
New Projects - Fresh from the Labs
Fans of musical tracking programs, such as Fasttracker, ProTracker, CheeseTracker and the like, will want to check out MilkyTracker, which has been quite popular on SourceForge and has had pretty widespread distro integration of late. To quote MilkyTracker's documentation:
MilkyTracker is an open-source, multiplatform music application, more specifically, part of the tracker family. It attempts to re-create the module replay and user experience of the popular DOS application Fasttracker II, with special playback modes available for improved Amiga ProTracker 2.x/3.x compatibility.
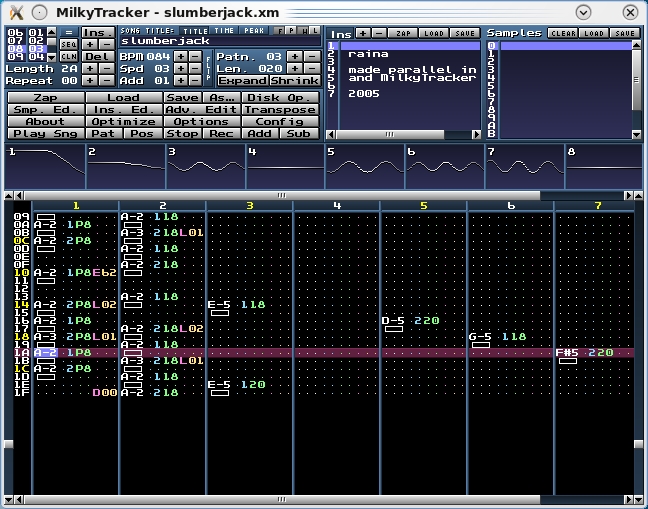
MilkyTracker provides all the old-school, low-level control from ye olde days of music tracking.
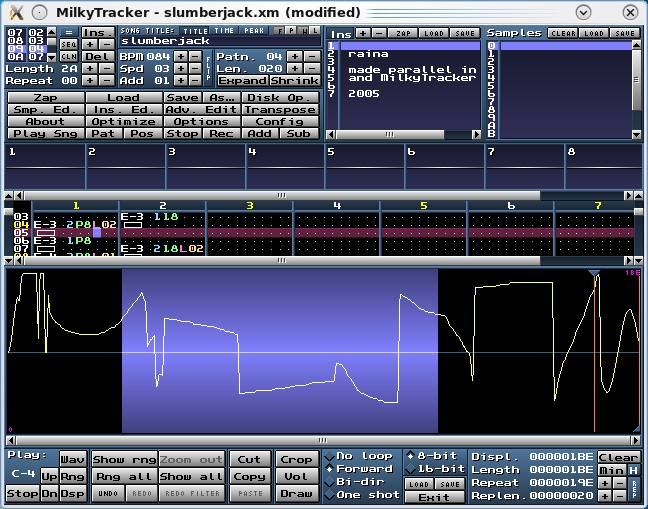
You don't get much more hard core than waveforms drawn by hand!
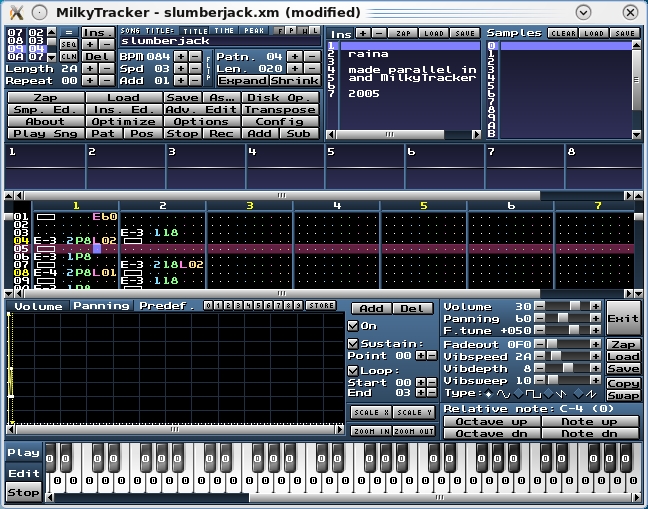
Thankfully, a keyboard-based instrument editor is included as well.
Installation
When it comes to installation methods, you are pretty spoiled for choice. Along with the usual source tarball, packages in various repositories are available for Ubuntu, Arch Linux, Debian, Enlisy, Gentoo and SUSE, as well packages for our FreeBSD and OpenBSD cousins. Ubuntu users are doubly spoiled with a binary tarball built upon Karmic.
For those who are running with source, according to the documentation, MilkyTracker can be compiled using the standard ./configure; make; make install (note that make install requires the use of root or sudo). However, I ran into compilation problems during the “make”. I hope you have more luck. I went with the binary tarball in the end, which ran with no problems.
As far as libraries go, there shouldn't be too much in the way of strange requirements, although I did need to install libzzip-dev and libsdl1.2-dev to get past the source code's configure script.
Once your installation has finished, run MilkyTracker with:
$ milkytracker
Usage
The first thing I recommend doing is loading some of the provided songs, which instantly will show off MilkyTracker's capabilities. Click the Load button in the cluster of gray buttons near the top left of the screen, navigate to the directory in which MilkyTracker has been installed, and look at the songs directory. Choose one of the available tracks and click Play Song on the bottom-left corner of the main cluster of gray buttons. My personal favorite (or at least the most credible of these tracks—demonstration songs are always pretty dry) is “slumberjack”, which is nice and progressive and shows off MilkyTracker's capabilities quite nicely.
As the track plays, you'll see a bar move rapidly down the main composition screen's page and move on to other pages of music as the song progresses into new movements. A welcome feature from classic tracker programs is the wave visualization inside those windows in the middle section. They give individual readouts for each channel. It's pretty cool to watch this multitasking in progress and see the music's very DNA scroll before your eyes.
I also noticed a very willing use of the stereo spectrum in this program, which helped to add spice. That said, my favorite part of this project is the sample editor, which lets you manipulate waveforms by hand. It also lets you literally draw your own waveforms—effectively making something from nothing.
However, none of this stuff will come as a surprise to tracker veterans, who've grown up with such hard-core features since the days of DOS. Newbies who are used to soft-core programs like FruityLoops will freak out in this imposing retro environment. Veterans probably will rejoice in the imposing low-level interface and go back to skulking around in their basements listening to Kraftwerk and Wumpscut.
Ultimately, MilkyTracker provides an authentic environment for those who have grown up with these programs, while adding more modern capabilities and platform diversity. I personally find these programs way too daunting, but old-school Tracker fans are going to love it.
Before I begin, there's been some recent controversy over this project, with the accusation that this project is ripping off someone else's work. Playdeb.net was sent the following message from the Senile Team:
It may interest you to know that Paintown “borrows” original work from Senile Team without permission. To put it more bluntly, Paintown is a rip-off from Beats of Rage (see www.senileteam.com/beatsofrage.html).
The source code and assets for Beats of Rage are freely available, and may be used by anyone—provided of course that they give proper credit. The author of Paintown, however, has openly refused to do so, and Paintown should, therefore, be considered in violation of copyrights.
The author of Paintown has on several occasions been confronted with the impossible similarities between “his” game and Beats of Rage. However, rather than admitting to the obvious, he instead decided to alter some of “his” code and assets in order to hide their true origin. And yet even now, the screenshot seen on your site immediately betrays Paintown as a rip-off, containing several custom graphics that were made by Senile Team.
I had already written this month's piece when I received this information, and Playdeb.net took down the package (although things may change by the time this article is printed). However, I feel it's best to pass on this information and let you decide for yourself.
This is not my genre of gaming and I'm far from an expert, but this project instantly caught my attention and seems to have a great deal of potential. To quote the Web site:
Paintown is a 2-D engine for fighting games. If you are looking for a side-scrolling, action-packed game like you used to play, or if you are looking for an extensible engine to write your own game, look no further. Paintown supports user-created content through a mod system and user-defined functionality through scripting.
Paintown also supports an implementation of M.U.G.E.N. Our goal is to be 100% compatible with M.U.G.E.N 2002.04.14 beta as well as supporting any new updates in the 1.0 version.
Paintown is completely open source, and we would love any contributions in the form of code, art or donations. Give Paintown a try!
Paintown has the following features, according to the Web site: low CPU and GPU requirements, network play, dynamic lighting, joystick support, mod/s3m/xm/it music modules, scripting with Python and the M.U.G.E.N engine.
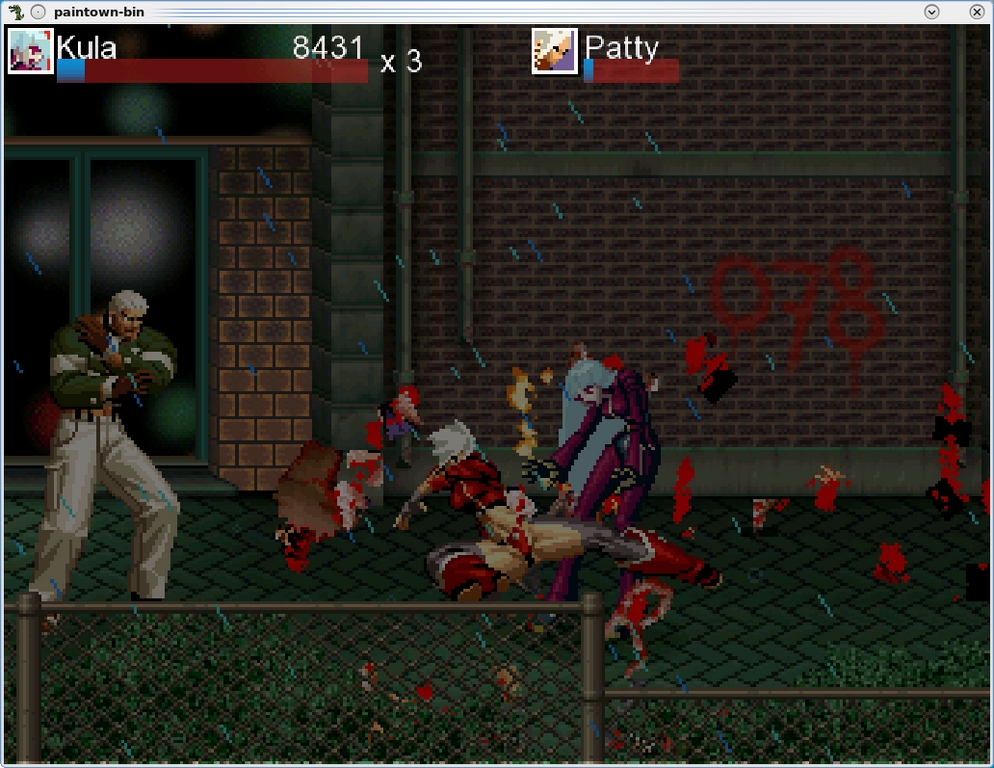
Paintown can be a bit intense, with lots of giblets, spinal cord and whatnot. Don't tell Mum though.

How many commercial games would let you team up Donatello with Wolverine, eh?
Installation and Usage
At the Web site, a source tarball was (supposedly) available, but I ran into some trouble with it. The Web site link wasn't working at the time of this writing, and it gave an error. However, the link from the project's Freshmeat page was working fine. I'll leave the rest of the installation details to you on this one, as things seem to be a bit up in the air with this particular project.
Inside the game, things are fairly intuitive, but documentation for some of the finer details is lacking, so please forgive me if I make some dumb errors. There are three main components: Adventure Mode, Adventure Mode with Computer and M.U.G.E.N mode. Adventure Mode puts you in a sideways-scrolling street-brawl game, with changing scenery and characters in the style of Final Fight, Double Dragon and so on. Adventure Mode with Computer adds a computer-controlled Player 2, and you can assign a different character to each player.
The beauty of a noncommercial game such as this is that fans generally add their favorite characters from other games, and here you can choose from such characters as Ryu and Blanka from Street Fighter, Goku from Dragon Ball and even the time-honored Wolverine!
Each character has different strengths and weaknesses, and Attack buttons vary between them all. Nevertheless, there are similarities between most characters: Attack 1 usually is punch, Attack 2 is a kick, and Attack 3 generally grabs an opponent. A character may have only one Attack button in use, but that Attack will be particularly devastating. Or, all three Attack buttons will be used, but with less power in each, although a more even spread.
Now let's look at M.U.G.E.N mode. For those not in the know, M.U.G.E.N was a 2-D fighting game built around customization, creating characters, background stages and so on. It spawned a community all its own with versions for DOS, Windows and, thankfully, Linux. These communities still are running strongly today with extraordinarily dedicated projects, such as the Infinity M.U.G.E.N Team's highly ambitious Marvel vs. Capcom, which is an entire gig's download!
As for Paintown's M.U.G.E.N game, it's very basic and rudimentary, with only one character from which to choose and fight against, with some joking cutscenes before and after playtime. Promisingly enough, it does have a training mode, as seen in the later years of this genre, so I look forward to seeing how things progress, given the attention to detail. Unfortunately, I'm out of space, so I can't really give it the coverage it deserves. I also didn't get a chance to look at the multiplayer networking side of things, but I'm sure it will make office lunch hours a good laugh!
Although this is not really my genre, and I'm not comfortable with advocating violent video games, I'd be remiss in my duties to not report on it due to my own biases. The open framework of this project is marvelous, and its integration of M.U.G.E.N is all the better, which should breathe life into a genre that's mostly been abandoned by mainstream commercial gaming. Plus, the noncommercial aspect allows fans to live out their gaming character fantasies that commercial licensing would simply not allow.
Brewing something fresh, innovative, or mind-bending? Send e-mail to newprojects@linuxjournal.com.
John Knight is a 25-year-old, drumming- and climbing-obsessed maniac from the world's most isolated city—Perth, Western Australia. He can usually be found either buried in an Audacity screen or thrashing a kick-drum beyond recognition.
