
Virginia Power—Linux Hard at Work
I'm a programmer for Virginia Power, an electric utility that serves about two million customers in much of Virginia and a small part of Northeastern North Carolina. Virginia Power's service territory is partitioned into five divisions: Northern, Southern, Eastern, Western, and Central. Among the responsibilities of the Operations Services group in which I work is the maintenance of a centralized archive database of 30-minute averages of all analog values which are retrieved by SCADA master computers located in each division. This averaged data is of great importance to system planners and load forecasters, and is vital when planning large construction projects which may cost millions of dollars. Processing all of this data is a demanding task, but Linux has saved the day.
A few words of explanation for those of you who are not power system aficionados: SCADA is an acronym for Supervisory Control And Data Acquisition, which basically means the retrieval of real-time analog and status data from various locations in the service territory through remote terminal units (RTUs) installed in substations. This information is obtained over dedicated communications lines by central master computers, where it is stored, analyzed, and presented to operations personnel who make sure the lights stay on, and who get very busy when the lights aren't on. These system operators (as they're called) can also remotely operate field devices like line breakers and capacitor banks when necessary (this is the Supervisory Control part of SCADA); the master computers even contain several feedback algorithms which can automatically operate devices based on system conditions.
Virginia Power has another SCADA system which monitors the entire power grid and also provides automatic feedback control to the generation stations; this is called the Energy Management System, or EMS. And in case you're wondering: yes, the EMS retrieves analog values just like the division computers. Yes, we archive them into our central database. And yes, Linux has saved the day here as well.
Also scattered throughout the service territory are scores of intelligent electronic devices such as digital megawatt-hour meters, data recorders, fault detecting relays, and line tension monitors, which are not directly tied into the SCADA systems, but which must periodically be dialed into over the public phone network to obtain data for use not only by system operators, planners, and engineers, but by folks in the accounting department as well. You guessed it—Linux has saved the day in this area, too!
That should be enough background to get us started; now comes the scene as it existed when I joined the Operations Services group in late 1992:
Averaged analog data was dumped by the division SCADA computers every 15 minutes over dedicated serial lines to redundant PDP 11/84 computers located in our local computer room; these machines strained (and frequently failed) to process all the information being shovelled at them. Averaged analogs from the EMS system were dumped every 6 hours to a MicroVAX over a serial DECnet link which, due to internal security concerns, could only be activated when a transfer was to take place. Another computer, an IBM PS/2 model 60 running some of the most odious commercial software I have ever seen (which will remain nameless; it's not polite to insult the dead), slogged through dialing as many digital meters and recorders as possible, one at a time, over a single phone line.
Once a day in the early morning hours, all of the previous day's information from the PDPs, the MicroVAX, and the PS/2 was masticated in an orgy of sorting, calculating, merging, interpolating, and updating, and finally reduced to a set of 30-minute averages which were then shipped over DECnet to our main archive system (a VAX 4000) and merged into the master database. Whew! I was caught up in other projects at the time, but in my spare moments I looked into the scraps of code for this system—all I remember of those encounters are shudders, cold sweats, and endless nightmares of Fortran source.
Enter the first hero of our tale: Joel Fischer, engineer and technical evangelist extraordinaire, a believer in the true potential of microprocessor-based computers, and a Unix initiate—something of a rarity at a utility company. (Most companies, as I sure all of you know, develop a dominant computer philosophy which tends to color any approaches to a problem. At many utility companies, the official watchwords are often IBM Mainframes, VAXes running VMS, PCs running DOS or Windows or Novell. Very little TCP/IP. And very little Unix.)
Joel joined our group in early 1993. His primary responsibility was maintenance of the averaged analog database system. After a short time of dealing with balky PDPs, uncooperative PS/2s, and temperamental MicroVAXes, he began to share my conviction that there had to be a better way to process all of our incoming data.
And so began a series of productive and energizing “cubicle chats”. Joel would drop by my cubicle with some ideas on how to improve the system, and I would reciprocate with some ideas on his ideas, and so on. Our group is something of a skunk works anyhow, so this low-overhead approach to problem solving was a well-established principle. Joel was much more familiar than I with our company's network, and informed me of two important facts: Our enterprise backbone reached all division offices except the Western division, and all of our routers were native TCP/IP—despite the fact that TCP/IP wasn't used by more than a handful of special-purpose systems.
Well, well, well. By the most serendipitous of circumstances, I was at that same time looking into Linux on my home system, and I was impressed enough that I waxed somewhat evangelical myself. I had been the Minix and Coherent route, and I was no stranger to GNU and the FSF; we were running gcc and Emacs on our VAX 4000.
It had taken me exactly one evening at home to realize that Linux was a Good Thing. A few weeks of use and my software intuition (I'd like to think that 18 years of programming has been good for something) told me that Linux was a Very Good Thing Indeed. So I cleared off a disk partition on my machine at work and installed Linux, to demonstrate that it could do the things I claimed it could. Conversations with visitors to my cubicle followed this general pattern:
“Hey, what's that?”
“Linux, a copylefted Unix clone...” I gave a short speech on free software and the many advantages thereof. But you already know all of that.
“Huh? Will it do (fill in the blank)?”
“Sure.” Clickety-clack on the keys. “There you go.”
(And when I fired up X-windows—oh, my!)
Figure 1. AMC Dialing Subsystem
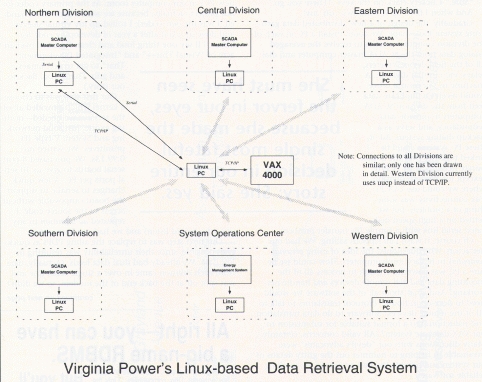
Gradually, the design of a new, distributed data gathering system took shape. We could install a PC in each of the division computer centers to receive the averaged analog data from the SCADA master computer and dial all of the field devices (meters, relays, etc.) in that division. A machine in our central office would receive a duplicate data feed from the division SCADA computers to provide data redundancy, and serve as a backup dialing system. All of these PC systems could be linked together over the corporate network with TCP/IP (except for Western division, where we could use UUCP). Vax connectivity was something of a problem, but we settled on a high-speed dedicated serial link with a simple file transfer protocol.
Of course, it wasn't all smooth sailing. We had our detractors, who questioned the idea of using personal computers to replace minicomputers. How could we be sure a PC was powerful enough to process all of the incoming data and dial remote devices and handle networking? And what about all of the software we would need to develop in-house? Protocol translators to talk to all of the remote devices? Software to do data translation and reduction into a format suitable for submission to our VAX database system? (All valid concerns, certainly. Many discussions with our “devil's advocates” were invaluable in helping to hammer out the gritty details of our system and provide the best answer of all: working, reliable software!)
Enter the second hero in our tale: Lynn Lough, our supervisor. She knew how important this data was to efficient company operations and planning, and she understood the need for a reliable, redundant retrieval system. Joel and I presented our proposed system. Hardware costs: the price of six 486/66 PCs with healthy doses of RAM and disk space. Software costs: zip. (Well, not exactly. Don't forget all of the in-house software we needed to develop. But you get the idea.)
We explained to her the underlying philosophies of the Free Software Foundation; how free did not always signify bad, but often meant better—because the software was not shoved out the door to meet some arbitrary marketing deadline, but was released in an environment of continual refinement and improvement, where hundreds of the sharpest software minds anywhere (that's you, folks!) would provide feedback. Besides, with all of the source code for everything, we would never be at the mercy of a vendor who decided to drop support for a particular piece of software, or who only fixed a bug by upgrading and charging a princely sum for the upgrade.
Lynn weighed all the pros and cons. She must have seen the fervor in our eyes, because she made the single most fateful decision in our entire story: She said yes.
Yow! Within weeks, by mid-August, we had 6 dandy new PCs in our computer room. As the primary coder for our project (actually, because we were a little short-handed, I was the only coder), I rolled up my virtual sleeves and dove in.
(And after a year of developing code for Linux, I'll say one thing loud and clear: I'd crawl over an acre of 'Visual This++' and 'Integrated Development That' to get to gcc, Emacs, and gdb. Thank you. Back to our story.)
Our first step was to choose a kernel which provided all of the services we needed—nothing exotic, just solid networking and System V-type IPC primitives. We settled on 0.99.13s. We purchased 8-port serial boards to give us 10 serial ports per PC. A few quick changes to serial.c to support the board (impossible without access to the source code, I repeated ad infinitum to anyone who would listen) and we had our base system. As soon as I have a breather, I'd like to post the patches for the serial board we're using: an Omega COMM-8 which provides individually-selectable IRQs for each port. In the meantime, please e-mail me if you're interested.
Our next step was to replace the ailing PDPs as quickly as possible, since their unreliability was resulting in lost data. We already had dual data feeds. (Actually, data from each division came in over a single serial line and was split off at the back end of the modem, so we didn't really have redundant data input; that was one of the weaknesses our system was designed to rectify.) We decided to take two of our PCs and temporarily configure them as plug-in replacements for the PDPs. To accomplish this, we had to be able to accept input data in its current form (for various reasons, the division master computers couldn't be changed to modify the way they sent the averaged data to us), reduce it to database input format, and move it to the database VAX.
I took the Unix toolkit philosophy to heart, and instead of a big blob program to do Absolutely Everything, I wrote a set of small utilities, each of which did one thing and one thing only. For run-time modifications I used small configuration text files, and for interprocess communications (where necessary) I used message queues.
Pretty soon, I had an input daemon that hung on the serial lines watching for data, a checker program that made sure we got our quarter-hour files in a timely fashion and verified the points they contained, an averager that calculated 30-minute average files, a builder that built a database submission file hourly, and a PC-to-VAX daemon that implemented a simple transfer protocol over a high-speed serial line. (Of course, this last program required a corresponding daemon on the VAX side, which meant a foray into VMS-land. Good thing I had gcc and Emacs over there!)
By the third week of October we were ready for a trial run. We halted one of the PDPs, moved the data input lines over to our PC, and booted Linux. Within 15 minutes, our next cycle of averaged data had been sent, and tucked safely away on our PC's hard drive were 5 of the most wonderful data files I had ever seen: an input file from each division, every byte present and accounted for. Within 30 minutes, we had our first calculated average file. Within an hour, we had our first database transfer file, neatly deposited in a spooling directory where eventually it would make its way to the VAX.
I didn't get much sleep that night. Logged in from home, I watched each data cycle come in with the sort of anticipation usually reserved for really good science fiction movies. Of course, I had tested all of this software beforehand, but seeing it work with real data in real time was more exciting than I care to admit.
After this milestone, events moved pretty quickly. By the beginning of November, the remaining PDP was relegated to backup status, and our PC was the primary data source for our archive database. By the end of the year, that PDP was gone as well; a second PC would serve as our backup machine while we installed our PCs in the division operating centers.
Over the next several months, as our PCs gradually migrated out to their permanent homes in the division SCADA master computer centers, I turned my efforts to meeting our intelligent device dialing needs—remember all of those megawatt-hour meters, data recorders, and so on requiring periodic polling? More code to develop—just my cup of tea!
To meet our current requirements, as well as provide for future dialing needs, I designed a general-purpose dialing system which could connect to just about any device with a modem and a byte oriented communications protocol. Requests to dial devices are posted to a message queue; a daemon process manages all the phone lines allocated to device dialing. When a request comes in on the message queue, the dial-up manager allocates a phone line, forks a copy of itself to handle the chores of dialing and connecting to the device, and once a connection is established, execs the appropriate protocol task to actually talk to the remote device. When the protocol process terminates, the parent dial-up manager recycles the available phone line for any further dial requests. If there are more dialing requests than available phone lines, the dial-up manager maintains an internal queue with all the usual timeouts, etc.
Figure 2. Linux-Based Data Retrieval System
This dial-up manager scheme should sound pretty familiar—it was inspired by the inetd superserver. Now what was that quote by Newton about standing on the shoulders of giants...?
I won't go into the fascinating and esoteric details of writing protocol tasks for the various devices we interrogate. So far, we've developed protocol tasks to talk to half a dozen different types of devices, with more on the way. At last count, our Linux PCs dial nearly a hundred separate devices on a regular basis.
Our story has pretty much reached the present day, and the sailing has gotten smoother and smoother. We've installed a TCP/IP stack on our VAX database machine, so connectivity with our Linux machines is easier than ever. We've installed a sixth remote Linux machine in our System Operations Center (that's the EMS system mentioned at the beginning of our tale) to take care of retrieving EMS averaged analogs, along with handling some dialing requirements for that department. And we're currently developing a virtual dial-up SCADA system to supplement our SCADA Master computers... But that's a topic for another article.
Our network of Linux systems has been handling round-the-clock data retrieval chores—processing about 12,000 data points every 15 minutes—for nearly a year, and not a single byte of data has been lost due to any system software problems! I can think of no better tribute to all the hard-working and immensely talented Linux developers than the simple fact that our systems purr contentedly hour after hour after hour, utterly reliable. By golly, I'm beginning to think Linux really is the best thing since sliced bread!
Although he began adulthood as a music composition major, Vance Petree soon found computers a more reliable means of obtaining groceries. He has been a programmer for Virginia Power for the past 15 years, and lives with his wife (a tapestry weaver—which is a lot like programming, only slower) and two conversant cats in a 70-year-old townhouse deep in the genteel stew of urban Richmond, VA. He can be reached via e-mail at vpetreeinfi.net.
Vance Petree (vpetreeinfi.net) Although he began adulthood as a music composition major, Vance soon found computers a more reliable means of obtaining groceries. He has been a programmer for Virginia Power for the past 15 years, and lives with his wife (a tapestry weaver—which is a lot like programming, only slower) and two conversant cats in a 70-year-old townhouse deep in the genteel stew of urban Richmond, VA.

{kind=link}
{kind=link}