
Clonezilla: Build, Clone, Repeat
The practice of cloning is a time-tested standard operating procedure in many IT shops. It can assist in migrations and building test/lab environments, and it enhances system recovery processes. Due to the tremendous utility of cloning, there also is a healthy market of commercial cloning tools, each with their own unique abilities. Unfortunately, most of these commercial tools offer limited support for Linux. Enter Clonezilla, an open-source suite of cloning tools developed by Taiwan's National Center for High-Performance Computing (NCHC) software lab under the GPL that works impeccably with Linux distributions. Clonezilla boasts high-performance cloning, simplified deployment and support for a multitude of system types (Windows, Linux and VMware), all of which make it a worthy competitor to its commercial counterparts.
In this article, I describe two common cloning scenarios where Clonezilla performs serviceably in place of commercial cloning suites. In the first scenario, I install Clonezilla Server Edition (SE) and Diskless Remote Boot Linux (DRBL) on a Linux server for use as a central imaging solution in the enterprise. In the second scenario, I focus on Clonezilla's disaster recovery (DR) abilities using the Live version to create a custom recovery solution for a critical system.
For the first scenario, I have chosen to deploy DRBL and Clonezilla on CentOS 5.5 server, although both programs work on a multitude of distributions. Prior to selecting server hardware, you need to make two decisions. The first is how many networks you want to use with DRBL. It is recommended to run DRBL services on a nonproduction network segment. As a result, DRBL is best run on a server with more than one NIC, specifically where one NIC is connected to your production network and a second NIC is connected to a dedicated cloning network. Clonezilla is scalable, so you can have multiple NICs in a server dedicated to different imaging segments. This is a common network design for test labs and classroom environments. You can use a single NIC with an alias for your imaging network, but you'll be running two IPs on one card, which is not recommended. Let's keep deployment simple by using two NICs in the server, with one plugged in to the production and the second plugged in to the imaging network.
After deciding on your network configuration, you need to decide where you want to store the cloned images. If you want to use your DRBL/Clonezilla server for storage, you may need to plan for a larger hard drive or storage array to accommodate the size of your image library. You also may have an existing large-capacity high-speed storage network, like a SAN, that performs better over the network when cloning multiple images at once. In that case, you can use remote mountpoints with your networked storage to house the images. I've kept it simple here and used the directly attached hard drive in my server, as it has enough room for everything.
With the hardware in place, install CentOS using an installation image from one of the distribution's mirrors. Select whatever install options you require, but it is recommended that you disable any firewalls and SELinux. Once the CentOS installation is complete, download and install the DRBL rpm package from the project's SourceForge site. When the rpm completes installation, open a terminal console and run the following command to finalize the DRBL install and create the PXE image client files:
/opt/drbl/sbin/drblsrv -i
After entering the above command, you are presented with a series of prompts. For our purposes, you can accept all of the defaults, but make sure to read them to understand what is occurring during the DRBL installation. Because I used the i386 version of the CentOS distribution, I had to upgrade to the i686 version before DRBL would begin the installation. When this process is complete, enter the following command to configure the DRBL server:
/opt/drbl/sbin/drblpush -i
This launches the DRBL configuration script in interactive mode. As with the drblsrv script, you can accept most of the default options. When prompted to configure the network, assign eth0 as the public Internet (WAN) connection. After that, any other active NICs found by the script are placed on their own DRBL segment. You then are prompted for the initial number of the IP address you want to use. This is the starting number your DRBL clients will receive in the last octet of their IP address from DHCP. At the next prompt, enter the number of DRBL clients you want to use with this server. This number will increment the IP addresses used on the server. For example, if you entered 100 as the first number and 12 as the second, you can use up to 12 client machines assigned with the IP addresses 192.168.162.100–192.168.162.111 with your imaging server. When all prompts have been answered, you are presented with a visual representation of your DRBL network environment (Figure 1). Press Enter to continue. When prompted for the DRBL and Clonezilla modes, select the defaults of Full DRBL and Full Clonezilla mode. It then will ask you for the directory to store images. This directory can be local or remote storage. Based on our earlier decision, leave the default as a local folder named /home/partimag. After these prompts, you can accept the rest of the defaults. When you have answered all the prompts, the script will create instances of the DRBL client (based on your distro) for each IP address allotted from the configuration. DRBL configuration is now complete.
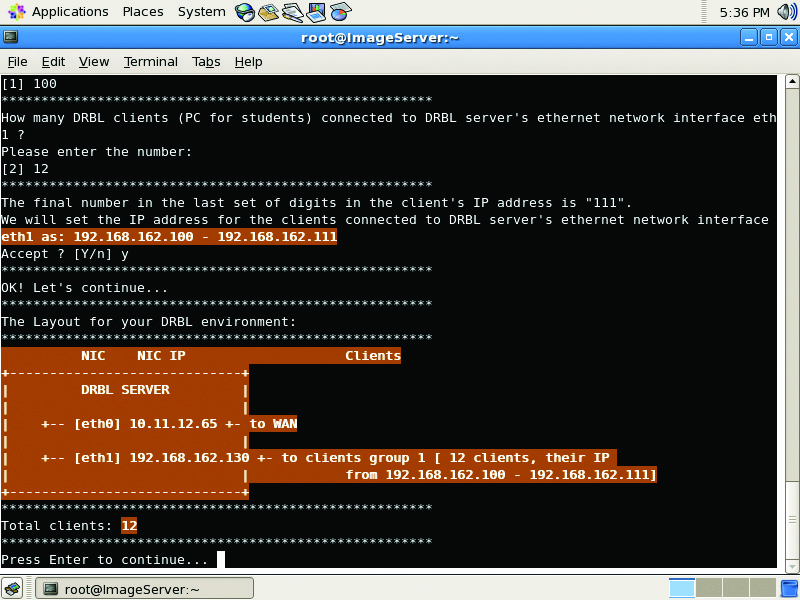
Figure 1. drblpush Script Displaying the Network Design
Next, run the following command from a console to launch the Clonezilla setup script:
/opt/drbl/sbin/dcs
Select All Clients from the first screen. Set the mode to Clonezilla-start and then Beginner mode. On the resulting screen, choose select-in-client Save/Restore in the Client. This gives you the flexibility to select either operation at the client. You can accept the rest of the defaults until the script exits. You may want to experiment with these options further, as they can help streamline the cloning process. To make a configuration change to your DRBL or Clonezilla server, simply rerun the drblsrv, drblpush or dcs script again. If you make a change that involves the PXE setup, it always is a good idea to blow away any existing PXE image profiles (a prompt in the drblpush script) to make sure your new settings override any previous ones.
With the server in place, let's move on to creating and cloning the base desktop image. Many things must be taken into account when building the base image. First, partition/use only the minimum amount of storage space necessary to fit on the smallest drive to which you plan to clone. Clonezilla supports restoring a cloned image to a larger drive, but it will not restore to a smaller drive than the one found in the image. If your target disk is larger than the image being restored, you can use free partition tools like GParted or PartedMagic to expand the restored OS to use some or all of the free space on the local disk. GParted is nice because it can be added to a PXE server or run from a live CD (Figure 2).
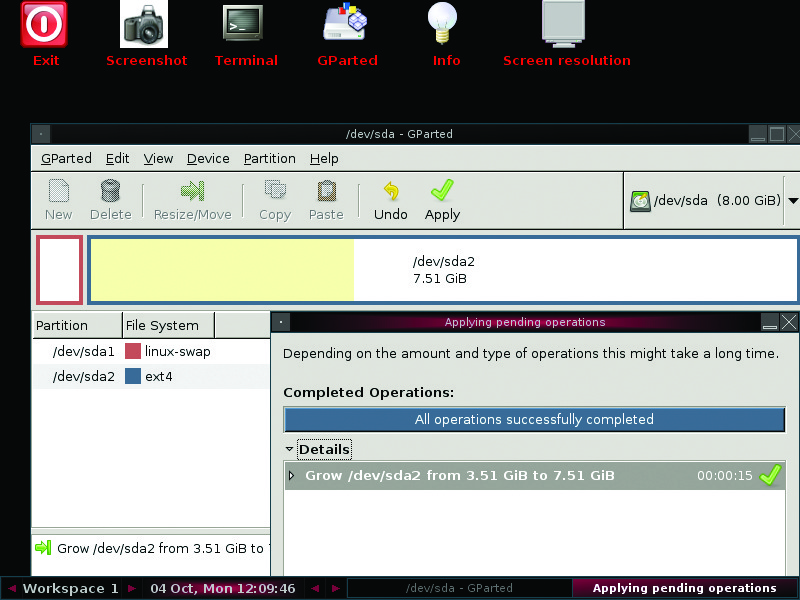
Figure 2. GParted in Action
The second caveat is to use like-to-like hardware between the base image and the target machines as much as possible. Differences in hardware from the base to target machines can cause a multitude of issues when cloning. Some items, such as memory and hard drives, are not critical, but switching system components, such as motherboards and processors, can cause a host of issues. For most people, this is not a problem, as many administrators already work highly standardized environments.
Third and last, build your OS on a pristine machine or “bare metal”. If experience has taught me anything, it is to start with a clean slate. After installing the desktop OS on your base image, install only those programs absolutely necessary to your deployment, and avoid installing any antivirus, backup agents or desktop management clients before cloning. Anything that requires a unique identifier should be left off the base image. After installing all required software, make sure the machine shuts down cleanly. For my base image, I have built a vanilla installation of openSUSE with OpenOffice.org for redeployment on my target machines.
After preparing the OS on your base machine and powering it down, you need to make it talk to the DRBL server. You can accomplish this by using the Pre-Boot eXecution Environment (PXE, pronounced “pixie”). PXE provides a shell for a thin OS that runs in local memory and provides direct access to local data outside the installed OS—a prerequisite for most cloning programs. If not already enabled on your target hardware, PXE can be enabled on most motherboards in the BIOS. Once enabled, connect the base machine to the DRBL network segment, and boot from it as a source by either setting it in the boot order or using a boot menu (usually accessed by pressing a function key prior to the bootloader screen).
Upon booting from PXE, the client should pick up an address from the DRBL server (also running DHCP) and present you with a GRUB-loader screen (Figure 3). Leave the default selection of “Clonezilla: choose save or restore later” to load Clonezilla into memory via TFTP. Once Clonezilla has loaded, select the following options to capture your base image on the server: device-image, Beginner mode and savedisk. Provide a name for the image and choose the local disk as the source. When prompted, confirm you want to run the script and capture the image. Clonezilla will launch the appropriate cloning program (partclone, partimage, ntfsclone, dd) and begin capturing the disk to image (Figure 4). When the image capture has been completed, power down the base machine.
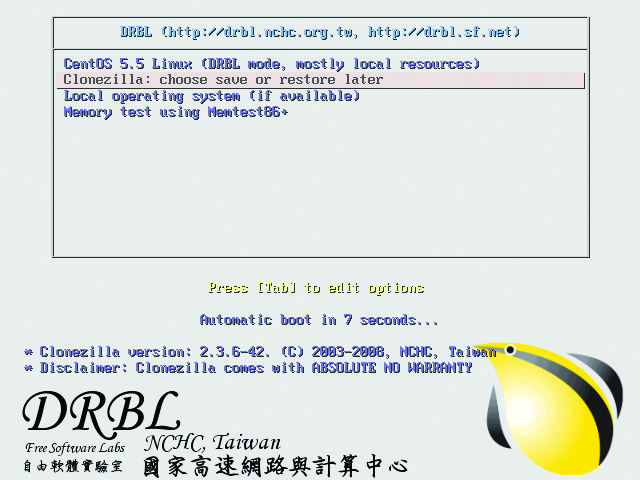
Figure 3. The GRUB screen pushed by the DRBL server via PXE.
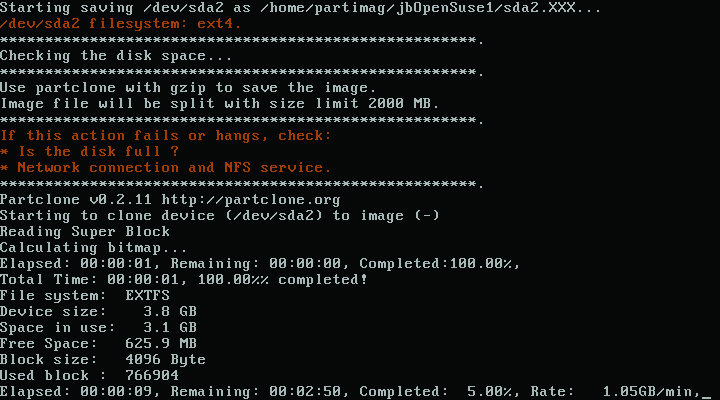
Figure 4. Capturing the Disk to Image
With your image stored on the server, you can simultaneously clone up to 12 end systems. Restoring a cloned image to a new machine via PXE follows the same procedure as capturing it, with the exception that you need to select the restore-disk option, and if you store multiple images on the server, you need to specify which image to restore. Depending on the OS contained in your image, further steps may be needed after the restore. At a bare minimum, you will want to change each newly cloned machine's hostname. If you are restoring a Microsoft OS, you need to change the Security Identifier (SID) so as not to cause problems in your domain. You can avoid this issue with Windows XP clients and higher by using the sysprep utility pre-clone.
As long as everything went smoothly, you now have a working DRBL and Clonezilla SE server that you can use to mass clone devices on your network as often as needed.
For the second scenario, let's use the Live version of Clonezilla to create a recovery CD/DVD for a critical system. This is handy for near-line backups and/or off-site storage, but it also can double as a method for mass cloning systems if you lack the network infrastructure to use DRBL and PXE. If you are an OEM builder, you can use Clonezilla in this way to create recovery CDs for inclusion with your systems, like the big PC manufacturers have done for years. Recovery discs also can supplement change management processes—for example, if you have a server that requires high availability that is in need of major software upgrade. By capturing the server in its current state prior to the upgrade, you have a viable rollback plan should the upgrade go awry.
The recovery disc creation process includes two parts: taking a backup image of the machine and then creating the CD itself. Many of the same caveats apply to capturing an image using the Live version of Clonezilla as they did in the earlier scenario with two major differences. One, the system disk or partition to be restored must fit on a single CD or DVD along with all of the files needed to create the disc. Using a dual-layer DVD means you tap out at approximately 8.54GB. This is not a huge problem because, as mentioned earlier, you can expand the restored partition using GParted or other tools post-clone. Two, unlike a base system that may be restored multiple times over, you will want to configure this host as much as possible to minimize recovery time. If you suffer total server loss due to a catastrophic event and are forced to use a recovery disc, you do not want to spend additional time editing configurations. This works well for static servers that don't change much or servers with highly unique and, therefore, time-consuming configurations. You may need to shift this approach for dynamic servers like database servers, but you still can use a recovery disc to reduce recovery time. In this case, build the server, install and configure the database engine (for example, MySQL) without any databases and capture it. Then, if you need to go back to the recovery image, the only additional step needed for full recovery is to restore the database onto the newly restored OS. For my test scenario, I used a DNS server running on CentOS 5.5 as my critical system.
To get started, download the Clonezilla Live .iso file from SourceForge and burn it to a CD. Place the Clonezilla Live CD in your system and boot from it (Figure 5). At the boot menu, accept the default option for Clonezilla Live. When prompted, accept the same Clonezilla options previously selected for capturing an image (Start Clonezilla, device-image and so on), and when prompted for a mountpoint for /home/partimag, select somewhere other than the local disk you want to clone. I used a USB hard drive, so I selected the local_dev option. Leave the defaults on the option “Select the top directory to store the image file” to store it on the root of your chosen storage device. Complete the selections using the same options chosen earlier for capturing an image. When the clone process is finished, return to the console by pressing Enter and selecting “(3) Start over”.

Figure 5. The Clonezilla Live Boot Screen
With your image captured, you now can build the recovery disc. Select the same options as above to start Clonezilla (device-image, local-dev, mount USB as /home/partimag), but then select Beginner Mode and “recovery-iso-zip Create_recovery_Clonezilla_Live” (Figure 6). Select the image that was just captured as the image to restore, and confirm that the destination device to be restored matches the mount label of the critical system (that is, sda, hda1). Leave the language and keymap options the defaults. Select .iso as the recovery file type. If prompted that the target .iso file is too large to fit on a CD, answer yes to create the file anyway. Clonezilla will start building the .iso file in the root of the USB drive and include the captured image in the .iso image (Figure 7). At the end of the process, power off the machine using the prompts. Burn the resulting .iso from the USB hard drive to a CD or DVD depending on the size.
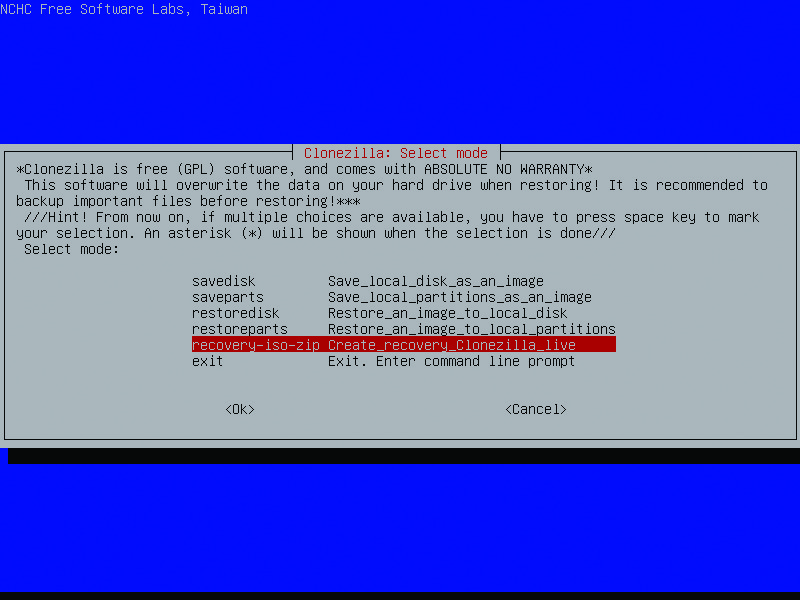
Figure 6. Selecting the Recovery Mode Option in Clonezilla Live
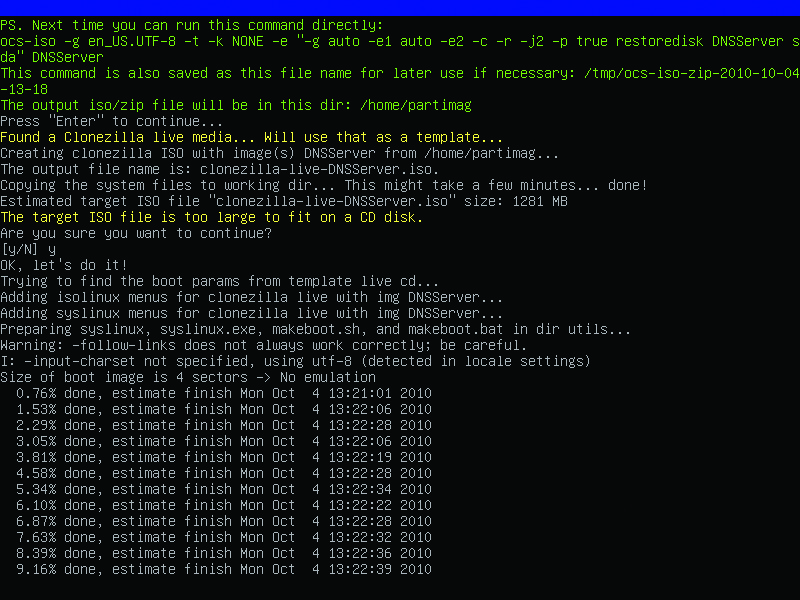
Figure 7. Creating the .iso File
To test the recovery disc, boot from it and select the default option from the bootloader screen, which will default to “Clonezilla Live” with the name of your img file (Figure 8). The recovery disc then will bypass the usual Clonezilla selection screens, immediately launch the appropriate cloning program and ask for confirmation to overwrite your drive with the image on the disc (Figure 9). If all went well, you now have a good copy of your system to use in case of emergency.

Figure 8. The Recovery Disc Boot Screen (with Image Name)

Figure 9. Restoring the Recovery Image
In this article, I've walked through the two most popular uses for Clonezilla, but they are by no means the only ones. One emerging trend is using Clonezilla to capture images of physical systems for redeployment on virtual servers—a process known as physical-to-virtual conversion (P2V). Others have combined Clonezilla Live with the popular System Rescue CD and built a powerful rescue CD called Clonezilla-SysRescCD. There are a multitude of uses for the suite and its components, but for all its utility, Clonezilla does lack some of the nicer features found in the commercial cloning suites. Those missing features include the ability to clone a running system, take differential (delta) images and restore to dissimilar hardware or “bare-metal” restores. Still, those features come at a premium and are not always easy to implement. In the end, Clonezilla is a common-sense tool that does its job well for all types of systems—not just those that don't end in *nix.
Resources
CentOS: www.centos.org
DRBL: drbl.sourceforge.net
Clonezilla SE and Live: clonezilla.org
GParted: gparted.sourceforge.net
GParted Live: gparted.sourceforge.net/livecd.php
PartedMagic: partedmagic.com
Clonezilla-SysRescCD: clonezilla-sysresccd.hellug.gr
Migrate to a Virtual Linux Environment with Clonezilla: www.ibm.com/developerworks/linux/library/l-clonezilla
Jeramiah Bowling has been a systems administrator and network engineer for more than ten years. He works for a regional accounting and auditing firm in Hunt Valley, Maryland, and holds numerous industry certifications, including the CISSP. Your comments are welcome at jb50c@yahoo.com.

