
New Projects - Fresh from the Labs
If you're looking to improve your mental faculties, especially in the area of memory, check out this project. According to the Web site:
Brain Workshop is a free open-source version of the dual n-back brain training exercise.
...A recent study published in PNAS, an important scientific journal, shows that a particular memory task called dual n-back may actually improve working memory (short-term memory) and fluid intelligence.
...Brain Workshop implements this task. The dual n-back task involves remembering a sequence of spoken letters and a sequence of positions of a square at the same time, and identifying when a letter or position matches the one that appeared in trials earlier.

Anatomy students will be chuffed with this brain diagram in the menu background.
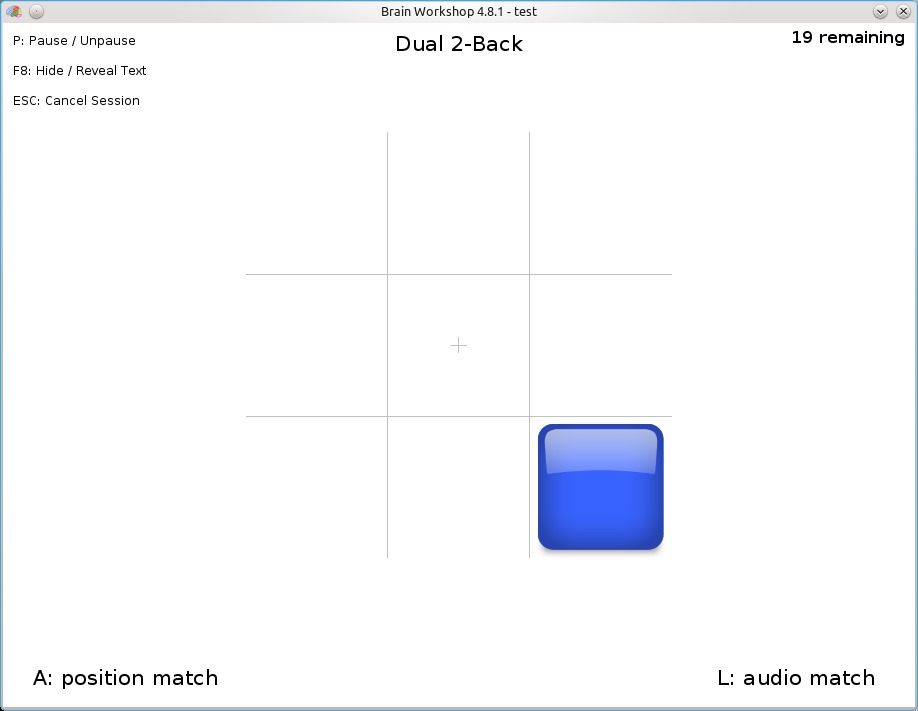
The main playing mode involves remembering letters and positions, two turns back.

Some of the advanced playing modes of Brain Workshop include multiple audio streams, images, arithmetic and more.
Installation
Although running Brain Workshop isn't particularly difficult, installing another external program, AVBin 7, is recommended.
Head to the project Web site, click the Download link, and click the link, “Source Distribution for Linux”. This page contains instructions for both Mac OS X and Linux. Scroll down the page for the Linux instructions. The only other real requirement mentioned here is Python 2.5, although most modern distros likely have this pre-installed.
As I mentioned above, the instructions say that you should install AVBin 7. Although this is optional, it will give you musical cues that are rather satisfying, so I recommend doing so. Luckily for me, the Webmaster has been good enough to provide detailed instructions for AVBin's installation, as well as links to both 32- and 64-bit versions.
Once the prerequisites are out of the way, grab the latest tarball and extract it. From here, the Webmaster again has done the work, so I'm quoting the next step verbatim: “Open a terminal, enter the brainworkshop directory and type python brainworkshop.pyw to launch Brain Workshop. You also may enable execute permissions on brainworkshop.pyw, if you'd like to launch it, by double-clicking.”
Usage
Upon entering the program, you'll be greeted with a menu and a fabulous background diagram of an anatomical brain. I could explore a number of options at this point, but for now, let's jump right into the game.
Press the spacebar, and the level that's about to start appears, most likely called Dual 2-Back. Here you can alter the game mode if you know what you're doing. Press the spacebar a second time, and the level actually starts.
Now strap yourself in, because this game is much more grueling than it first appears. Assuming you have the game set to its defaults, two stimuli will be coming at you: positions and audio. The former appears in the guise of a blue square, appearing randomly in any of the nine squares. The latter takes place as letters, spoken out loud by a female voice that just happens to sound like the one used on almost all computer systems in every futuristic sci-fi movie ever made.
As this is happening, you control the game with only two keys: A and L. Let go of the mouse, and let your left hand rest on A and your right hand on L. Now, I'll explain how the game actually works.
Each level has a series of three-second Trials. The first Trial will have the square appear in one of the boxes in tandem with a spoken letter. The second Trial will have the square in another box with another spoken letter. These first two Trials don't require you to do anything, but instead provide the information for the following Trials.
Given this default mode is “2-Back”, the information provided in the first Trial is the basis for testing against in the third Trial. The information in the second Trial is for testing against the fourth, and so on. Now, let's examine the third Trial and onward, where the actual game begins.
Was the position of the blue block the same as the first Trial? If so, press the A key. Was the letter the same? If so, press L. Each Trial may have a combination of both position and letter, or just the one, or even no matches.
As you can see, this game mode is all about remembering what happened two Trials ago. This sounds easy, but each stimulus acts independently of the other, so most of the time, the letter and position won't land in the same place. This means your memory has to split in two different directions—multitasking in memory. Does that sound tricky? Believe me, it is. I'd even go so far as to call it intense.
Chances are you'll get a bad score, but that's okay. The manual recommends starting with a game of 1-Back, but I thought I'd start you off with the harder mode because I'm mean like that! If you want to alter the difficulty, prior to starting a level is a list of options at the top left where you can increase/decrease the N-Back number (try 1 for instance), the number of trials, change the speed and so on.
That's all I have space for here, but if you want more information, check out the game's documentation available at the main menu. I recommend looking into the game's more-advanced features, such as color and image testing, arithmetic and more.
All in all, this is one of the most grueling brain exercises I've come across, and anyone looking to improve specific areas of memory definitely should try Brain Workshop.
I've highlighted a few language programs in this column, but so far they've been for Japanese, Chinese and German—all languages spoken by large populations. So a dictionary program for a language like Serbian jumped right out at me. According to the SourceForge page: “Serbian Dictionary is a bidirectional Serbian-English dictionary. It currently contains only a command-line interface. It supports only *nix-based operating systems at this moment. Tested on Linux, *BSD and Cygwin.”
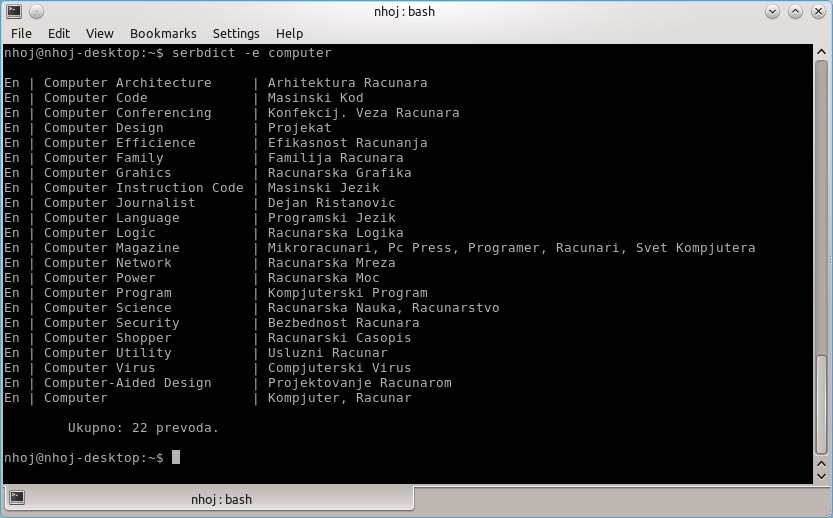
SerbDict lets you translate words from English to Serbian and vice versa.
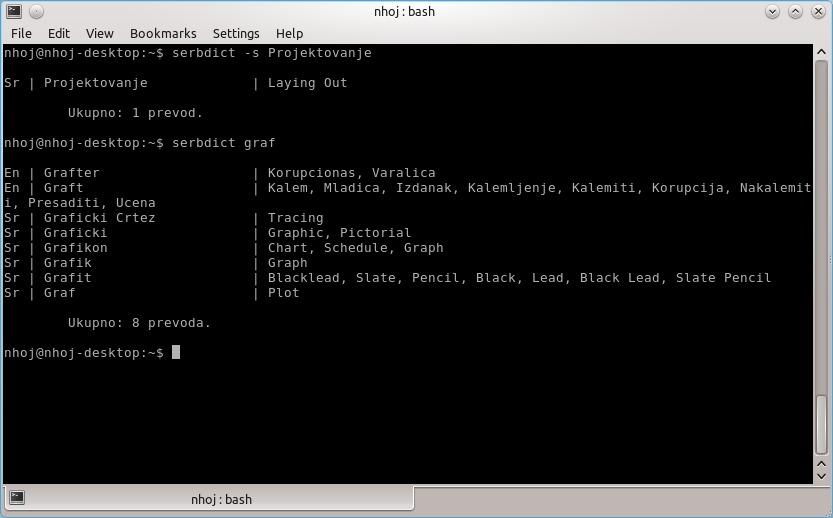
Here's a search involving Serbian to English and a search involving both languages simultaneously.
Installation
I found only a source tarball at the Web site at the time of this writing, although the installation still is quite easy. Also, the home page is in Serbian, and I had to use a translator (Chrome's translator handled this well). The download page at least is called “Download”, so that was easy. The download page takes you to a basic SourceForge file list, which should be localized into your own language.
Grab the latest tarball, extract it, and open a terminal in the new folder. Compiling this program is easy, just enter:
$ make
If your distro uses sudo, enter:
$ sudo make install
And, if your distro uses root, enter:
$ su # make install
Usage
Using SerbDict also is very easy (at least, once I'd translated the documentation). If you want to translate something from English into Serbian, enter:
$ serbdict -e word
If you want to translate a Serbian word into English, enter:
$ serbdict -s word
SerbDict appears to query a database of words and terms, and it outputs everything, including extensions of your queried word. For instance, querying the word “entire” gave me not only translations for entire, but also for entirely and entirety.
If you speak Serbian (and I don't), there's a man page with instructions on how to extend the program, available with the command:
$ man serbdict
One thing I managed to pick up from the man page is that if you skip the -s and -e extensions, any query you make will output any matches in both English and Serbian at the same time.
Below your outputted text will be a message saying, “Ukupno: x prevoda”. After querying those words, it turns out Ukupno means altogether. And although “prevoda” didn't return any matches, prevod means rendering, translation or version, so I'm guessing prevoda would be some kind of plural form of these words.
Well, that covers Serbian, but if anyone has written a program for a really rare or dying language, send me an e-mail. I'd love to cover it.
You know I love niche projects, but this is the first project I've come across that genuinely made me laugh out loud and exclaim, “I've got to cover that!” To quote the Web site: “ ebook2cw is a command-line program (optional GUI available) that converts a plain text (ISO 8859-1 or UTF-8) e-book to Morse code MP3 or OGG audio files. It works on several platforms, including Windows and Linux.”

Turn e-books into Morse code audio tracks—I'm guessing this is intended for Morse code students.
Installation
Quoting the documentation:
1) Binaries: statically compiled binaries are available at the project Web site, for Linux (i386) and Win32. Those should be suitable for most users.
2) Source: a Makefile is included; it compiles both under Linux and Windows (with MinGW).
Library requirements are mostly minimal, but for the source, you will need the development packages (-dev) installed for the lame and ogg libraries.
If you're running with the source, grab the latest tarball, extract it, and open a terminal in the new folder. Compiling this program is also easy. Again, just enter:
$ make
If your distro uses sudo, enter:
$ sudo make install
If your distro uses root, enter:
$ su # make install
Usage
ebook2cw is a command-line program and using it is fairly simple, although you'll want to keep the man pages at the ready for using something other than the default parameters. The basic syntax is as follows:
$ ebook2cw textfile.txt -o outputfile
Here, the textfile.txt obviously represents whichever text file you want to convert to Morse code. The -o switch is for specifying the output file, followed by the output file's name. Notice I haven't given the output file an extension, such as mp3. ebook2cw does this for you automatically, and I actually recommend against doing so, as the resulting filename becomes rather messy.
I don't have the space to go into detail on ebook2cw's command-line switches, but I can at least highlight a handful that will be the most useful to the majority of users.
If you want to switch from MP3 output to Ogg, use the switch -O (note the uppercase letter).
The sample rate is set by default to 11khz @ 16kbps—perfectly adequate for a series of dots and dashes, but sometimes it's a bit clippy and horrid to listen to. If you want to change the sample rate to 44khz, for instance, use the switch: -s 44100. To change the bitrate, using this combination, set the bitrate at 64kbps: -b 64.
You can work things out from here, but I hope you enjoy the results. Maybe the works of Dickens are even better, slowly spelled out one letter at time? Either way, this project has probably given me the biggest grin since I started this column. I'm sure it'll be very useful—to someone.
Brewing something fresh, innovative or mind-bending? Send e-mail to newprojects@linuxjournal.com.
John Knight is a 26-year-old, drumming- and bass-obsessed maniac, studying Psychology at Edith Cowan University in Western Australia. He usually can be found playing a kick-drum far too much.
