
The Challenges of Open Source in the Enterprise
There is an old Chinese curse, “may you live in interesting times.” Of course, we all want to live in interesting times, but sometimes the interesting part can be a bit much. The enterprise is an interesting place. On the one hand, real enterprises have technology budgets that are quite large, sometimes even running into billions of dollars. Much of that budget is for labour, meaning that a successful enterprise technology person can make very good money, while learning a lot on the way. Although your typical tech shop may have a few servers and program in, say, Ruby, with an HTML front end backed by MySQL, in an enterprise, you are likely to encounter, and learn, every technology out there. If you like Ruby, it is there; Java, most certainly; .NET, that too. If your preferences run to infrastructure, you are likely to find everything from Windows servers to Linux to UNIX variants to mainframes to the unexpected. As recently as 2001, I worked as head of enterprise management at a place that had a massive farm of DOS 3.1 PCs; those were “interesting times”.
On the other hand, enterprises don't start or end with cool technology, and they are there to serve a business purpose. The most famous illustration of this is the Nine-Layer OSI Model by the legendary Evi Nemeth.
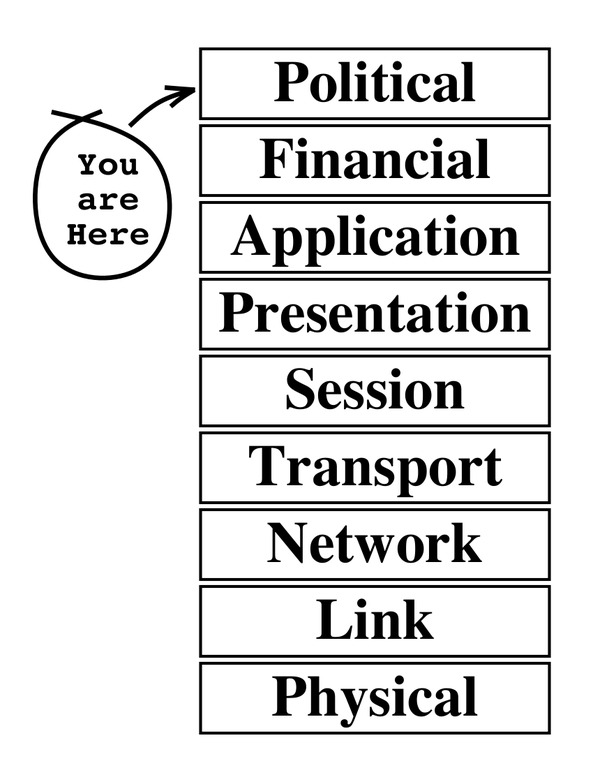
Figure 1. The Nine-Layer OSI Model, Courtesy of and Reprinted with Permission of Evi Nemeth
Sure, you may have the best solution to a problem, but in an enterprise, you need to get the budget approved—on a multiyear cycle, of course—and then you likely need to go before some sort of capital expenditure (CapEx) or major expenditure review (MER) committee. Everyone there views your request as competing with their priorities for 1) budget allocation, because even a $1-billion IT budget is still finite, and 2) recognition and promotion, because after all, they want you to succeed, but they want their own projects to succeed even more. Finally, enterprises have legitimate business support needs that may or may not be resolved by your open-source solution.
At base, everyone interested in open source is interested in technology, so let's address the technical challenges first. As you may have noticed, enterprises spend a lot of money. Unsurprisingly, to quote Willie Sutton who used to rob banks because “that's where the money is”, many commercial technology businesses build products to focus primarily on the enterprise and solve its unique problems, and they have very large sales and marketing budgets to sell them. On the other hand, open-source products often are built, at least initially, to solve very specific problems.
Thus, before advocating for open source, we need to understand if the open-source solution solves the problem as well as the commercial solution, given the entire requirements set. This includes not just the immediate technical problem, such as “serve up a Web page”, but also the management challenges that can be unique to an enterprise, such as “replicate in real-time across 15 databases in ten countries around the world, while instantly alerting to any degradation and providing service-level agreement (SLA) reporting”. In many cases, open source has indeed developed to the point where it truly can compete on a technical requirements level with commercial products. In other cases, it is not yet sufficiently evolved, but it may be some day. And in some cases, it is literally impossible to solve the problem with open source. Let's examine two extreme examples.
Web servers: the dominant Web server for many years, of course, has been Apache. Although various competitors nip at its feet, such as IIS for Windows or nginx for sheer performance, Apache remains dominant for both intranet and Internet Web serving. In 2010, it is not hard to make the argument to adopt Apache for a Web server solution in the enterprise. It is mature, established, lots of well-known companies bet the business on it, and it has the various controls, hooks, logging and security that an enterprise demands. It is important to remember, however, that only a few years ago, Apache was not sufficient, and other commercial variants arose to fill in the gap, such as Apache Stronghold. The combination of a mature product, a complete enterprise-ready feature set and broad enterprise adoption make open-source Apache a selection as valid as any commercial solution.
Network infrastructure: in the old days, when we had to decide whether to route mail via UUCP or SMTP, we built our own firewalls. Routers simply were dedicated servers with multiple network interface cards (NICs) on which we ran software to route the traffic. Over time, however, the proliferation of networks and the demand for traffic-routing capacity and intelligent control exceeded the capabilities of these homegrown solutions. Special companies were formed to create specialized networking hardware. The most famous, of course, is Cisco. Although a small organization can make do with a simple router, or even a dedicated box with a few NIC cards running m0n0wall, such a solution is highly unlikely to work in a large enterprise. There, the complexity, traffic demands and management requirements, as well as a three-tier architecture (core, distribution and access layers) can be done far more cost effectively, and in some cases, only with a hardware solution. Clearly, open source is not about to run enterprise networks. Having said that, it is not impossible that a split could occur. Currently, enterprise network equipment manufacturers provide both the hardware and software to manage routing, some of which may be based on open source, such as Cisco ASA 8.x. It is possible that in the near future, a pure-hardware networking equipment manufacturer could be formed that would sell the hardware only, while software is provided via an open-source solution, in a manner similar to current servers.
The important takeaway from evaluating any technology is that it has to solve the immediate problem, such as serving Web pages, but also have the features required for an enterprise, such as management, logging and security. Rarely does it matter that the open-source product may be better or that you want to support the community that brought us Linux/Apache/whatever. For adoption in the enterprise, the rule remains, as it should anywhere, first solve the actual problem and everything related it.
In addition to solving technical problems, some of which are specific to an enterprise, there are unique enterprise business requirements as well. In a small IT environment or Web startup, no one wants a problem or outage any more than in an enterprise. However, the technical tolerance may be greater in a smaller environment, and it often is acceptable that the trade-offs require the lone in-house expert (that would be you) to “take care of the problem” in an emergency; often that is the actual crisis plan. In an enterprise, with postmortems, roles and responsibilities, and sometimes “pin the blame on the donkey”, a support plan of “I will deal with it and work with on-line fora when it breaks” will not go over very well. The cost of error or failure is at least proportional and often even exponential to the size of the IT budget.
These challenges create a minor requirement known as a service-level agreement (SLA). IT promises its customers, whether internal or external, certain service levels. In order to meet those levels, there needs to be a predictable and reliable point of service for every element of technology. For HP servers, there is a service contract and spares; for routers, it is Cisco support or a partner; for open source, it is ... ? In many cases, the product is stable enough or distributed enough not to matter. In other cases, it matters greatly. “If it breaks, who will fix it?” is likely the number one question CIOs will ask. They are not being difficult; they simply are doing their jobs, determining whether they can meet SLAs and what will be the true fully loaded cost of your open-source adventure.
In that respect, one of the more interesting business ideas in the last decade is Red Hat. Its products are almost entirely open-source products that can be downloaded for free from elsewhere. However, it sells versions with full support. Essentially, Red Hat has decoupled product development from product support. There is nothing particularly special about Sun that allows it and only it to support Solaris (at least since Solaris was made open source). Anyone with sufficient expertise can do so. Recognizing that truth is the key to providing support for open-source products, exactly as Red Hat has done for Linux. It sold more than a half-billion dollars in support subscriptions in 2009 for products that it, by and large, did not develop.
Politics is the bane of every technologist's existence. Politics is about the subtle art of power interplays, personalities and compromise. Technology, on the other hand, is about science, the truth and the correct way. For a technologist, proving your point through tests and scientific answers is the right way to go, but this path only antagonizes outsiders. For politics does not care about the right answer, but about the one that meets people's needs, rational and emotional. The solution may very well not be the best one. It may not even really solve the technical problem, but it is the one adopted nonetheless.
Around six years ago, I was exploring solutions to a particular problem at a very large enterprise (around 100,000 employees). There were several solutions, but the one I was advocating was open source. The other leading candidate was proprietary. I had a very good relationship with the firm's attorney, with whom I discussed the issue. “Let's say the product fails spectacularly”, she said, “and we lose $10MM in business because of it, who do we come after? Who do we blame?” From her perspective, an attorney who is focused on the firm's legal needs, this is a perfectly valid reason to go for closed source, backed by a large company. From my perspective, I far preferred to go with the solution that would not only cost far less, but also would provide better performance, thus reducing the probability and expected cost of failure, let alone spectacular failure.
As an aside, it is also important to note that my perspective could be difficult for her politically. If we focus solely on reducing the probability and expected cost of failure, and accept damages due to failure as an unfortunate cost of doing business, then the legal department's value is concomitantly reduced. If she has any influence over the final decision, and she did, these issues, seemingly irrelevant to most technologists, must be taken into account. In this case, I actually did win her over by pointing to the End-User License Agreement (EULA). Like most such EULAs, there was a very strong limitation of liability. For example, if you read the EULA to Microsoft Windows XP Professional Edition, it clearly states that your Exclusive Remedy is limited to either replacement of the defective software or possibly refund of the cost of the software itself. If $10,000 in software causes $10MM in damage, the most you can get back is $10,000 (maybe). I pointed out that the legal department had already been rendered irrelevant for this software, and not by me. Thus, the choice of solution would neither reduce their position, nor strengthen someone (me) who had reduced that positioning already.
Politics is the art of recognizing who wins and who loses with each decision. Understand the relationships, the power plays, who has the backing of the vendor you are explicitly discarding, who controls the budgets, and you will be in a better position to pick your battles and win them.
Open source has had huge amounts of successful adoption in the enterprise: Linux, Apache, Xen, Perl, PHP, Java and the list goes on. Open source also has had failures, either failure to launch (where it does not get adopted) or explosion on the launchpad (where it is adopted and fails). When looking to adopt an open-source solution in an enterprise, it is important to remember the entire nine-layer model and answer three questions:
Does it meet all of the technical requirements, including those that are unique to running any technology in an enterprise?
Does it have sufficient support and maturity to meet the business requirements of the enterprise?
Can I move it through the process while taking into account the politics inherent in any enterprise?
If the answer to all three is positive, you have a good situation for promoting adoption of an open-source solution.
Resources
Evi Nemeth: www.cs.colorado.edu/~evi
Nine-Layer Model T-Shirt: https://www.isc.org/node/232
Microsoft Windows XP Pro EULA: www.microsoft.com/windowsxp/eula/pro.mspx
Cisco: www.cisco.com
m0n0wall: m0n0.ch
Red Hat: www.redhat.com
Avi Deitcher is an operations and technology consultant based in New York and Israel who has been involved in technology since the days of the Z80 and Apple II, and he has worked with global enterprises through tiny Web startups. He has a BS Electrical Engineering from Columbia University and an MBA from Duke University. He can be reached at avi@atomicinc.com.

