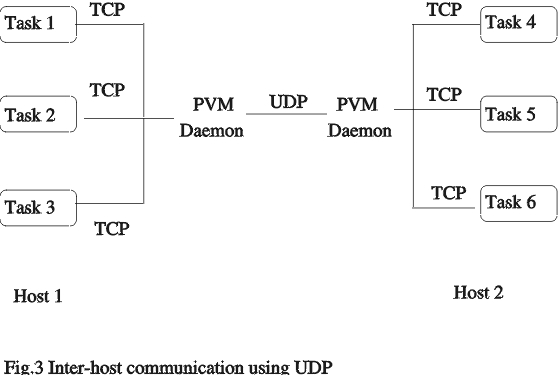
Figure 3. Inter-host communication using UDP
TCP is a reliable transport protocol and does not require error checking after transmitting a packet. The overhead for using TCP is higher than UDP. A separate socket address is required for every connection and additional system calls are used. So, while TCP gives better performance, it is not scalable.
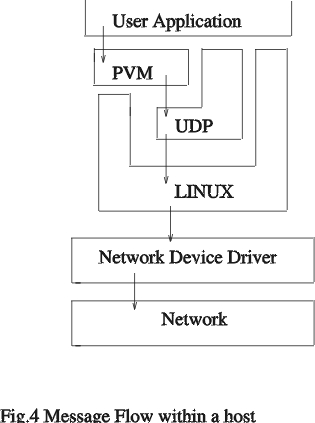
Figure 4. Message Flow within a Host
A number of steps must be completed to send a message from host 1 to host 2 (Figure 4). In the first step, a message buffer is initialized on host 1. Second, the message data is packed using the PVM pack routines. Finally, the message is labelled with a message tag and sent to host 2. To receive a message, host 2 issues a PVM call with a message tag and a host ID. Optionally, a wildcard message type or host ID can be used. Host 2 must then unpack the message in the order it was packed at host 1.
Experimental PVM implementations using threads and ATM (asynchronous transfer mode) have been developed to obtain a higher bandwidth and lower latency. While the use of PVM is widespread, the Message Passing Interface (MPI) standard is gaining popularity.
At the Supercomputing '92 conference, a committee, later known as the MPI forum, was formed to develop a message-passing standard. Prior to the development of MPI, each parallel computer vendor developed a custom communication protocol. The variety of communication protocols made porting code between parallel machines tedious. In 1994, the first version of MPI was released. The advantages of using MPI are:
It is a standard and should make porting among machines easy.
Vendors are responsible for developing efficient implementations of the MPI library.
Multiple implementations of MPI are freely available.
One of the problems with using PVM is that vendors such as Digital, Cray and Silicon Graphics developed optimized versions of PVM which were not freely available. The custom versions of PVM often did not include all the library routines of the PVM system distributed by Oak Ridge, and they sometimes included non-standard routines for better performance. Despite the problems mentioned, PVM is easy to use and developing a new parallel application takes little effort. Converting a PVM application to one using MPI is not a difficult task.
How do you go about parallelizing a program? The first step is to determine which section of the code is consuming the most time. This can be done using a profile program such as prof. Focus on parallelizing a section of code or a group of functions instead of an entire program. Sometimes, this may mean also parallelizing the startup and termination code of a program to distribute and collect data. The idea is to limit the scope of parallelism to a manageable task and add parallelism incrementally.
Run with two, four and eight processors to determine scalability. You can expect the improvement in performance to diminish as you use more processors. The measure of parallel performance often used is speed up. It is the ratio of the time taken to solve a problem using the best sequential algorithm versus the time to solve a problem using a parallel algorithm. If you use four processors and obtain a speedup of more than four, the reason is often due to better cache performance and not a superior parallel algorithm. When the problem size is small, you can expect a higher cache hit rate and a correspondingly lower execution time. Superlinear speedup is looked upon skeptically since it implies more than 100% efficiency.
While you may obtain good speedup, the results from the parallel program should be similar to the results from the sequential algorithm. You can expect slight differences in precision when heterogenous hosts are used. The degree of difference in results will depend on the number of processors used and the type of processors.
The most efficient algorithm is the one with the least communication overhead. Most of the communication overhead occurs in sending and receiving data between the master and slaves and cannot be avoided. Different algorithms to distribute and collect data can be used. An efficient topology which minimizes the number of communication hops between processors can be adopted. When the number of hops between processors is large, the communication overhead will increase. If a large communication overhead is unavoidable, then computation and communication can be overlapped. This may be possible depending on the problem.
If you are looking for a modest improvement in performance of your application, it is possible to use a cluster of PCs or an SMP (symmetric multiprocessing) machine. But, most applications do not see a dramatic improvement in performance after parallelization. This is true for a cluster of PCs, since the bandwidth and latency are still relatively high compared to the clock speed of processors. For an existing network, there is no additional hardware required and the software to run a parallel application is free. The only effort required is to modify code. Some examples of where parallelism is applicable are sorting a long list, matrix multiplication and pattern recognition.
Manu Konchady (manu@geo.gsfc.nasa.gov) is a graduate student at George Mason University and works at Goddard Space Flight Center. He enjoys flying kites and playing with his 2-year-old daughter.


{kind=link}
{kind=link}
{kind=link}