
Speech I/O for Embedded Applications
Speech user interfaces are like the holy grail for computing. We talk to each other to communicate, and sci-fi stories—from HAL in 2001: A Space Odyssey to the ship's computer in Star Trek—point to talking computers as the inevitable future. But, creating speech interfaces that are natural and that people will use has proven to be difficult. Too often speech technology is provided, or even preinstalled (as with Microsoft Windows Speech Recognition), and never used, but there are glimmers of hope. The technology to do “decent” speech recognition and speech synthesis has existed for a while now, and users are trying it out, at least in some application categories.
It feels like the opportunity is ripe for someone to get the speech interface right. Maybe you're the one to invent a speech interface that makes your embedded application as cool and unique as the iPhone touch interface was when it first came out.
In some ways, embedded applications are particularly well suited for speech. An embedded device often is physically small and may not have a rich user interface. Almost by definition, embedded applications are not general-purpose, so it's okay if a speech interface has a limited vocabulary. Speech may be the only user interface provided, or it may augment a display and keyboard.
Mobile phones are one class of embedded applications where speech works as a user interface. Voice dialing (“dial home”) is almost a trivial interface that works very well on phones. If you're driving and want to send a text message, it's difficult (and in many places illegal) to use the phone's soft keyboard to enter the message and its destination. Speech recognition is good enough, and mobile phones are powerful enough computers, that sending text messages by voice is a valid use case people are starting to employ.
In this article, I examine technologies for speech synthesis and recognition and see how they fit with today's embedded devices. As an example application, and in step with the re-discovery of checklists as productivity tools (thanks to Atul Gawande's best-seller The Checklist Manifesto), we'll build a simple vocal checklist that you can use the next time you do surgery, like Dr Gawande (kids don't try this at home).
As with any other user interface, a speech interface has two components: input and output (or recognition and synthesis). The two technologies are closely related, sharing techniques, algorithms and data models. As mentioned, speech has been a very popular computing research topic, and I can't cover all the work here, but I take a quick look at some different approaches, investigate some open-source implementations and settle on input and output packages that seem well suited for embedded applications. You don't have to be a computerized speech expert (I certainly don't claim to be) to speech-enable your embedded application.
Naïvely, you might think “What's so hard about speech synthesis?” You envision a hashmap with English words as the keys and speech utterances as the values. But, it's not that easy. Any nontrivial TTS system needs to be able to understand things like dates and numbers that are embedded in the text and utter them properly. And, as any first-grader can tell you, English is full of words whose pronunciation is context-dependent (should “lead” be pronounced as rhyming with “reed” or “red”?). We also vary the pitch of our voices as we come to the end of a sentence or question, and we pause between clauses and sentences (called the prosody of the speech).
A lot of smart people have thought this over and have come up with a basic architecture for TTS:
A front end to analyze the text, replace dates, numbers and abbreviations with words, and emit a stream of phonemes and prosodic units that describes the utterance.
A back end, or synthesizer, that takes the utterance stream and converts it to sounds.
The front end, sometimes called text normalization, is not an easy problem. It's one of those pattern things that humans do easily and computers have a difficult time mimicking. The algorithms used vary from simple (word substitution) to complex (statistical hidden Markov models). For applications where the text to be spoken is relatively fixed (like our checklist), most TTS systems provide a way of marking up the text to give the normalizer hints about how it should be spoken (and, there is a standard Speech Synthesis Markup Language to do so; see Resources).
A variety of schemes have been developed to build speech synthesizers. The two most popular seem to be formant synthesis and concatenation.
Formant synthesizers can be quite small, because they don't actually store any digitized voice. Instead, they model speech with a set of rules and store time-based parameters for models of each phoneme. The prosodic aspects of speech are relatively easy to introduce into the models, so formant synthesizers are noted for their ability to mimic emotions. They also are noted for sounding “robotic”, but very intelligible. For our chosen application, intelligibility is more important than “naturalness”.
Concatenative synthesizers have a database of speech snippets that are strung together to create the final sound stream. The snippets can be anything from a single phoneme to a complete sentence. They are known for natural-sounding speech, although the technique can produce speech with distracting glitches, which can interfere with intelligibility, particularly at higher speeds. They also are typically larger than formant synthesizers, due to the large database required for a large vocabulary. The database can be minimized if the TTS is for a domain-specific application, but, of course, that limits its usefulness.
In contrast to TTS, there is one dominant algorithm for speech recognition, hidden Markov models (HMMs). If you haven't run into HMMs before, don't expect me to explain the math in detail here, because, frankly, I don't completely understand it. I do understand the idea behind HMMs, and that's more than what you need to know to use an HMM-based recognizer.
If you sample a speech waveform (say every 10ms) and do some fancy math on the resulting waveform that extracts frequency and amplitude components, you can end up with a vector of cepstral coefficients. You then can model connected speech as a series of these cepstral vectors. A Markov model is like a state machine where the probability of a particular state transition is dependent only on the current state. In our case, each state of the Markov model corresponds to a particular vector, and as a Markov model moves probabilistically through its states, a series of cepstral vectors and sounds are generated. A hidden Markov model is one where you can't see the details of the state transitions, you just see the output vectors.
The trick is to create a bunch of these HMMs, each trained to mimic the sounds from a bunch of human-generated speech samples. Again, the math is beyond me here, but the process is to expose a training algorithm to a lot of speech samples for the language desired. As the sea of HMMs is trained, they take on the ability to reproduce the sounds they “hear” in the training samples.
To use the HMMs to recognize speech, we use one last bit of mathematical wizardry. For appropriate sets of HMMs, there are algorithms that, given a waveform (that is hopefully speech), can tell you: 1) which sequences of HMMs might have generated that waveform and 2) the probability for each of those sequences.
So, HMMs won't give us a definitive answer of what words the speech represents, but they'll give us a list from which to choose and tell us which is most likely and by how much. How cool is that?
Many commercial TTS packages are available, but they don't concern us here. On the open-source side, there are still many candidates, with a few that seem more popular:
eSpeak is the TTS package that comes with Ubuntu and several other Linux distros. It is of the formant flavor and, therefore, small (~1.4MB), with the usual robotic formant voice. The eSpeak normalizer also can be used with a diphone synthesizer (MBROLA) if desired, but we won't take advantage of that for the checklist example here.
Flite is the embedded version of Festival, which is an open-source speech synthesis package originating at University of Edinburgh, with Flite done at Carnegie Mellon University. It is diphone-based concatenative, and as you would expect, it has a more natural voice. CMU also offers a set of scripts and tools for developing new voices, called FestVox.
Most speech recognition packages are commercial software for Windows and Mac OS X. I looked at two open-source speech recognition packages, both from the Sphinx group at Carnegie Mellon:
Sphinx-4 is a speech recognizer and framework that can use multiple recognition approaches, written in Java. It is intended primarily for server applications and for research.
PocketSphinx is a speech recognizer derived from Sphinx and written in C. As such, it is much smaller than Sphinx (but still around 20MB for a moderate vocabulary), and it runs in real time on small processors, even those with no floating-point hardware.
PocketSphinx is the obvious choice between the two implementations, so that's what we'll use here.
In the interest of flexibility and speed, I've chosen a rather high-end embedded platform for the example program. The Genesi LX is a nettop with a rather generous configuration for an embedded device:
Freescale i.MX515 (ARM Cortex-A8 800MHz).
3-D graphics processing unit.
WXGA display support (HDMI).
Multi-format HD video decoder and D1 video encoder.
512MB of RAM.
8GB internal SSD.
10/100Mbit/s Ethernet.
802.11 b/g/n Wi-Fi.
SDHC card reader.
2x USB 2.0 ports.
Audio jacks for headset.
Built-in speaker.

Figure 1. Genesi EFIKA MX Smarttop
On top of all that, there is a version of the Ubuntu 10.10 (Meerkat) distro available to load and run on the system, which makes installation and testing a lot easier. The download for Ubuntu and installation instructions are on the Genesi Web site. Installation from an SD card is straightforward through the U-boot bootloader.
The eSpeak TTS system originally was developed for the Acorn RISC Machine (can you say “full circle”?), comes with Ubuntu and is included in the version for Genesi, so we get a pass there. That may not be true for your embedded system, but the installation procedure for eSpeak is straightforward and is given in the README of the download on the eSpeak site (see Resources). Of course, you'll need to do the install in the context of Scratchbox, or whatever native build environment you're using for your embedded Linux.
To install PocketSphinx, you first need to install sphinxbase, which also is available on the PocketSphinx site. Both are tarballs, and the installation instructions are given in the READMEs. On systems like the Genesi, you can download and use the target to build the package. I did have to set LD_LIBRARY_PATH, so ld could find the libraries:
export LD_LIBRARY_PATH=/usr/local/lib
On smaller embedded systems, you might have to use a cross-compiler or Scratchbox.
We want to create a general-purpose spoken checklist program along the lines of the checklists discussed in Dr Gawande's book. As an example, let's use part of the World Health Organization's Surgical Safety Checklist.
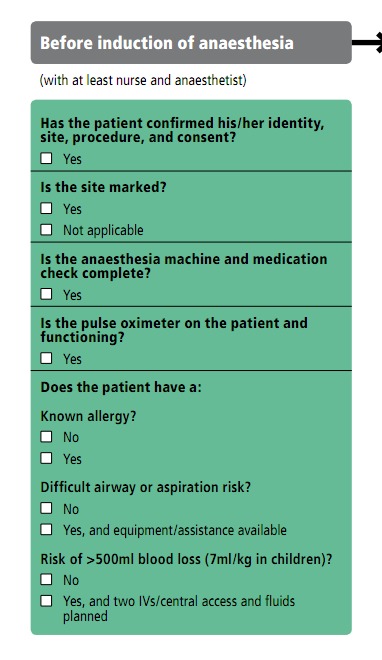
Figure 2. Surgical Safety Checklist, Part I
Let's create a speech checklist program that reads a checklist and listens to a reply for each item. We'll just match the reply with some valid ones now and record it in a file, but this could be a springboard for your own innovative speech user-interface ideas.
PocketSphinx comes with an application called pocketsphinx_continuous that will do basic continuous speech recognition and print the results to stdout, along with a lot of information about how it performed the recognition. We'll create a small C program, atul.c, that uses the libespeak library to speak the checklist items. We will have piped pocketsphinx_continuous to atul, so atul can listen to the replies on its stdin.
The compilation command for atul will vary depending on your development environment. The invocation is:
pocketsphinx_continuous | ./atul SafeSurgery.ckl
Let's keep the application simple by reading checklist items and commands from a text file, whose name we'll pass as an argument to the program. Let's mark commands with a # at the beginning of a line. If the # is followed by a number, let's pause that number of seconds (up to 9). We will record each item and the replies as text to stdout.
The espeak library depends on two development packages you'll need to load into your target development environment. Both are readily available as rpm or deb packages: portaudio-devel and espeak-devel.
The Safe Surgery Checklist file is shown in Listing 1, and Listing 2 shows the source code for atul.c.
Listing 1. SafeSurgery.ckl
This is the Surgical Safety Checklist. # Before induction of anesthesia. # Has the patient confirmed his or her identity, site, procedure and consent? # yes | no Is the site marked? # yes | notapplicable Is the anesthesia machine and medication check complete? # yes Is the pulse oximeter on the patient and functioning? # yes Does the patient have a known allergy? # yes | no Does the patient have a difficult airway or aspiration risk? # no | yes Is there a risk of more than 500 milliliters of blood loss? # no | yes Thank you, that completes this portion of the checklist.
Listing 2. atul.c
/*
atul - a simple speech checklist for embedded systems
*/
#include <string.h>
#include <malloc.h>
#include <stdio.h>
#include <speak_lib.h>
espeak_POSITION_TYPE position_type;
espeak_AUDIO_OUTPUT output;
char *path=NULL;
int BuffLen=500, Options=0;
void* user_data;
t_espeak_callback *SynthCallback;
espeak_PARAMETER Parm;
FILE *ckfp; /* Checklist file pointer */
char *ckBuf; /* Checklist item buffer */
char *mtchBuf; /* Checklist expected response buffer */
char *srBuf; /* Speech rec buffer */
char *reply; /* Trimmed reply */
int bsize=100; /* buffer length for all buffers */
int next; /* flag - true if should go to next prompt */
char Voice[] = {"default"};
unsigned int size, position=0, end_position=0,
flags=espeakCHARS_AUTO|espeakENDPAUSE, *unique_identifier;
void recordreply(){
/* read lines from stdin, which are piped in
* from pocketsphinx_continuous.
* Valid responses look like:
* <9 digits>: reply (7 or 8 digits)
* Returns a trimmed reply as char *reply
* no spaces in return
*/
int i, j;
while (!feof(stdin)) {
getline (&srBuf, &bsize, stdin);
if (srBuf[9]!= ':') continue;
j=0;
for (i=0; i<strlen(srBuf); i++) {
if (isdigit(srBuf[i])) continue;
if (srBuf[i]=='-') continue;
if (srBuf[i]==':') continue;
if (isspace(srBuf[i])) continue;
if (srBuf[i]=='(') continue;
if (srBuf[i]==')') continue;
reply[j++] = srBuf[i];
}
reply[j] = '\0';
break;
}
}
int checkreply(){
/* returns true if reply matches
* false if no match (try again)
*/
char *tryagain="Please answer ";
char *ans, *spBuf;
/* if template blank, just sleep 2 sec */
if (strlen(mtchBuf)==2) {
sleep(2);
return(1);
}
/* see if reply matches template */
recordreply();
printf("reply: '%s'\n", reply);
if (strstr(mtchBuf, reply)==NULL){
/* no match - tell user what we're looking for */
spBuf = (char *) malloc (bsize+1);
strcpy(spBuf, tryagain);
if (ans=strtok(mtchBuf+2, "|")){
strcat(spBuf, ans);
}
ans = strtok(NULL, "|");
while (ans!=NULL){
strcat(spBuf, " or ");
strcat(spBuf, ans);
ans = strtok(NULL, "|");
}
espeak_Synth( spBuf, size, position,
position_type, end_position, flags,
unique_identifier, user_data );
espeak_Synchronize( );
free(spBuf);
return(0); /* repeat last prompt */
}else return(1); /* go to next prompt */
}
int main(int argc, char* argv[] )
{
printf("atul started.\n");
/* allocate needed buffers */
ckBuf = (char *) malloc (bsize+1);
srBuf = (char *) malloc (bsize+1);
mtchBuf = (char *) malloc (bsize+1);
reply = (char *) malloc (bsize+1);
/* open the checklist file */
if (argc < 2) {
printf("Usage: atul <checklist filename>\n",
argc);
return 0;
}
ckfp = fopen(argv[1], "r");
if (ckfp == NULL) {
printf("Unable to open checklist file: %s\n",
argv[1]);
return 0;
}
/* Initialize the TTS subsystem */
output = AUDIO_OUTPUT_PLAYBACK;
espeak_Initialize(output, BuffLen, path, Options);
espeak_SetVoiceByName(Voice);
/* Initialize speech recognition
* piped in from pocketsphinx_continuous */
while (!feof(stdin)) {
getline (&srBuf, &bsize, stdin);
if (strncmp(srBuf, "READY...", 8)==0) break;
}
/* Go through the checklist */
next = 1; /* advance to next prompt */
while (!feof(ckfp)) {
if (next) {
getline (&ckBuf, &bsize, ckfp);
getline (&mtchBuf, &bsize, ckfp);
}
size = strlen(ckBuf)+1;
espeak_Synth( ckBuf, size, position,
position_type, end_position, flags,
unique_identifier, user_data );
espeak_Synchronize( );
fputs(ckBuf, stdout);
next = checkreply();
}
fclose(ckfp);
free(ckBuf);
free(srBuf);
free(mtchBuf);
return 0;
}
The code isn't very complex, although in retrospect, it might have been clearer in Python or some other language that is better than C at string manipulation. The main routine initializes the TTS subsystem and makes sure that phoenix_continuous is ready to catch replies and forward them to us. It then just cycles through the checklist file, reading prompts and comparing the replies with the acceptable ones it finds in the checklist file. If it doesn't find a match, it tells the user what it's looking for and asks again. One thing to note, the string trimming routine in recordreply() throws out all spaces, so if your checklist is looking for a multiword response, be sure to concatenate the words in the list (like “notapplicable” in our checklist above). Everything of note is recorded in stdout, which you might want to redirect to a log file.
We've barely scratched the surface of speech user interfaces, even for a checklist application. Depending on your embedded system, you'd have to give the user a way to start and end the checklist app, and ideally you'd have a way of signaling to the user when the app is listening. PocketSphinx prompts with “Listening...” and is supposed to terminate on saying “goodbye” (that doesn't work for me—maybe it's my Texas accent?). The source code for PocketSphinx (labeled continuous.c) comes with the package, so you can experiment with it. There are many, many optimizations you could make to both speech recognition and synthesis, using restricted vocabularies, different voice databases and just tuning the parameters.
And, what about a more general, practical speech user interface for embedded devices? The tools are available—how creative can you be?
Resources
eSpeak: espeak.sourceforge.net/index.html
Carnegie Mellon University's Sphinx Group: cmusphinx.sourceforge.net
Carnegie Mellon's Flite Page: www.speech.cs.cmu.edu/flite
Genesi EFIKA MX: www.genesi-usa.com/products/efika
World Health Organization Safe Surgery Checklist: www.who.int/patientsafety/safesurgery/ss_checklist/en/index.html
Rick Rogers has been a professional embedded developer for more than 30 years. Now specializing in mobile application software, when Rick isn't writing software for a living, he's writing books and magazine articles like this one. He welcomes feedback on this article at portmobileapps@gmail.com.

