
Review of Scilab
When I first installed Linux, I was delighted to find that f2c (with the shell programs f77 or fort77) made FORTRAN coding possible and almost transparent, despite the lack of a FORTRAN compiler. But, after trying a number of publicly available graphics programs, I was unsatisfied with plots of my FORTRAN results. Also, I missed the mathematical power of such programs as MATLAB, which I also (and primarily) use for its great graphics. Then I tried scilab, which was released recently for Unix and Linux by INRIA (Institut National de Recherche de Informatique et en Automatique) of France. Although the graphics aren't as good as MATLAB's, scilab did solve most of my problems; so much so, that I installed it on my workstation at work as well.
Scilab is a fully featured scientific package, with hundreds of built-in functions for matrix manipulation, signal processing (complete with its own toolbox), Fourier transforms, plotting, etc. It is based on the use of matrices, which means that, with proper planning, you don't need to use subscripted variables in your programs. Scilab has voluminous help files, documentation and demo programs. Here, I will just outline some of what it can do. There is just too much to cover in one article.
The documentation you will need is found in directories under the main directory scilab-2.0. In doc/intro, the compressed PostScript file intro.ps contains the user's manual, Introduction to Scilab. This you will need for sure. In man/LaTeX-doc is Docu.ps, which contains a list of all the scilab functions. This is not really necessary as all of it is available on line via the help command or the help button on the scilab front end. The Signal Processing Toolbox manual in doc/signal shows examples of IIR and FIR filters, spectral analysis, and Kalman filtering.
As a direct descendent of MATLAB, its syntax is similar. For example, to define a vector x, we can type at scilab's --> prompt:
-->x=[ 1 3 5 8]
which is echoed back as:
x = ! 1. 3. 5. 8. !
(exclamation points denote a vector or matrix).
Matrix multiplications are trivial:
--> z=[ 7 8 9 10]; --> x * z' ans = 156. -->x.*z ans = ! 7. 24. 45. 80. !
The first multiplication was the row vector x multiplied by the column vector z' (created by a transpose of the row vector z using the prime operator). This yields the single number 156. The second multiplication with the .* operator is an element by element multiply, resulting in a vector.
Solutions of matrix equations of the form a x = b are also simple. For example, let's define the 3x3 coefficient matrix a:
--> a=[2 1 3; 5 -3 1; 4 4 2] a = ! 2. 1. 3. ! ! 5. -3. 1. ! ! 4. 4. 2. !
For b=[1 29 -14]', a column vector (using the prime operator), we can find x several ways:
--> x=a\b x = ! 2. ! ! -6. ! ! 1. !
or alternatively x=inv(a)*b, where inv(a) produces the inverse of the matrix a.
To find and plot the sin(2PI x/25) for 1<x<7lt;100, first generate the sequence of numbers—x ranging from 1 to 100, counting by 1,
-->x=[1:100];
where the semi-colon is used to stop scilab from echoing back the numbers. To find the sine of all the numbers at once:
-->y=sin(2*%pi*x/25);
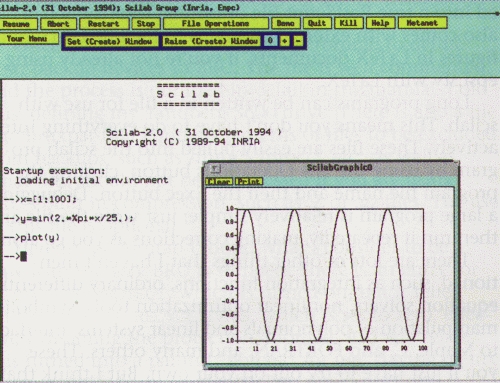
where %pi is the scilab intrinsic value for PI, and the vector y is the vector of the sines, with the first value y(1)=sin(2*%pi*1/25), the second as y(2)=sin(2*%pi*2/25), and so on. To see these values, we can plot them with plot(y), as shown in Figure 1, which shows the scilab front-end along with the separate x-window plot that was generated automatically by scilab superimposed.
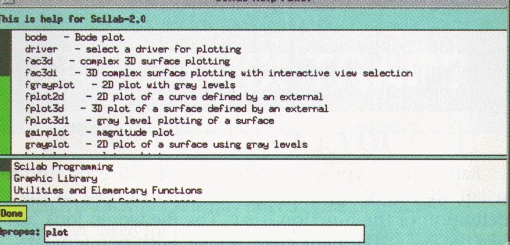
Help is available several different ways. Typing help at the scilab prompt, followed by a function name, will produce a window with the help text for that function. Or use the help button in the main window (shown in Figure 1) to create the Scilab Help Panel (shown in Figure 2). This method allows a search of the help files with the apropos command, shown here with a search for the keyword plot. There are 10 entries shown in the figure of the 28 available for plot. With a single click on fplot3d, an xless window pops open with detailed information on the use and the arguments of the function (shown in Figure 3).
One problem I solve often is s=x tanh(x) for x when s is given. It comes up in the problem of determining the length of a water wave of a given frequency in a known water depth. Since x appears in the argument of the hyperbolic tangent function, this is not an easy problem to solve, requiring an iterative solution method. Instead of writing a Newton-Raphson scheme as I do in FORTRAN, I use the fsolve function, which finds the zero of a system of nonlinear functions. First, let's find x given a single value of s.
-->s=.5
I then define the remainder, r = s-x*tanh(x), which should be zero for the correct value of x.
-->deff(`[r]=g(x)','r=s-x.*tanh(x)')
The deff function defines g(x), with single quotes about each part. Now to fsolve:
-->x=fsolve(.3,g)
x =
.7717023
The value 0.3 is my initial guess at the answer. Let's check the answer by substituting it back into g(x):
-->r=g(x) r = - 1.110E-16
Our solution is good. If we had defined s as [0.1 0.2 0.3] and used x=fsolve(s,g), we would get three solutions at once. (That's why I used .* instead of * in the definition of r(x).)
Rather than typing the definition of g directly into to scilab, we can define a file—wvnum, for example, as the definition of the function g(x). The file would look just like the deff argument given above, with two separate lines, but without the single quotes. We then call the definition into scilab with getf(`wvnum'). This can also be done through the File Operations button.
We can assure ourselves that there is only one positive solution for x by plotting g(x), say, in the range from 0 to 5 by steps of 0.1:
-->fplot2d((0:.1:5),g)
fplot2d has the advantage over the plot function of specifying the range of the abscissa and plotting a function instead of a list of numbers. (Note there is a minor error in the help file example—reversing the arguments of fplot2d. This is one of the mistakes I have found. The worst was an error in scilab's attempt to convert a function definition into FORTRAN code. Be careful.)
Scilab has a variety of other plotting functions available. Histograms, contour plots, 3d plots, and plots of vectors (useful for flow fields) are all available. I sometimes use scilab to plot data from another program. By saving the data in an ASCII file, with known numbers of rows and columns, the data is read into scilab by a read command: z=read(`datafile',m,n), where (m,n) are the numbers of rows and columns. Then the data can be contoured, for example, by contour(1:m,1:n,z,10) for 10 contour levels.
Plotting data in three dimensions is also straightforward. Using the z data from above, a similar call to plot3d(1:m,1:n,z,45,45) produces a 3D plot with a view point associated with the spherical coordinates 45 and 45 (in degrees). By setting the program to use color, xset("use color",1), then plot3d1 with the same arguments gives a color shaded plot. Looking through the demo program sources will show you how to animate this type of plot.
Printing figures is easy. One way is to simply use the Print button in the scilab graphic window. This sends the figure directly to your PostScript printer, if you have one. The same thing is accomplished with the command xbasimp(0,'foo.ps'), which outputs the contents of plotting window 0 to a PostScript printer (despite what the documentation says). Using xbasimp(0,'foo.ps',0) will instead make a file named foo.ps.0, which can be printed with an external scilab program called Blpr. The file foo.ps.0 is not quite a PostScript file, as a preamble translating scilab abbreviations is missing. Blpr adds that preamble producing a PostScript file that can be redirected into a true PostScript file or printed directly. Scilab also comes with external programs to include PostScript figures in LaTeX documents, if you're not already using epsf.sty with LaTeX.
Long programs can be written in a file for use with scilab. This means you don't have to do everything interactively. These files are easily pulled into the scilab program by using the File Operations button, clicking the program file name and then the Exec button. Debugging a large program is relatively simple; just write the file and then run it repeatedly, making corrections as you go along.
There are lots of other things that I haven't mentioned, such as integration functions, ordinary differential equation solvers, nonlinear optimization tools, symbolic manipulation of polynomials and linear systems, interfaces to Maple, C, and FORTRAN, and many others. These you'll just have to try out on your own. But I think that you will agree the effort is worth it and that scilab does bring mathematical clout to the Linux environment.
Robert A. Dalrymple teaches coastal engineering at the University of Delaware and directs the Center for Applied Coastal Research. He uses Linux at home and work and has more fun with it than he should, as he has other things he is supposed to do!


{kind=link}
{kind=link}
{kind=link}